 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAR-VRM: Imitating Human Motions for Visual Robot Manipulation with Analogical Reasoning
Aug 11, 2025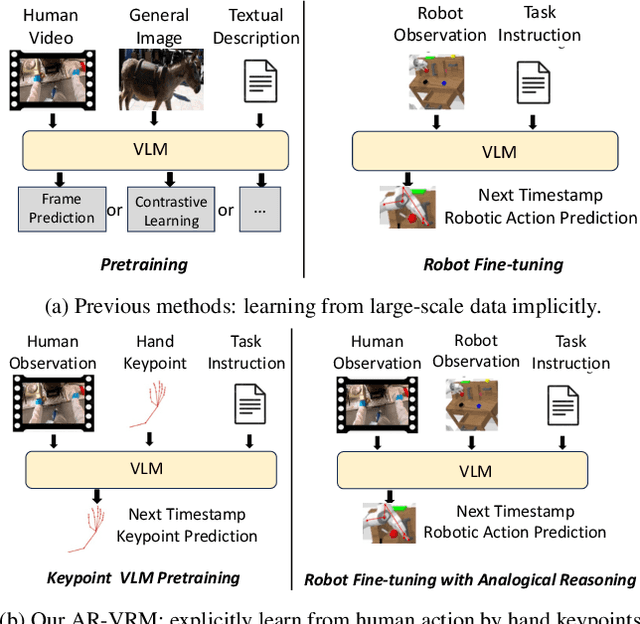
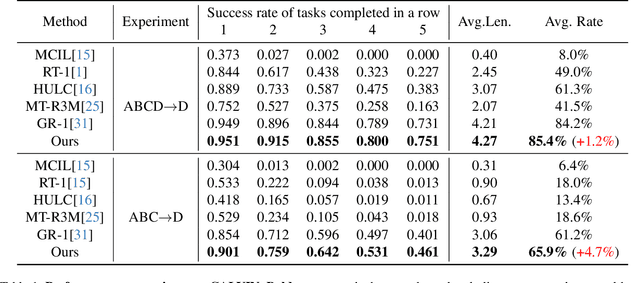
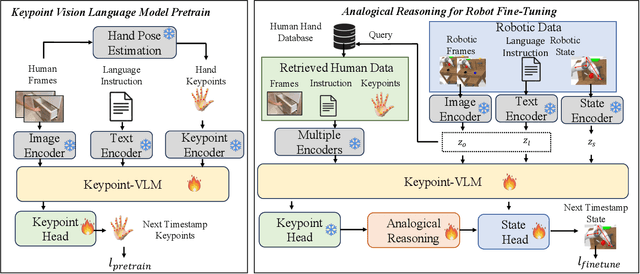
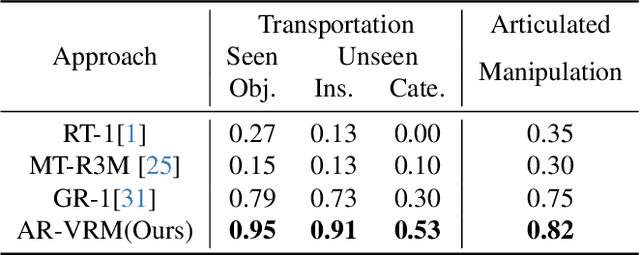
Visual Robot Manipulation (VRM) aims to enable a robot to follow natural language instructions based on robot states and visual observations, and therefore requires costly multi-modal data. To compensate for the deficiency of robot data, existing approaches have employed vision-language pretraining with large-scale data. However, they either utilize web data that differs from robotic tasks, or train the model in an implicit way (e.g., predicting future frames at the pixel level), thus showing limited generalization ability under insufficient robot data. In this paper, we propose to learn from large-scale human action video datasets in an explicit way (i.e., imitating human actions from hand keypoints), introducing Visual Robot Manipulation with Analogical Reasoning (AR-VRM). To acquire action knowledge explicitly from human action videos, we propose a keypoint Vision-Language Model (VLM) pretraining scheme, enabling the VLM to learn human action knowledge and directly predict human hand keypoints. During fine-tuning on robot data, to facilitate the robotic arm in imitating the action patterns of human motions, we first retrieve human action videos that perform similar manipulation tasks and have similar historical observations , and then learn the Analogical Reasoning (AR) map between human hand keypoints and robot components. Taking advantage of focusing on action keypoints instead of irrelevant visual cues, our method achieves leading performance on the CALVIN benchmark {and real-world experiments}. In few-shot scenarios, our AR-VRM outperforms previous methods by large margins , underscoring the effectiveness of explicitly imitating human actions under data scarcity.
