 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHER: Human-like Reasoning and Reinforcement Learning for LLM Role-playing
Jan 29, 2026LLM role-playing, i.e., using LLMs to simulate specific personas, has emerged as a key capability in various applications, such as companionship, content creation, and digital games. While current models effectively capture character tones and knowledge, simulating the inner thoughts behind their behaviors remains a challenge. Towards cognitive simulation in LLM role-play, previous efforts mainly suffer from two deficiencies: data with high-quality reasoning traces, and reliable reward signals aligned with human preferences. In this paper, we propose HER, a unified framework for cognitive-level persona simulation. HER introduces dual-layer thinking, which distinguishes characters' first-person thinking from LLMs' third-person thinking. To bridge these gaps, we curate reasoning-augmented role-playing data via reverse engineering and construct human-aligned principles and reward models. Leveraging these resources, we train \method models based on Qwen3-32B via supervised and reinforcement learning. Extensive experiments validate the effectiveness of our approach. Notably, our models significantly outperform the Qwen3-32B baseline, achieving a 30.26 improvement on the CoSER benchmark and a 14.97 gain on the Minimax Role-Play Bench. Our datasets, principles, and models will be released to facilitate future research.
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Jun 16, 2025



We introduce MiniMax-M1, the world's first open-weight, large-scale hybrid-attention reasoning model. MiniMax-M1 is powered by a hybrid Mixture-of-Experts (MoE) architecture combined with a lightning attention mechanism. The model is developed based on our previous MiniMax-Text-01 model, which contains a total of 456 billion parameters with 45.9 billion parameters activated per token. The M1 model natively supports a context length of 1 million tokens, 8x the context size of DeepSeek R1. Furthermore, the lightning attention mechanism in MiniMax-M1 enables efficient scaling of test-time compute. These properties make M1 particularly suitable for complex tasks that require processing long inputs and thinking extensively. MiniMax-M1 is trained using large-scale reinforcement learning (RL) on diverse problems including sandbox-based, real-world software engineering environments. In addition to M1's inherent efficiency advantage for RL training, we propose CISPO, a novel RL algorithm to further enhance RL efficiency. CISPO clips importance sampling weights rather than token updates, outperforming other competitive RL variants. Combining hybrid-attention and CISPO enables MiniMax-M1's full RL training on 512 H800 GPUs to complete in only three weeks, with a rental cost of just $534,700. We release two versions of MiniMax-M1 models with 40K and 80K thinking budgets respectively, where the 40K model represents an intermediate phase of the 80K training. Experiments on standard benchmarks show that our models are comparable or superior to strong open-weight models such as the original DeepSeek-R1 and Qwen3-235B, with particular strengths in complex software engineering, tool utilization, and long-context tasks. We publicly release MiniMax-M1 at https://github.com/MiniMax-AI/MiniMax-M1.
