 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAMP: A Toolkit for Model Inference with Self-Adaptive Mixed-Precision
Paper and Code

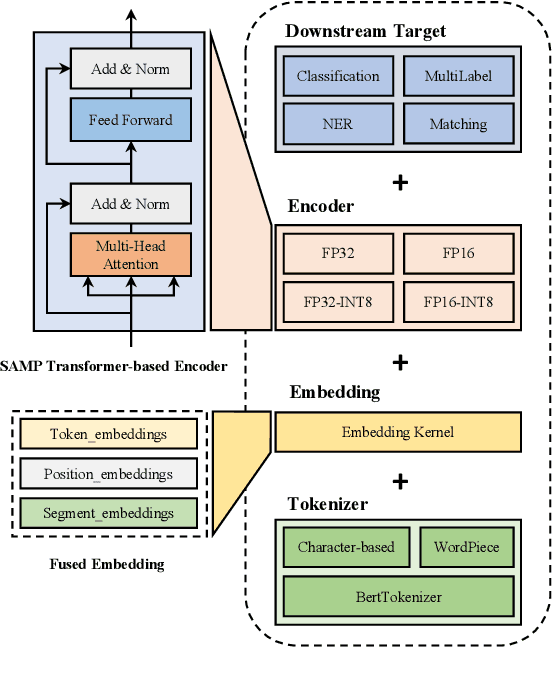
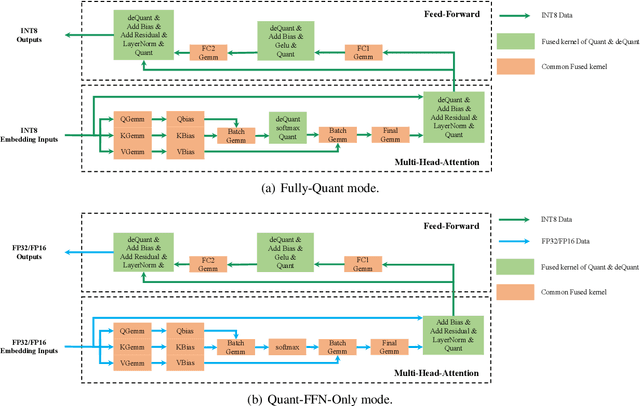
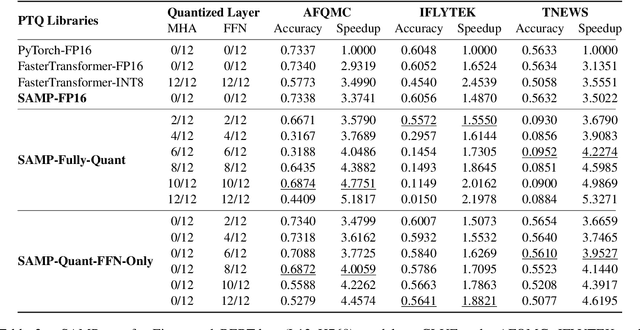
The latest industrial inference engines, such as FasterTransformer1 and TurboTransformers, have verified that half-precision floating point (FP16) and 8-bit integer (INT8) quantization can greatly improve model inference speed. However, the existing FP16 or INT8 quantization methods are too complicated, and improper usage will lead to performance damage greatly. In this paper, we develop a toolkit for users to easily quantize their models for inference, in which a Self-Adaptive Mixed-Precision (SAMP) is proposed to automatically control quantization rate by a mixed-precision architecture to balance efficiency and performance. Experimental results show that our SAMP toolkit has a higher speedup than PyTorch and FasterTransformer while ensuring the required performance. In addition, SAMP is based on a modular design, decoupling the tokenizer, embedding, encoder and target layers, which allows users to handle various downstream tasks and can be seamlessly integrated into PyTorch.