 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-as-Inverse-Graphics Agent via Interleaved Multimodal Reasoning
Jan 16, 2026Vision-as-inverse-graphics, the concept of reconstructing an image as an editable graphics program is a long-standing goal of computer vision. Yet even strong VLMs aren't able to achieve this in one-shot as they lack fine-grained spatial and physical grounding capability. Our key insight is that closing this gap requires interleaved multimodal reasoning through iterative execution and verification. Stemming from this, we present VIGA (Vision-as-Inverse-Graphic Agent) that starts from an empty world and reconstructs or edits scenes through a closed-loop write-run-render-compare-revise procedure. To support long-horizon reasoning, VIGA combines (i) a skill library that alternates generator and verifier roles and (ii) an evolving context memory that contains plans, code diffs, and render history. VIGA is task-agnostic as it doesn't require auxiliary modules, covering a wide range of tasks such as 3D reconstruction, multi-step scene editing, 4D physical interaction, and 2D document editing, etc. Empirically, we found VIGA substantially improves one-shot baselines on BlenderGym (35.32%) and SlideBench (117.17%). Moreover, VIGA is also model-agnostic as it doesn't require finetuning, enabling a unified protocol to evaluate heterogeneous foundation VLMs. To better support this protocol, we introduce BlenderBench, a challenging benchmark that stress-tests interleaved multimodal reasoning with graphics engine, where VIGA improves by 124.70%.
RLVR-World: Training World Models with Reinforcement Learning
May 20, 2025World models predict state transitions in response to actions and are increasingly developed across diverse modalities. However, standard training objectives such as maximum likelihood estimation (MLE) often misalign with task-specific goals of world models, i.e., transition prediction metrics like accuracy or perceptual quality. In this paper, we present RLVR-World, a unified framework that leverages reinforcement learning with verifiable rewards (RLVR) to directly optimize world models for such metrics. Despite formulating world modeling as autoregressive prediction of tokenized sequences, RLVR-World evaluates metrics of decoded predictions as verifiable rewards. We demonstrate substantial performance gains on both language- and video-based world models across domains, including text games, web navigation, and robot manipulation. Our work indicates that, beyond recent advances in reasoning language models, RLVR offers a promising post-training paradigm for enhancing the utility of generative models more broadly.
Trajectory World Models for Heterogeneous Environments
Feb 03, 2025



Heterogeneity in sensors and actuators across environments poses a significant challenge to building large-scale pre-trained world models on top of this low-dimensional sensor information. In this work, we explore pre-training world models for heterogeneous environments by addressing key transfer barriers in both data diversity and model flexibility. We introduce UniTraj, a unified dataset comprising over one million trajectories from 80 environments, designed to scale data while preserving critical diversity. Additionally, we propose TrajWorld, a novel architecture capable of flexibly handling varying sensor and actuator information and capturing environment dynamics in-context. Pre-training TrajWorld on UniTraj demonstrates significant improvements in transition prediction and achieves a new state-of-the-art for off-policy evaluation. To the best of our knowledge, this work, for the first time, demonstrates the transfer benefits of world models across heterogeneous and complex control environments.
Exploring Conditional Multi-Modal Prompts for Zero-shot HOI Detection
Aug 05, 2024Zero-shot Human-Object Interaction (HOI) detection has emerged as a frontier topic due to its capability to detect HOIs beyond a predefined set of categories. This task entails not only identifying the interactiveness of human-object pairs and localizing them but also recognizing both seen and unseen interaction categories. In this paper, we introduce a novel framework for zero-shot HOI detection using Conditional Multi-Modal Prompts, namely CMMP. This approach enhances the generalization of large foundation models, such as CLIP, when fine-tuned for HOI detection. Unlike traditional prompt-learning methods, we propose learning decoupled vision and language prompts for interactiveness-aware visual feature extraction and generalizable interaction classification, respectively. Specifically, we integrate prior knowledge of different granularity into conditional vision prompts, including an input-conditioned instance prior and a global spatial pattern prior. The former encourages the image encoder to treat instances belonging to seen or potentially unseen HOI concepts equally while the latter provides representative plausible spatial configuration of the human and object under interaction. Besides, we employ language-aware prompt learning with a consistency constraint to preserve the knowledge of the large foundation model to enable better generalization in the text branch. Extensive experiments demonstrate the efficacy of our detector with conditional multi-modal prompts, outperforming previous state-of-the-art on unseen classes of various zero-shot settings. The code and models are available at \url{https://github.com/ltttpku/CMMP}.