MedMimic: Physician-Inspired Multimodal Fusion for Early Diagnosis of Fever of Unknown Origin
Feb 07, 2025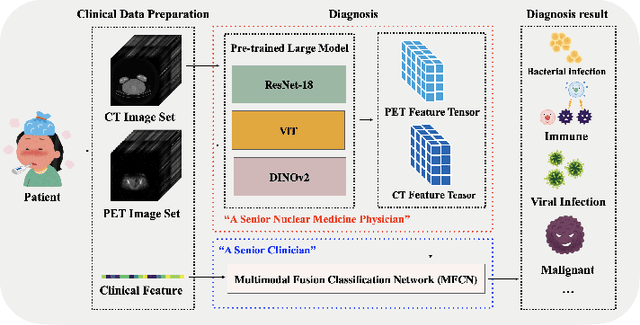
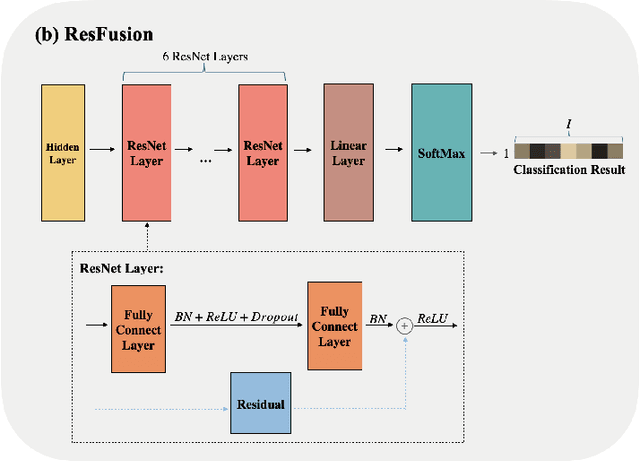
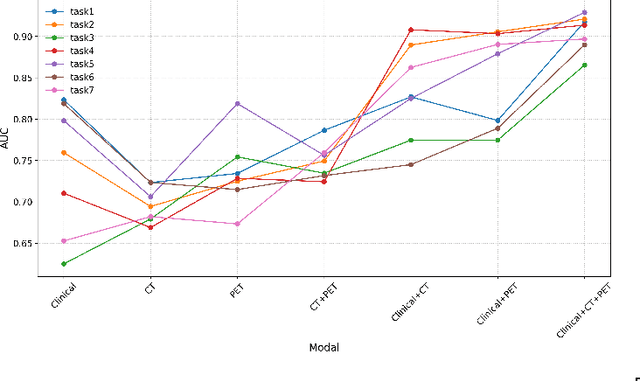
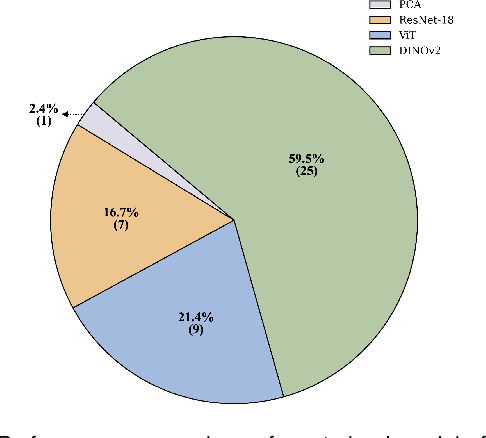
Fever of unknown origin FUO remains a diagnostic challenge. MedMimic is introduced as a multimodal framework inspired by real-world diagnostic processes. It uses pretrained models such as DINOv2, Vision Transformer, and ResNet-18 to convert high-dimensional 18F-FDG PET/CT imaging into low-dimensional, semantically meaningful features. A learnable self-attention-based fusion network then integrates these imaging features with clinical data for classification. Using 416 FUO patient cases from Sichuan University West China Hospital from 2017 to 2023, the multimodal fusion classification network MFCN achieved macro-AUROC scores ranging from 0.8654 to 0.9291 across seven tasks, outperforming conventional machine learning and single-modality deep learning methods. Ablation studies and five-fold cross-validation further validated its effectiveness. By combining the strengths of pretrained large models and deep learning, MedMimic offers a promising solution for disease classification.
TencentPretrain: A Scalable and Flexible Toolkit for Pre-training Models of Different Modalities
Dec 13, 2022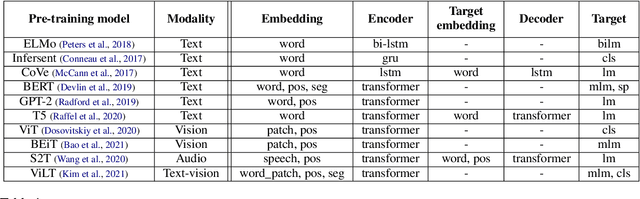
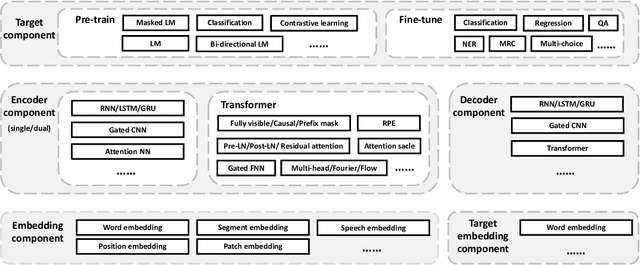
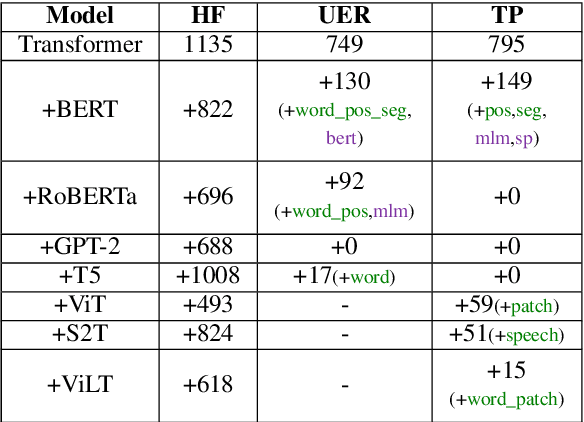
Recently, the success of pre-training in text domain has been fully extended to vision, audio, and cross-modal scenarios. The proposed pre-training models of different modalities are showing a rising trend of homogeneity in their model structures, which brings the opportunity to implement different pre-training models within a uniform framework. In this paper, we present TencentPretrain, a toolkit supporting pre-training models of different modalities. The core feature of TencentPretrain is the modular design. The toolkit uniformly divides pre-training models into 5 components: embedding, encoder, target embedding, decoder, and target. As almost all of common modules are provided in each component, users can choose the desired modules from different components to build a complete pre-training model. The modular design enables users to efficiently reproduce existing pre-training models or build brand-new one. We test the toolkit on text, vision, and audio benchmarks and show that it can match the performance of the original implementations.
