 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards 3D heart mesh generation using contactless radar imaging and physics-informed neural network
May 25, 2026Cardiac function evaluation necessitates continuous, non-invasive monitoring, a capability limited in MRI. Millimeter-wave (mmWave) radar and its Synthetic Aperture Radar (SAR) mode offer a privacy-preserving and portable point-of-care clinical applications. However, reconstructing high-fidelity 3D cardiac geometry from SAR remains an open challenge. Traditional radar methods generate sparse point clouds that lack continuous surface topology. Meanwhile, direct application of optical reconstruction networks performs poorly due to the severe speckle noise and ambiguous boundaries inherent in SAR images. To bridge this gap, we propose SAR2Mesh, a novel framework that reformulates the task as a coarse-to-fine mesh deformation process. By initializing with a topological template, our approach explicitly preserves anatomical connectivity through progressive mesh deformation.We introduce a geometry-aware feature projection module to extract multi-view features via 3D-to-2D sampling, and a physics-informed radar loss to enforce consistency between the predicted geometry and raw radar echoes. Furthermore, we present Cardiac Mesh-SAR, the first large-scale paired SAR-mesh dataset. Extensive experiments demonstrate that SAR2Mesh significantly outperforms existing image-based baselines, achieving accurate and physically consistent cardiac reconstructions.
TriDP-PTM: a three-stage distortion-perception tradeoff guides the pre-training model for radar cardiac sensing
May 25, 2026Cardiovascular diseases (CVDs) remain a leading cause of death globally, necessitating continuous, accurate non-invasive cardiac monitoring. While non-contact radar-based approaches show great promise, they often employ a single "distortion-driven" or "perception-driven" paradigm, frequently facing a trade-off between "low distortion but weak semantic information" and "high perceptual fidelity but poor interpretability." To address this, we propose a Three-stage Distortion-Perception Pre-Training Model (TriDP-PTM), a radar-based multi-scale fusion dual-path framework that systematically compares the "direct radar-to-task" path against an "indirect radar-to-ECG-to-task" path. By integrating an ECG generator with a feature discriminator to form a composite loss function, our approach effectively incorporates medical priors - such as ECG morphology and rhythm - into downstream tasks. Through empirical analysis, we reveal that this trade-off manifests in three distinct phases (Positive-Sum, Coopetitive, and Negative-Sum), showing optimal downstream clinical accuracy typically emerges in the coopetitive stage. Extensive experiments on a dataset involving 30 subjects across 5 physiological states reveal that the indirect path consistently outperforms the direct path in diverse tasks, achieving 0.80 mean IoU in waveform segmentation, 98.3% average classification accuracy across four tasks, and a 56% MAE reduction in blood pressure regression compared to the strongest baselines. These findings validate our framework and indicate that, within the indirect radar-to-ECG pathway, appropriately weighting distortion and perception losses to operate in the coopetitive regime is critical for achieving both clinically interpretable ECG morphology and strong downstream accuracy in non-contact cardiac monitoring.
Interpretable Machine Learning for Antepartum Prediction of Pregnancy-Associated Thrombotic Microangiopathy Using Routine Longitudinal Laboratory Data
May 13, 2026Background: Pregnancy-associated thrombotic microangiopathy (P-TMA) is rare but life-threatening. Early risk prediction before overt clinical presentation remains challenging, as the associated laboratory abnormalities are subtle, multidimensional, and frequently masked by common physiological changes such as gestational thrombocytopenia and pregnancy-related proteinuria, thus overlapping heavily with benign obstetric and renal conditions. This complexity is poorly captured by univariate or rule-based approaches; however, it is addressable by machine learning, which can extract latent, time-dependent risk signatures from longitudinal clinical tests. Methods: This retrospective study included 300 pregnancies comprising 142 P-TMA cases and 158 controls. After exclusion of identifiers and non-informative variables, 146 longitudinal laboratory predictors were retained. Participants were divided into a training cohort (80%) and a held-out test cohort (20%) using stratified sampling. Five algorithms were evaluated: logistic regression, support vector machine with radial basis function kernel, random forest, extra trees, and gradient boosting. The final model was selected by mean cross-validated AUROC, refitted on the full training cohort, and evaluated once in the held-out test cohort. Interpretability analyses examined global feature importance and distributional patterns of leading predictors. Results: Gradient boosting was prespecified by cross-validation in the training cohort. The model achieved an AUROC of 0.872 (95% CI: 0.769-0.952) and an AUPRC of 0.883 (95% CI: 0.780-0.959) in a held-out test cohort, with sensitivity of 0.750 and specificity of 0.812. Conclusions: Longitudinal clinical laboratory tests obtained during routine care contained informative and clinically plausible signals for P-TMA risk. Notably, cystatin C at week 6 showed promise as an early monitoring indicator.
