 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIGMark: Scalable In-Generation Watermark with Blind Extraction for Video Diffusion
Mar 03, 2026Artificial Intelligence Generated Content (AIGC), particularly video generation with diffusion models, has been advanced rapidly. Invisible watermarking is a key technology for protecting AI-generated videos and tracing harmful content, and thus plays a crucial role in AI safety. Beyond post-processing watermarks which inevitably degrade video quality, recent studies have proposed distortion-free in-generation watermarking for video diffusion models. However, existing in-generation approaches are non-blind: they require maintaining all the message-key pairs and performing template-based matching during extraction, which incurs prohibitive computational costs at scale. Moreover, when applied to modern video diffusion models with causal 3D Variational Autoencoders (VAEs), their robustness against temporal disturbance becomes extremely weak. To overcome these challenges, we propose SIGMark, a Scalable In-Generation watermarking framework with blind extraction for video diffusion. To achieve blind-extraction, we propose to generate watermarked initial noise using a Global set of Frame-wise PseudoRandom Coding keys (GF-PRC), reducing the cost of storing large-scale information while preserving noise distribution and diversity for distortion-free watermarking. To enhance robustness, we further design a Segment Group-Ordering module (SGO) tailored to causal 3D VAEs, ensuring robust watermark inversion during extraction under temporal disturbance. Comprehensive experiments on modern diffusion models show that SIGMark achieves very high bit-accuracy during extraction under both temporal and spatial disturbances with minimal overhead, demonstrating its scalability and robustness. Our project is available at https://jeremyzhao1998.github.io/SIGMark-release/.
Investigating Domain Gaps for Indoor 3D Object Detection
Aug 24, 2025As a fundamental task for indoor scene understanding, 3D object detection has been extensively studied, and the accuracy on indoor point cloud data has been substantially improved. However, existing researches have been conducted on limited datasets, where the training and testing sets share the same distribution. In this paper, we consider the task of adapting indoor 3D object detectors from one dataset to another, presenting a comprehensive benchmark with ScanNet, SUN RGB-D and 3D Front datasets, as well as our newly proposed large-scale datasets ProcTHOR-OD and ProcFront generated by a 3D simulator. Since indoor point cloud datasets are collected and constructed in different ways, the object