A Simple and Effective Method to Improve Zero-Shot Cross-Lingual Transfer Learning
Oct 18, 2022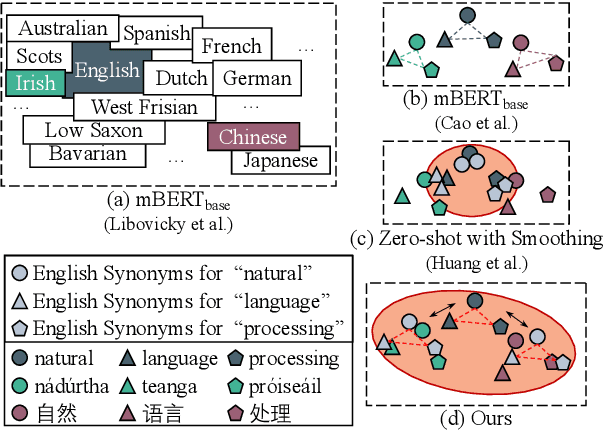
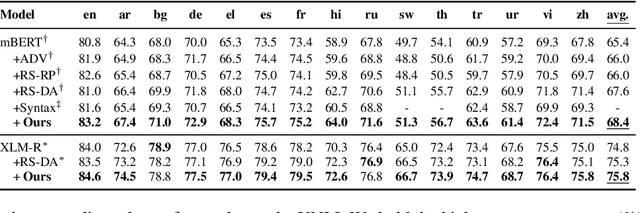
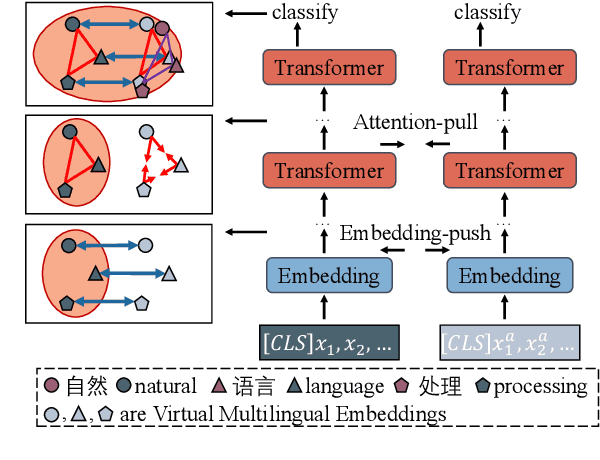
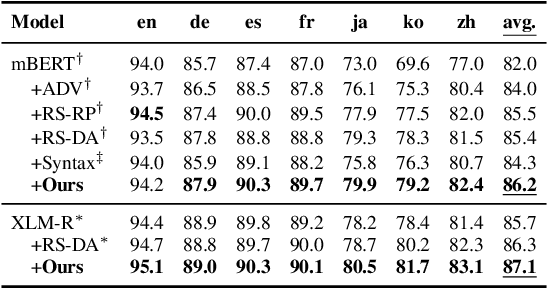
Existing zero-shot cross-lingual transfer methods rely on parallel corpora or bilingual dictionaries, which are expensive and impractical for low-resource languages. To disengage from these dependencies, researchers have explored training multilingual models on English-only resources and transferring them to low-resource languages. However, its effect is limited by the gap between embedding clusters of different languages. To address this issue, we propose Embedding-Push, Attention-Pull, and Robust targets to transfer English embeddings to virtual multilingual embeddings without semantic loss, thereby improving cross-lingual transferability. Experimental results on mBERT and XLM-R demonstrate that our method significantly outperforms previous works on the zero-shot cross-lingual text classification task and can obtain a better multilingual alignment.