3D MRI Image Pretraining via Controllable 2D Slice Navigation Task
May 07, 2026Self-supervised pretraining has become the mainstream approach for learning MRI representations from unlabeled scans. However, most existing objectives still treat each scan primarily as static aggregations of slices, patches or volumes. We ask whether there exists an intrinsic form of self-supervision signal that is different from reconstructing the masked patches, through transforming the 3D volumes into controllable 2D rendered sequences: by rendering slices at continuous positions, orientations, and scales, a 3D volume can be converted into dense video-action sequences whose controls are the action trajectories. We study this formulation with an action-conditioned pretraining objective, where a tokenizer encodes slice observations and a latent dynamics model predicts the evolution of latent features. Across representative anatomical and spatial downstream tasks, the proposed pretraining is evaluated against standard static-volume baselines, tokenizer-only pretraining, and dynamics variants without aligned actions. These results suggest that controllable MRI slice navigation provides a useful complementary pretraining interface for learning anatomical and spatial representations from large unlabeled MRI collections.
The Texture-Shape Dilemma: Boundary-Safe Synthetic Generation for 3D Medical Transformers
Mar 01, 2026Vision Transformers (ViTs) have revolutionized medical image analysis, yet their data-hungry nature clashes with the scarcity and privacy constraints of clinical archives. Formula-Driven Supervised Learning (FDSL) has emerged as a promising solution to this bottleneck, synthesizing infinite annotated samples from mathematical formulas without utilizing real patient data. However, existing FDSL paradigms rely on simple geometric shapes with homogeneous intensities, creating a substantial gap by neglecting tissue textures and noise patterns inherent in modalities like CT and MRI. In this paper, we identify a critical optimization conflict termed boundary aliasing: when high-frequency synthetic textures are naively added, they corrupt the image gradient signals necessary for learning structural boundaries, causing the model to fail in delineating real anatomical margins. To bridge this gap, we propose a novel Physics-inspired Spatially-Decoupled Synthesis framework. Our approach orthogonalizes the synthesis process: it first constructs a gradient-shielded buffer zone based on boundary distance to ensure stable shape learning, and subsequently injects physics-driven spectral textures into the object core. This design effectively reconciles robust shape representation learning with invariance to acquisition noise. Extensive experiments on the BTCV and MSD datasets demonstrate that our method significantly outperforms previous FDSL, as well as SSL methods trained on real-world medical datasets, by 1.43% on BTCV and up to 1.51% on MSD task, offering a scalable, annotation-free foundation for medical ViTs. The code will be made publicly available upon acceptance.
Fake It Right: Injecting Anatomical Logic into Synthetic Supervised Pre-training for Medical Segmentation
Mar 01, 2026Vision Transformers (ViTs) excel in 3D medical segmentation but require massive annotated datasets. While Self-Supervised Learning (SSL) mitigates this using unlabeled data, it still faces strict privacy and logistical barriers. Formula-Driven Supervised Learning (FDSL) offers a privacy-preserving alternative by pre-training on synthetic mathematical primitives. However, a critical semantic gap limits its efficacy: generic shapes lack the morphological fidelity, fixed spatial layouts, and inter-organ relationships of real anatomy, preventing models from learning essential global structural priors. To bridge this gap, we propose an Anatomy-Informed Synthetic Supervised Pre-training framework unifying FDSL's infinite scalability with anatomical realism. We replace basic primitives with a lightweight shape bank with de-identified, label-only segmentation masks from 5 subjects. Furthermore, we introduce a structure-aware sequential placement strategy to govern the patch synthesis process. Instead of random placement, we enforce physiological plausibility using spatial anchors for correct localization and a topological graph to manage inter-organ interactions (e.g., preventing impossible overlaps). Extensive experiments on BTCV and MSD datasets demonstrate that our method significantly outperforms state-of-the-art FDSL baselines and SSL methods by 1.74\% and up to 1.66\%, while exhibiting a robust scaling effect where performance improves with increased synthetic data volume. This provides a data-efficient, privacy-compliant solution for medical segmentation. The code will be made publicly available upon acceptance.
The Geometry of Transfer: Unlocking Medical Vision Manifolds for Training-Free Model Ranking
Feb 27, 2026The advent of large-scale self-supervised learning (SSL) has produced a vast zoo of medical foundation models. However, selecting optimal medical foundation models for specific segmentation tasks remains a computational bottleneck. Existing Transferability Estimation (TE) metrics, primarily designed for classification, rely on global statistical assumptions and fail to capture the topological complexity essential for dense prediction. We propose a novel Topology-Driven Transferability Estimation framework that evaluates manifold tractability rather than statistical overlap. Our approach introduces three components: (1) Global Representation Topology Divergence (GRTD), utilizing Minimum Spanning Trees to quantify feature-label structural isomorphism; (2) Local Boundary-Aware Topological Consistency (LBTC), which assesses manifold separability specifically at critical anatomical boundaries; and (3) Task-Adaptive Fusion, which dynamically integrates global and local metrics based on the semantic cardinality of the target task. Validated on the large-scale OpenMind benchmark across diverse anatomical targets and SSL foundation models, our approach significantly outperforms state-of-the-art baselines by around \textbf{31\%} relative improvement in the weighted Kendall, providing a robust, training-free proxy for efficient model selection without the cost of fine-tuning. The code will be made publicly available upon acceptance.
