 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRKT: Weakly Supervised Dynamic Scene Graph Generation with Temporal-enhanced Relation-aware Knowledge Transferring
Aug 07, 2025Dynamic Scene Graph Generation (DSGG) aims to create a scene graph for each video frame by detecting objects and predicting their relationships. Weakly Supervised DSGG (WS-DSGG) reduces annotation workload by using an unlocalized scene graph from a single frame per video for training. Existing WS-DSGG methods depend on an off-the-shelf external object detector to generate pseudo labels for subsequent DSGG training. However, detectors trained on static, object-centric images struggle in dynamic, relation-aware scenarios required for DSGG, leading to inaccurate localization and low-confidence proposals. To address the challenges posed by external object detectors in WS-DSGG, we propose a Temporal-enhanced Relation-aware Knowledge Transferring (TRKT) method, which leverages knowledge to enhance detection in relation-aware dynamic scenarios. TRKT is built on two key components:(1)Relation-aware knowledge mining: we first employ object and relation class decoders that generate category-specific attention maps to highlight both object regions and interactive areas. Then we propose an Inter-frame Attention Augmentation strategy that exploits optical flow for neighboring frames to enhance the attention maps, making them motion-aware and robust to motion blur. This step yields relation- and motion-aware knowledge mining for WS-DSGG. (2) we introduce a Dual-stream Fusion Module that integrates category-specific attention maps into external detections to refine object localization and boost confidence scores for object proposals. Extensive experiments demonstrate that TRKT achieves state-of-the-art performance on Action Genome dataset. Our code is avaliable at https://github.com/XZPKU/TRKT.git.
Exploring Conditional Multi-Modal Prompts for Zero-shot HOI Detection
Aug 05, 2024Zero-shot Human-Object Interaction (HOI) detection has emerged as a frontier topic due to its capability to detect HOIs beyond a predefined set of categories. This task entails not only identifying the interactiveness of human-object pairs and localizing them but also recognizing both seen and unseen interaction categories. In this paper, we introduce a novel framework for zero-shot HOI detection using Conditional Multi-Modal Prompts, namely CMMP. This approach enhances the generalization of large foundation models, such as CLIP, when fine-tuned for HOI detection. Unlike traditional prompt-learning methods, we propose learning decoupled vision and language prompts for interactiveness-aware visual feature extraction and generalizable interaction classification, respectively. Specifically, we integrate prior knowledge of different granularity into conditional vision prompts, including an input-conditioned instance prior and a global spatial pattern prior. The former encourages the image encoder to treat instances belonging to seen or potentially unseen HOI concepts equally while the latter provides representative plausible spatial configuration of the human and object under interaction. Besides, we employ language-aware prompt learning with a consistency constraint to preserve the knowledge of the large foundation model to enable better generalization in the text branch. Extensive experiments demonstrate the efficacy of our detector with conditional multi-modal prompts, outperforming previous state-of-the-art on unseen classes of various zero-shot settings. The code and models are available at \url{https://github.com/ltttpku/CMMP}.
Exploring the Potential of Large Foundation Models for Open-Vocabulary HOI Detection
Apr 10, 2024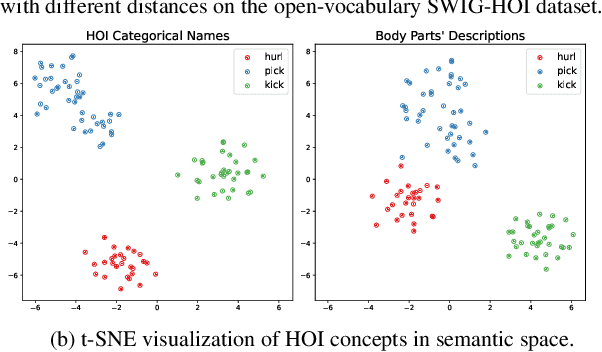
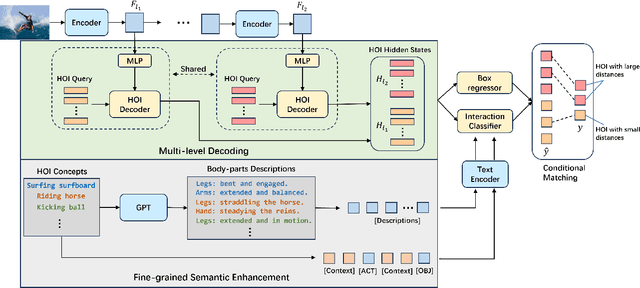
Open-vocabulary human-object interaction (HOI) detection, which is concerned with the problem of detecting novel HOIs guided by natural language, is crucial for understanding human-centric scenes. However, prior zero-shot HOI detectors often employ the same levels of feature maps to model HOIs with varying distances, leading to suboptimal performance in scenes containing human-object pairs with a wide range of distances. In addition, these detectors primarily rely on category names and overlook the rich contextual information that language can provide, which is essential for capturing open vocabulary concepts that are typically rare and not well-represented by category names alone. In this paper, we introduce a novel end-to-end open vocabulary HOI detection framework with conditional multi-level decoding and fine-grained semantic enhancement (CMD-SE), harnessing the potential of Visual-Language Models (VLMs). Specifically, we propose to model human-object pairs with different distances with different levels of feature maps by incorporating a soft constraint during the bipartite matching process. Furthermore, by leveraging large language models (LLMs) such as GPT models, we exploit their extensive world knowledge to generate descriptions of human body part states for various interactions. Then we integrate the generalizable and fine-grained semantics of human body parts to improve interaction recognition. Experimental results on two datasets, SWIG-HOI and HICO-DET, demonstrate that our proposed method achieves state-of-the-art results in open vocabulary HOI detection. The code and models are available at https://github.com/ltttpku/CMD-SE-release.