Hierarchical Sub-action Tree for Continuous Sign Language Recognition
Jun 26, 2025Continuous sign language recognition (CSLR) aims to transcribe untrimmed videos into glosses, which are typically textual words. Recent studies indicate that the lack of large datasets and precise annotations has become a bottleneck for CSLR due to insufficient training data. To address this, some works have developed cross-modal solutions to align visual and textual modalities. However, they typically extract textual features from glosses without fully utilizing their knowledge. In this paper, we propose the Hierarchical Sub-action Tree (HST), termed HST-CSLR, to efficiently combine gloss knowledge with visual representation learning. By incorporating gloss-specific knowledge from large language models, our approach leverages textual information more effectively. Specifically, we construct an HST for textual information representation, aligning visual and textual modalities step-by-step and benefiting from the tree structure to reduce computational complexity. Additionally, we impose a contrastive alignment enhancement to bridge the gap between the two modalities. Experiments on four datasets (PHOENIX-2014, PHOENIX-2014T, CSL-Daily, and Sign Language Gesture) demonstrate the effectiveness of our HST-CSLR.
PlanLLM: Video Procedure Planning with Refinable Large Language Models
Dec 26, 2024Video procedure planning, i.e., planning a sequence of action steps given the video frames of start and goal states, is an essential ability for embodied AI. Recent works utilize Large Language Models (LLMs) to generate enriched action step description texts to guide action step decoding. Although LLMs are introduced, these methods decode the action steps into a closed-set of one-hot vectors, limiting the model's capability of generalizing to new steps or tasks. Additionally, fixed action step descriptions based on world-level commonsense may contain noise in specific instances of visual states. In this paper, we propose PlanLLM, a cross-modal joint learning framework with LLMs for video procedure planning. We propose an LLM-Enhanced Planning module which fully uses the generalization ability of LLMs to produce free-form planning output and to enhance action step decoding. We also propose Mutual Information Maximization module to connect world-level commonsense of step descriptions and sample-specific information of visual states, enabling LLMs to employ the reasoning ability to generate step sequences. With the assistance of LLMs, our method can both closed-set and open vocabulary procedure planning tasks. Our PlanLLM achieves superior performance on three benchmarks, demonstrating the effectiveness of our designs.
3D Vision and Language Pretraining with Large-Scale Synthetic Data
Jul 08, 2024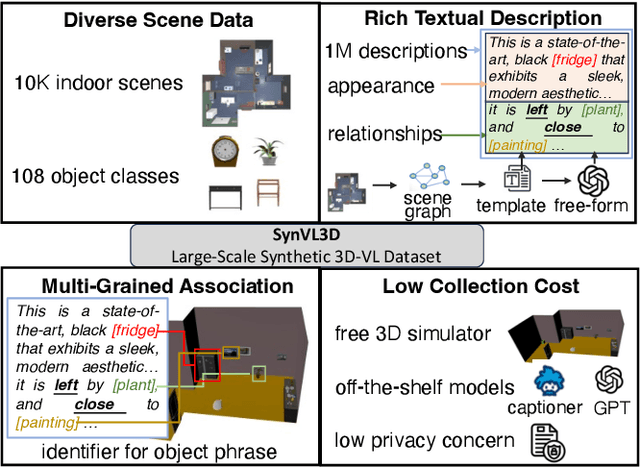
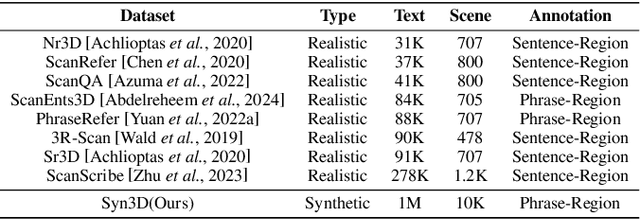
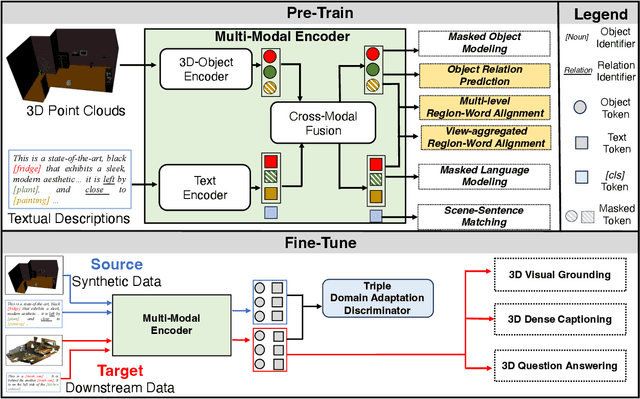
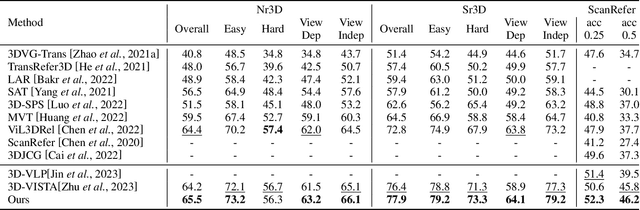
3D Vision-Language Pre-training (3D-VLP) aims to provide a pre-train model which can bridge 3D scenes with natural language, which is an important technique for embodied intelligence. However, current 3D-VLP datasets are hindered by limited scene-level diversity and insufficient fine-grained annotations (only 1.2K scenes and 280K textual annotations in ScanScribe), primarily due to the labor-intensive of collecting and annotating 3D scenes. To overcome these obstacles, we construct SynVL3D, a comprehensive synthetic scene-text corpus with 10K indoor scenes and 1M descriptions at object, view, and room levels, which has the advantages of diverse scene data, rich textual descriptions, multi-grained 3D-text associations, and low collection cost. Utilizing the rich annotations in SynVL3D, we pre-train a simple and unified Transformer for aligning 3D and language with multi-grained pretraining tasks. Moreover, we propose a synthetic-to-real domain adaptation in downstream task fine-tuning process to address the domain shift. Through extensive experiments, we verify the effectiveness of our model design by achieving state-of-the-art performance on downstream tasks including visual grounding, dense captioning, and question answering.