iVideoGPT: Interactive VideoGPTs are Scalable World Models
May 24, 2024



World models empower model-based agents to interactively explore, reason, and plan within imagined environments for real-world decision-making. However, the high demand for interactivity poses challenges in harnessing recent advancements in video generative models for developing world models at scale. This work introduces Interactive VideoGPT (iVideoGPT), a scalable autoregressive transformer framework that integrates multimodal signals--visual observations, actions, and rewards--into a sequence of tokens, facilitating an interactive experience of agents via next-token prediction. iVideoGPT features a novel compressive tokenization technique that efficiently discretizes high-dimensional visual observations. Leveraging its scalable architecture, we are able to pre-train iVideoGPT on millions of human and robotic manipulation trajectories, establishing a versatile foundation that is adaptable to serve as interactive world models for a wide range of downstream tasks. These include action-conditioned video prediction, visual planning, and model-based reinforcement learning, where iVideoGPT achieves competitive performance compared with state-of-the-art methods. Our work advances the development of interactive general world models, bridging the gap between generative video models and practical model-based reinforcement learning applications.
Exploring the Potential of Large Foundation Models for Open-Vocabulary HOI Detection
Apr 10, 2024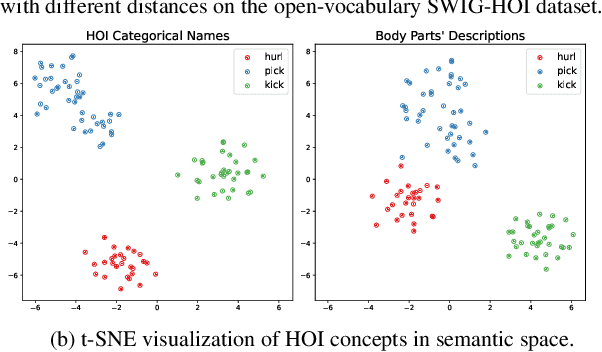
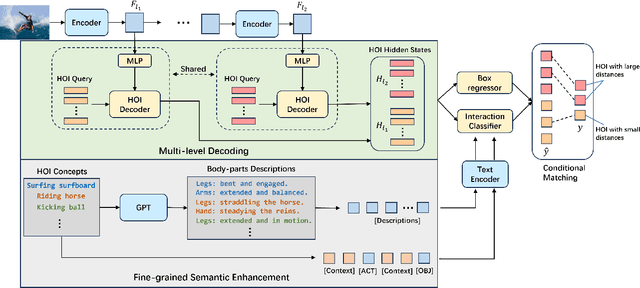
Open-vocabulary human-object interaction (HOI) detection, which is concerned with the problem of detecting novel HOIs guided by natural language, is crucial for understanding human-centric scenes. However, prior zero-shot HOI detectors often employ the same levels of feature maps to model HOIs with varying distances, leading to suboptimal performance in scenes containing human-object pairs with a wide range of distances. In addition, these detectors primarily rely on category names and overlook the rich contextual information that language can provide, which is essential for capturing open vocabulary concepts that are typically rare and not well-represented by category names alone. In this paper, we introduce a novel end-to-end open vocabulary HOI detection framework with conditional multi-level decoding and fine-grained semantic enhancement (CMD-SE), harnessing the potential of Visual-Language Models (VLMs). Specifically, we propose to model human-object pairs with different distances with different levels of feature maps by incorporating a soft constraint during the bipartite matching process. Furthermore, by leveraging large language models (LLMs) such as GPT models, we exploit their extensive world knowledge to generate descriptions of human body part states for various interactions. Then we integrate the generalizable and fine-grained semantics of human body parts to improve interaction recognition. Experimental results on two datasets, SWIG-HOI and HICO-DET, demonstrate that our proposed method achieves state-of-the-art results in open vocabulary HOI detection. The code and models are available at https://github.com/ltttpku/CMD-SE-release.