Efficient Adaptive Human-Object Interaction Detection with Concept-guided Memory
Sep 07, 2023Human Object Interaction (HOI) detection aims to localize and infer the relationships between a human and an object. Arguably, training supervised models for this task from scratch presents challenges due to the performance drop over rare classes and the high computational cost and time required to handle long-tailed distributions of HOIs in complex HOI scenes in realistic settings. This observation motivates us to design an HOI detector that can be trained even with long-tailed labeled data and can leverage existing knowledge from pre-trained models. Inspired by the powerful generalization ability of the large Vision-Language Models (VLM) on classification and retrieval tasks, we propose an efficient Adaptive HOI Detector with Concept-guided Memory (ADA-CM). ADA-CM has two operating modes. The first mode makes it tunable without learning new parameters in a training-free paradigm. Its second mode incorporates an instance-aware adapter mechanism that can further efficiently boost performance if updating a lightweight set of parameters can be afforded. Our proposed method achieves competitive results with state-of-the-art on the HICO-DET and V-COCO datasets with much less training time. Code can be found at https://github.com/ltttpku/ADA-CM.
EgoTaskQA: Understanding Human Tasks in Egocentric Videos
Oct 08, 2022
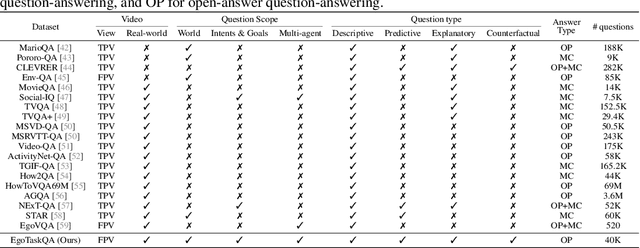
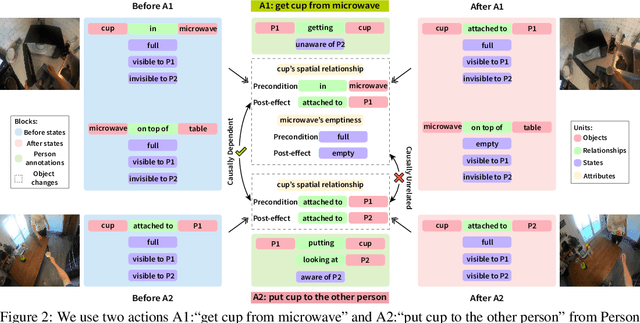
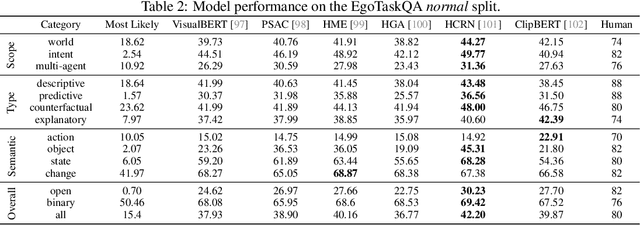
Understanding human tasks through video observations is an essential capability of intelligent agents. The challenges of such capability lie in the difficulty of generating a detailed understanding of situated actions, their effects on object states (i.e., state changes), and their causal dependencies. These challenges are further aggravated by the natural parallelism from multi-tasking and partial observations in multi-agent collaboration. Most prior works leverage action localization or future prediction as an indirect metric for evaluating such task understanding from videos. To make a direct evaluation, we introduce the EgoTaskQA benchmark that provides a single home for the crucial dimensions of task understanding through question-answering on real-world egocentric videos. We meticulously design questions that target the understanding of (1) action dependencies and effects, (2) intents and goals, and (3) agents' beliefs about others. These questions are divided into four types, including descriptive (what status?), predictive (what will?), explanatory (what caused?), and counterfactual (what if?) to provide diagnostic analyses on spatial, temporal, and causal understandings of goal-oriented tasks. We evaluate state-of-the-art video reasoning models on our benchmark and show their significant gaps between humans in understanding complex goal-oriented egocentric videos. We hope this effort will drive the vision community to move onward with goal-oriented video understanding and reasoning.