detectors are likely to overfit to specific factors within each dataset, such as point cloud quality, bounding box layout and instance features. We conduct experiments across datasets on different adaptation scenarios including synthetic-to-real adaptation, point cloud quality adaptation, layout adaptation and instance feature adaptation, analyzing the impact of different domain gaps on 3D object detectors. We also introduce several approaches to improve adaptation performances, providing baselines for domain adaptive indoor 3D object detection, hoping that future works may propose detectors with stronger generalization ability across domains. Our project homepage can be found in https://jeremyzhao1998.github.io/DAVoteNet-release/.
AR-VRM: Imitating Human Motions for Visual Robot Manipulation with Analogical Reasoning
Aug 11, 2025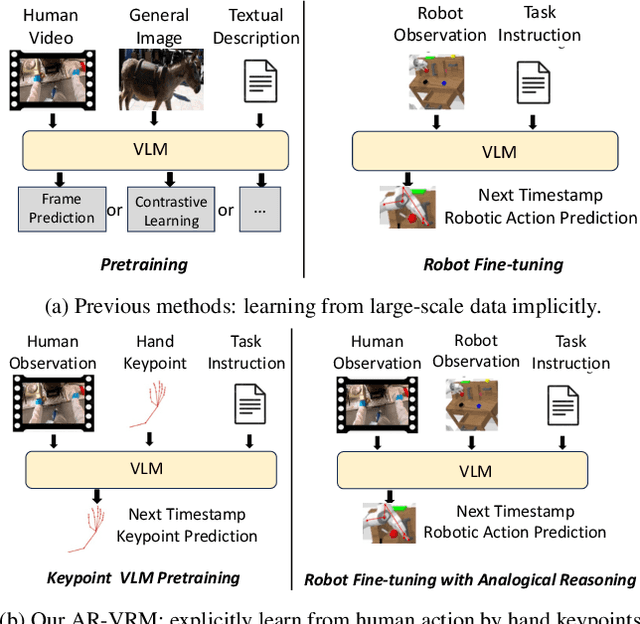
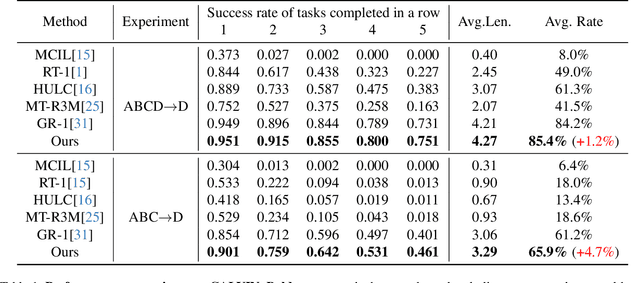
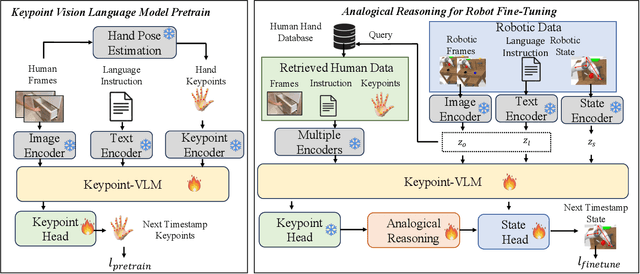
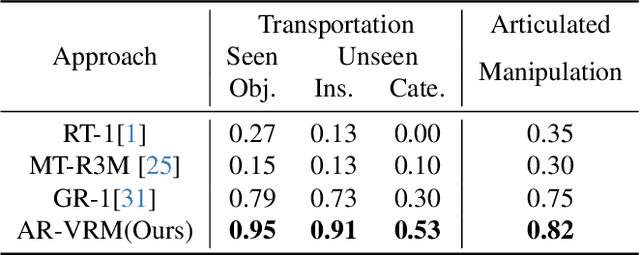
Visual Robot Manipulation (VRM) aims to enable a robot to follow natural language instructions based on robot states and visual observations, and therefore requires costly multi-modal data. To compensate for the deficiency of robot data, existing approaches have employed vision-language pretraining with large-scale data. However, they either utilize web data that differs from robotic tasks, or train the model in an implicit way (e.g., predicting future frames at the pixel level), thus showing limited generalization ability under insufficient robot data. In this paper, we propose to learn from large-scale human action video datasets in an explicit way (i.e., imitating human actions from hand keypoints), introducing Visual Robot Manipulation with Analogical Reasoning (AR-VRM). To acquire action knowledge explicitly from human action videos, we propose a keypoint Vision-Language Model (VLM) pretraining scheme, enabling the VLM to learn human action knowledge and directly predict human hand keypoints. During fine-tuning on robot data, to facilitate the robotic arm in imitating the action patterns of human motions, we first retrieve human action videos that perform similar manipulation tasks and have similar historical observations , and then learn the Analogical Reasoning (AR) map between human hand keypoints and robot components. Taking advantage of focusing on action keypoints instead of irrelevant visual cues, our method achieves leading performance on the CALVIN benchmark {and real-world experiments}. In few-shot scenarios, our AR-VRM outperforms previous methods by large margins , underscoring the effectiveness of explicitly imitating human actions under data scarcity.