CubeDN: Real-time Drone Detection in 3D Space from Dual mmWave Radar Cubes
Aug 25, 2025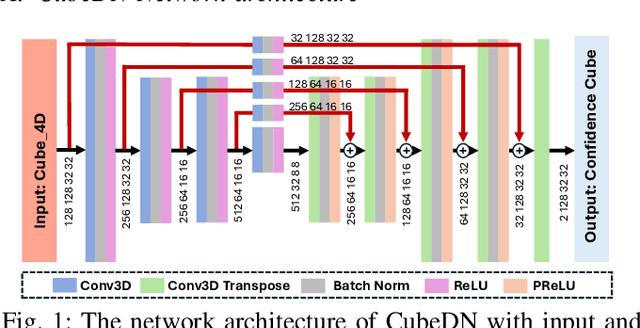
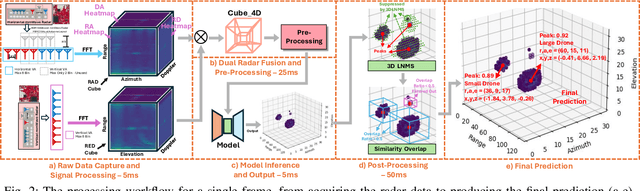


As drone use has become more widespread, there is a critical need to ensure safety and security. A key element of this is robust and accurate drone detection and localization. While cameras and other optical sensors like LiDAR are commonly used for object detection, their performance degrades under adverse lighting and environmental conditions. Therefore, this has generated interest in finding more reliable alternatives, such as millimeter-wave (mmWave) radar. Recent research on mmWave radar object detection has predominantly focused on 2D detection of road users. Although these systems demonstrate excellent performance for 2D problems, they lack the sensing capability to measure elevation, which is essential for 3D drone detection. To address this gap, we propose CubeDN, a single-stage end-to-end radar object detection network specifically designed for flying drones. CubeDN overcomes challenges such as poor elevation resolution by utilizing a dual radar configuration and a novel deep learning pipeline. It simultaneously detects, localizes, and classifies drones of two sizes, achieving decimeter-level tracking accuracy at closer ranges with overall $95\%$ average precision (AP) and $85\%$ average recall (AR). Furthermore, CubeDN completes data processing and inference at 10Hz, making it highly suitable for practical applications.
Investigating Domain Gaps for Indoor 3D Object Detection
Aug 24, 2025As a fundamental task for indoor scene understanding, 3D object detection has been extensively studied, and the accuracy on indoor point cloud data has been substantially improved. However, existing researches have been conducted on limited datasets, where the training and testing sets share the same distribution. In this paper, we consider the task of adapting indoor 3D object detectors from one dataset to another, presenting a comprehensive benchmark with ScanNet, SUN RGB-D and 3D Front datasets, as well as our newly proposed large-scale datasets ProcTHOR-OD and ProcFront generated by a 3D simulator. Since indoor point cloud datasets are collected and constructed in different ways, the object detectors are likely to overfit to specific factors within each dataset, such as point cloud quality, bounding box layout and instance features. We conduct experiments across datasets on different adaptation scenarios including synthetic-to-real adaptation, point cloud quality adaptation, layout adaptation and instance feature adaptation, analyzing the impact of different domain gaps on 3D object detectors. We also introduce several approaches to improve adaptation performances, providing baselines for domain adaptive indoor 3D object detection, hoping that future works may propose detectors with stronger generalization ability across domains. Our project homepage can be found in https://jeremyzhao1998.github.io/DAVoteNet-release/.
TRKT: Weakly Supervised Dynamic Scene Graph Generation with Temporal-enhanced Relation-aware Knowledge Transferring
Aug 07, 2025Dynamic Scene Graph Generation (DSGG) aims to create a scene graph for each video frame by detecting objects and predicting their relationships. Weakly Supervised DSGG (WS-DSGG) reduces annotation workload by using an unlocalized scene graph from a single frame per video for training. Existing WS-DSGG methods depend on an off-the-shelf external object detector to generate pseudo labels for subsequent DSGG training. However, detectors trained on static, object-centric images struggle in dynamic, relation-aware scenarios required for DSGG, leading to inaccurate localization and low-confidence proposals. To address the challenges posed by external object detectors in WS-DSGG, we propose a Temporal-enhanced Relation-aware Knowledge Transferring (TRKT) method, which leverages knowledge to enhance detection in relation-aware dynamic scenarios. TRKT is built on two key components:(1)Relation-aware knowledge mining: we first employ object and relation class decoders that generate category-specific attention maps to highlight both object regions and interactive areas. Then we propose an Inter-frame Attention Augmentation strategy that exploits optical flow for neighboring frames to enhance the attention maps, making them motion-aware and robust to motion blur. This step yields relation- and motion-aware knowledge mining for WS-DSGG. (2) we introduce a Dual-stream Fusion Module that integrates category-specific attention maps into external detections to refine object localization and boost confidence scores for object proposals. Extensive experiments demonstrate that TRKT achieves state-of-the-art performance on Action Genome dataset. Our code is avaliable at https://github.com/XZPKU/TRKT.git.