Team PKU-WICT-MIPL PIC Makeup Temporal Video Grounding Challenge 2022 Technical Report
Jul 06, 2022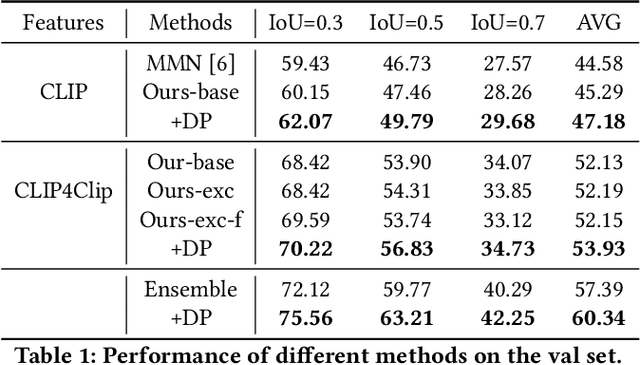
In this technical report, we briefly introduce the solutions of our team `PKU-WICT-MIPL' for the PIC Makeup Temporal Video Grounding (MTVG) Challenge in ACM-MM 2022. Given an untrimmed makeup video and a step query, the MTVG aims to localize a temporal moment of the target makeup step in the video. To tackle this task, we propose a phrase relationship mining framework to exploit the temporal localization relationship relevant to the fine-grained phrase and the whole sentence. Besides, we propose to constrain the localization results of different step sentence queries to not overlap with each other through a dynamic programming algorithm. The experimental results demonstrate the effectiveness of our method. Our final submission ranked 2nd on the leaderboard, with only a 0.55\% gap from the first.
Visual cryptography in single-pixel imaging
Nov 12, 2019

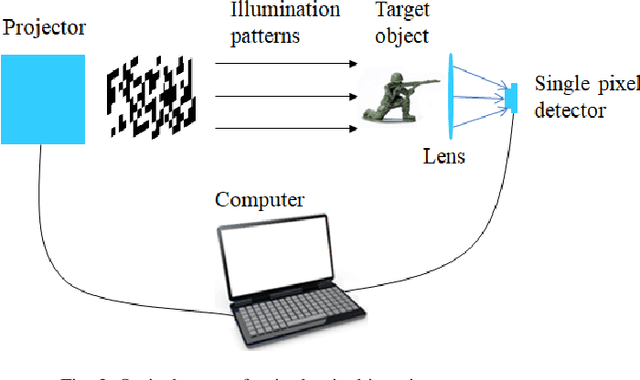
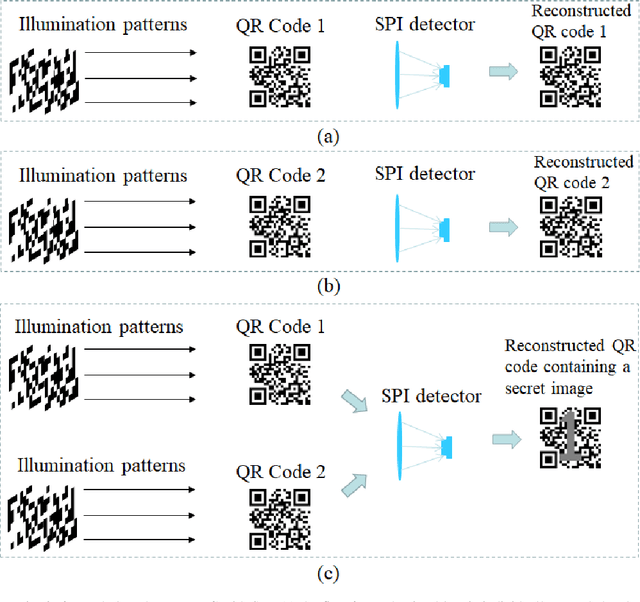
Two novel visual cryptography (VC) schemes are proposed by combining VC with single-pixel imaging (SPI) for the first time. It is pointed out that the overlapping of visual key images in VC is similar to the superposition of pixel intensities by a single-pixel detector in SPI. In the first scheme, QR-code VC is designed by using opaque sheets instead of transparent sheets. The secret image can be recovered when identical illumination patterns are projected onto multiple visual key images and a single detector is used to record the total light intensities. In the second scheme, the secret image is shared by multiple illumination pattern sequences and it can be recovered when the visual key patterns are projected onto identical items. The application of VC can be extended to more diversified scenarios by our proposed schemes.