CRTrack: Low-Light Semi-Supervised Multi-object Tracking Based on Consistency Regularization
Feb 24, 2025


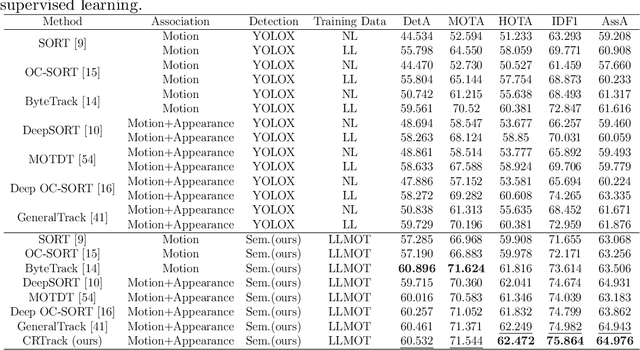
Multi-object tracking under low-light environments is prevalent in real life. Recent years have seen rapid development in the field of multi-object tracking. However, due to the lack of datasets and the high cost of annotations, multi-object tracking under low-light environments remains a persistent challenge. In this paper, we focus on multi-object tracking under low-light conditions. To address the issues of limited data and the lack of dataset, we first constructed a low-light multi-object tracking dataset (LLMOT). This dataset comprises data from MOT17 that has been enhanced for nighttime conditions as well as multiple unannotated low-light videos. Subsequently, to tackle the high annotation costs and address the issue of image quality degradation, we propose a semi-supervised multi-object tracking method based on consistency regularization named CRTrack. First, we calibrate a consistent adaptive sampling assignment to replace the static IoU-based strategy, enabling the semi-supervised tracking method to resist noisy pseudo-bounding boxes. Then, we design a adaptive semi-supervised network update method, which effectively leverages unannotated data to enhance model performance. Dataset and Code: https://github.com/ZJZhao123/CRTrack.
PlanLLM: Video Procedure Planning with Refinable Large Language Models
Dec 26, 2024Video procedure planning, i.e., planning a sequence of action steps given the video frames of start and goal states, is an essential ability for embodied AI. Recent works utilize Large Language Models (LLMs) to generate enriched action step description texts to guide action step decoding. Although LLMs are introduced, these methods decode the action steps into a closed-set of one-hot vectors, limiting the model's capability of generalizing to new steps or tasks. Additionally, fixed action step descriptions based on world-level commonsense may contain noise in specific instances of visual states. In this paper, we propose PlanLLM, a cross-modal joint learning framework with LLMs for video procedure planning. We propose an LLM-Enhanced Planning module which fully uses the generalization ability of LLMs to produce free-form planning output and to enhance action step decoding. We also propose Mutual Information Maximization module to connect world-level commonsense of step descriptions and sample-specific information of visual states, enabling LLMs to employ the reasoning ability to generate step sequences. With the assistance of LLMs, our method can both closed-set and open vocabulary procedure planning tasks. Our PlanLLM achieves superior performance on three benchmarks, demonstrating the effectiveness of our designs.
SSPFusion: A Semantic Structure-Preserving Approach for Infrared and Visible Image Fusion
Sep 26, 2023Most existing learning-based infrared and visible image fusion (IVIF) methods exhibit massive redundant information in the fusion images, i.e., yielding edge-blurring effect or unrecognizable for object detectors. To alleviate these issues, we propose a semantic structure-preserving approach for IVIF, namely SSPFusion. At first, we design a Structural Feature Extractor (SFE) to extract the structural features of infrared and visible images. Then, we introduce a multi-scale Structure-Preserving Fusion (SPF) module to fuse the structural features of infrared and visible images, while maintaining the consistency of semantic structures between the fusion and source images. Owing to these two effective modules, our method is able to generate high-quality fusion images from pairs of infrared and visible images, which can boost the performance of downstream computer-vision tasks. Experimental results on three benchmarks demonstrate that our method outperforms eight state-of-the-art image fusion methods in terms of both qualitative and quantitative evaluations. The code for our method, along with additional comparison results, will be made available at: https://github.com/QiaoYang-CV/SSPFUSION.
IAIFNet: An Illumination-Aware Infrared and Visible Image Fusion Network
Sep 26, 2023Infrared and visible image fusion (IVIF) is used to generate fusion images with comprehensive features of both images, which is beneficial for downstream vision tasks. However, current methods rarely consider the illumination condition in low-light environments, and the targets in the fused images are often not prominent. To address the above issues, we propose an Illumination-Aware Infrared and Visible Image Fusion Network, named as IAIFNet. In our framework, an illumination enhancement network first estimates the incident illumination maps of input images. Afterwards, with the help of proposed adaptive differential fusion module (ADFM) and salient target aware module (STAM), an image fusion network effectively integrates the salient features of the illumination-enhanced infrared and visible images into a fusion image of high visual quality. Extensive experimental results verify that our method outperforms five state-of-the-art methods of fusing infrared and visible images.