SAMP: A Toolkit for Model Inference with Self-Adaptive Mixed-Precision
Sep 19, 2022
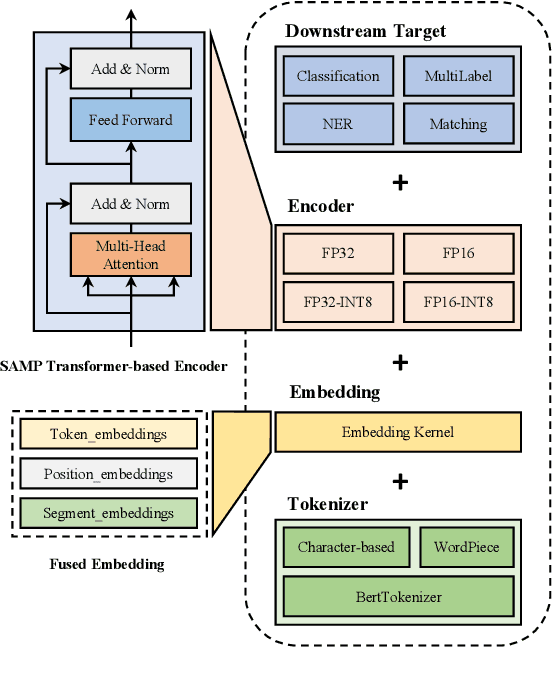
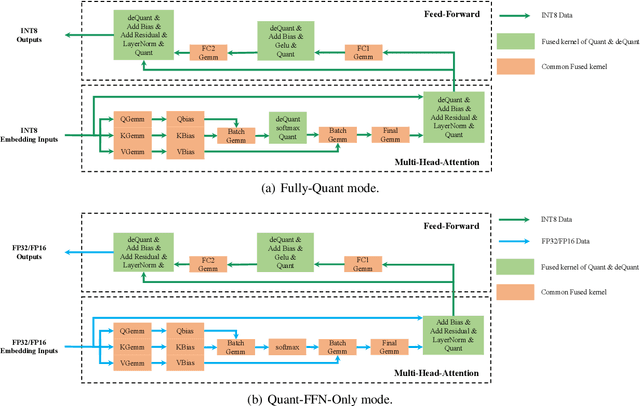
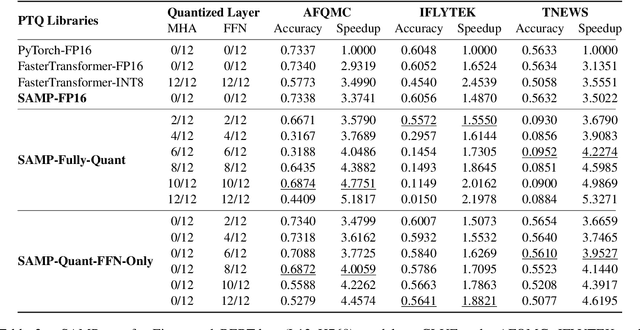
The latest industrial inference engines, such as FasterTransformer1 and TurboTransformers, have verified that half-precision floating point (FP16) and 8-bit integer (INT8) quantization can greatly improve model inference speed. However, the existing FP16 or INT8 quantization methods are too complicated, and improper usage will lead to performance damage greatly. In this paper, we develop a toolkit for users to easily quantize their models for inference, in which a Self-Adaptive Mixed-Precision (SAMP) is proposed to automatically control quantization rate by a mixed-precision architecture to balance efficiency and performance. Experimental results show that our SAMP toolkit has a higher speedup than PyTorch and FasterTransformer while ensuring the required performance. In addition, SAMP is based on a modular design, decoupling the tokenizer, embedding, encoder and target layers, which allows users to handle various downstream tasks and can be seamlessly integrated into PyTorch.