Active Object Detection with Knowledge Aggregation and Distillation from Large Models
May 21, 2024
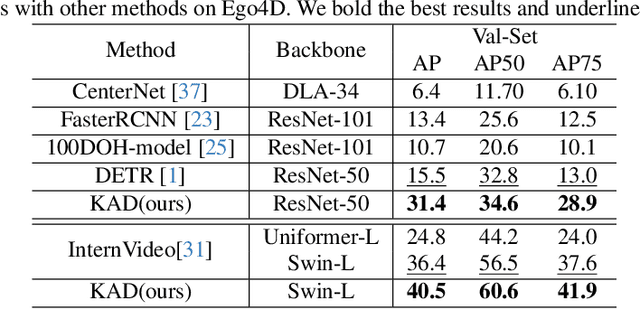
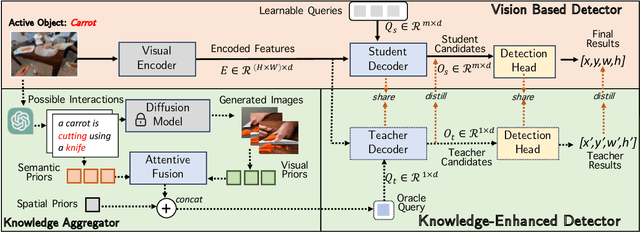

Accurately detecting active objects undergoing state changes is essential for comprehending human interactions and facilitating decision-making. The existing methods for active object detection (AOD) primarily rely on visual appearance of the objects within input, such as changes in size, shape and relationship with hands. However, these visual changes can be subtle, posing challenges, particularly in scenarios with multiple distracting no-change instances of the same category. We observe that the state changes are often the result of an interaction being performed upon the object, thus propose to use informed priors about object related plausible interactions (including semantics and visual appearance) to provide more reliable cues for AOD. Specifically, we propose a knowledge aggregation procedure to integrate the aforementioned informed priors into oracle queries within the teacher decoder, offering more object affordance commonsense to locate the active object. To streamline the inference process and reduce extra knowledge inputs, we propose a knowledge distillation approach that encourages the student decoder to mimic the detection capabilities of the teacher decoder using the oracle query by replicating its predictions and attention. Our proposed framework achieves state-of-the-art performance on four datasets, namely Ego4D, Epic-Kitchens, MECCANO, and 100DOH, which demonstrates the effectiveness of our approach in improving AOD.
Team PKU-WICT-MIPL PIC Makeup Temporal Video Grounding Challenge 2022 Technical Report
Jul 06, 2022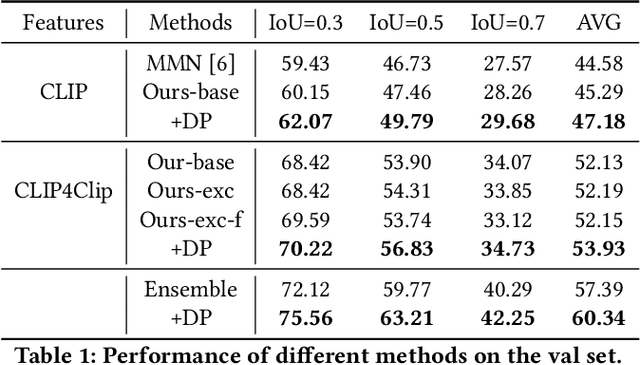
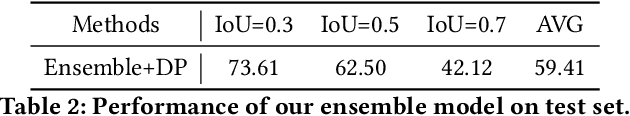
In this technical report, we briefly introduce the solutions of our team `PKU-WICT-MIPL' for the PIC Makeup Temporal Video Grounding (MTVG) Challenge in ACM-MM 2022. Given an untrimmed makeup video and a step query, the MTVG aims to localize a temporal moment of the target makeup step in the video. To tackle this task, we propose a phrase relationship mining framework to exploit the temporal localization relationship relevant to the fine-grained phrase and the whole sentence. Besides, we propose to constrain the localization results of different step sentence queries to not overlap with each other through a dynamic programming algorithm. The experimental results demonstrate the effectiveness of our method. Our final submission ranked 2nd on the leaderboard, with only a 0.55\% gap from the first.