Does deep learning always outperform simple linear regression in optical imaging?
Oct 31, 2019
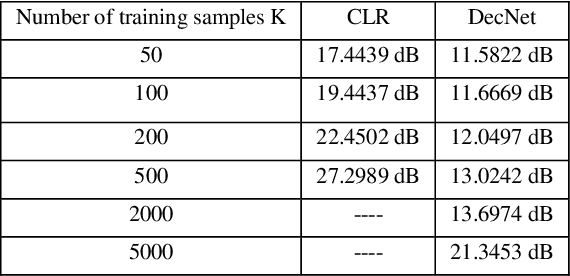
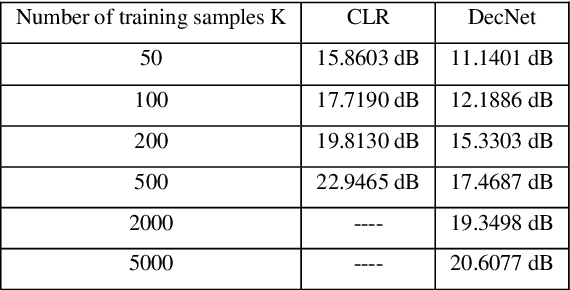
Deep learning has been extensively applied in many optical imaging applications in recent years. Despite the success, the limitations and drawbacks of deep learning in optical imaging have been seldom investigated. In this work, we show that conventional linear-regression-based methods can outperform the previously proposed deep learning approaches for two black-box optical imaging problems in some extent. Deep learning demonstrates its weakness especially when the number of training samples is small. The advantages and disadvantages of linear-regression-based methods and deep learning are analyzed and compared. Since many optical systems are essentially linear, a deep learning network containing many nonlinearity functions sometimes may not be the most suitable option.
Data hiding in complex-amplitude modulation using a digital micromirror device
Oct 24, 2019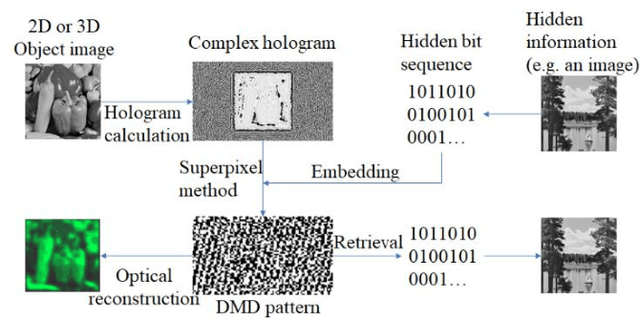
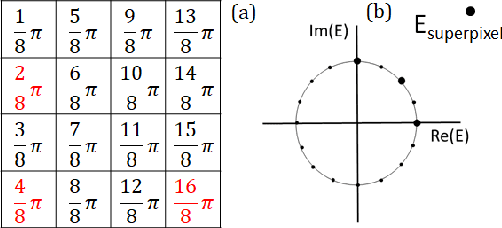
A digital micromirror device (DMD) is an amplitude-type spatial light modulator. However, a complex-amplitude light modulation with a DMD can be achieved using the superpixel scheme. In the superpixel scheme, we notice that multiple different DMD local block patterns may correspond to the same complex superpixel value. Based on this inherent encoding redundancy, a large amount of external data can be embedded into the DMD pattern without extra cost. Meanwhile, the original complex light field information carried by the DMD pattern is fully preserved. This proposed scheme is favorable for applications such as secure information transmission and copyright protection.