SAMP: A Toolkit for Model Inference with Self-Adaptive Mixed-Precision
Sep 19, 2022
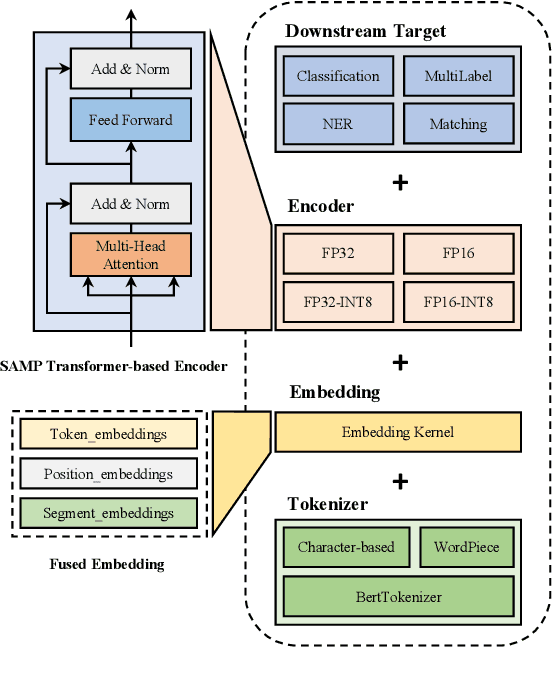
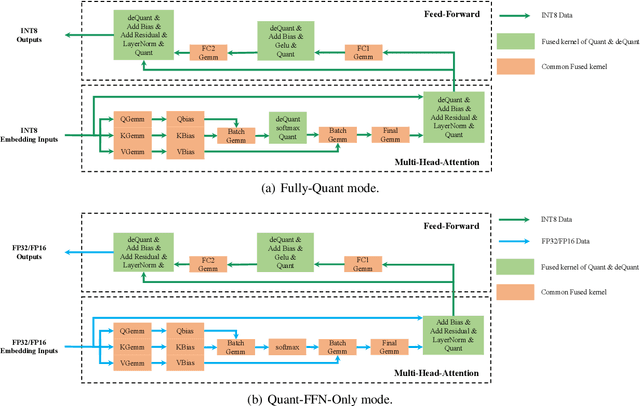
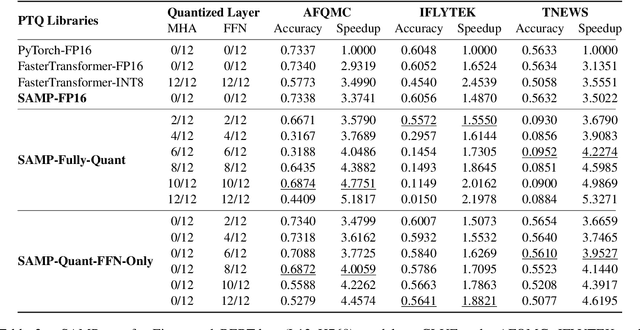
The latest industrial inference engines, such as FasterTransformer1 and TurboTransformers, have verified that half-precision floating point (FP16) and 8-bit integer (INT8) quantization can greatly improve model inference speed. However, the existing FP16 or INT8 quantization methods are too complicated, and improper usage will lead to performance damage greatly. In this paper, we develop a toolkit for users to easily quantize their models for inference, in which a Self-Adaptive Mixed-Precision (SAMP) is proposed to automatically control quantization rate by a mixed-precision architecture to balance efficiency and performance. Experimental results show that our SAMP toolkit has a higher speedup than PyTorch and FasterTransformer while ensuring the required performance. In addition, SAMP is based on a modular design, decoupling the tokenizer, embedding, encoder and target layers, which allows users to handle various downstream tasks and can be seamlessly integrated into PyTorch.