Known-plaintext attack and ciphertext-only attack for encrypted single-pixel imaging
May 31, 2019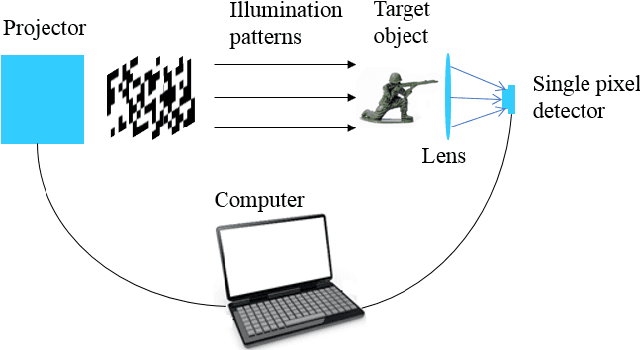
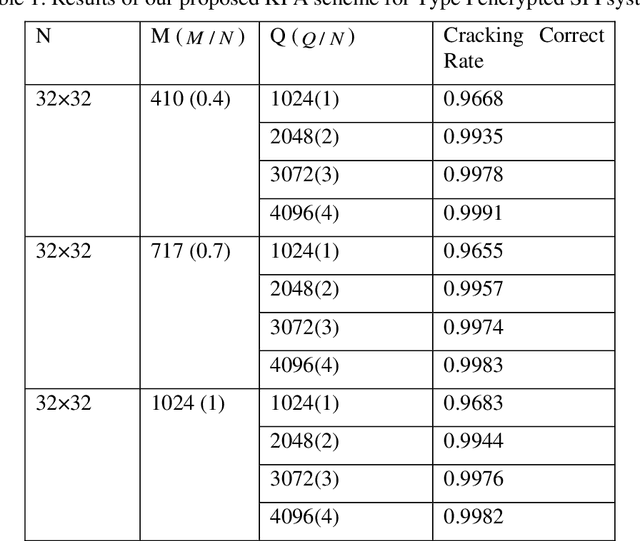
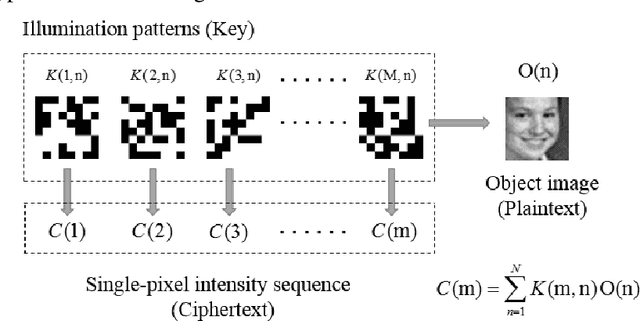
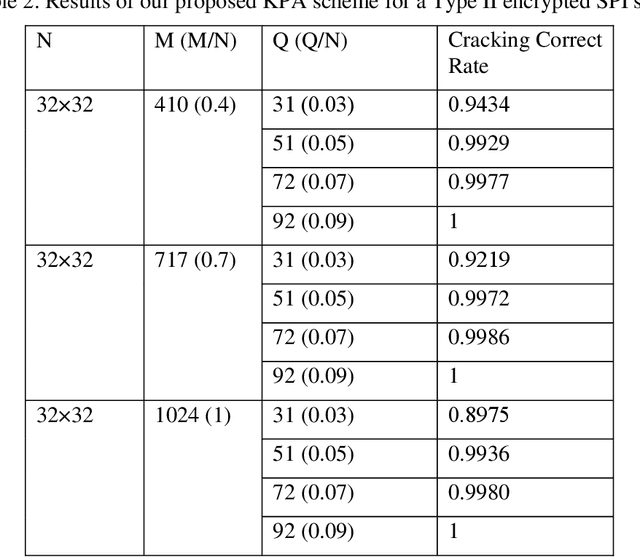
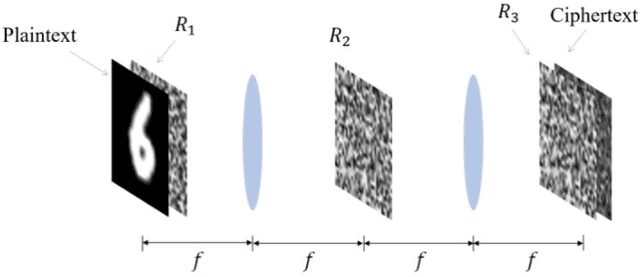
In many previous works, a single-pixel imaging (SPI) system is constructed as an optical image encryption system. Unauthorized users are not able to reconstruct the plaintext image from the ciphertext intensity sequence without knowing the illumination pattern key. However, little cryptanalysis about encrypted SPI has been investigated in the past. In this work, we propose a known-plaintext attack scheme and a ciphertext-only attack scheme to an encrypted SPI system for the first time. The known-plaintext attack is implemented by interchanging the roles of illumination patterns and object images in the SPI model. The ciphertext-only attack is implemented based on the statistical features of single-pixel intensity values. The two schemes can crack encrypted SPI systems and successfully recover the key containing correct illumination patterns.