 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards ubiquitous radio access using nanodiamond based quantum receivers
Sep 28, 2024The development of sixth-generation (6G) wireless communication systems demands innovative solutions to address challenges in the deployment of a large number of base stations and the detection of multi-band signals. Quantum technology, specifically nitrogen vacancy (NV) centers in diamonds, offers promising potential for the development of compact, robust receivers capable of supporting multiple users. For the first time, we propose a multiple access scheme using fluorescent nanodiamonds (FNDs) containing NV centers as nano-antennas. The unique response of each FND to applied microwaves allows for distinguishable patterns of fluorescence intensities, enabling multi-user signal demodulation. We demonstrate the effectiveness of our FNDs-implemented receiver by simultaneously transmitting two uncoded digitally modulated information bit streams from two separate transmitters, achieving a low bit error ratio. Moreover, our design supports tunable frequency band communication and reference-free signal decoupling, reducing communication overhead. Furthermore, we implement a miniaturized device comprising all essential components, highlighting its practicality as a receiver serving multiple users simultaneously. This approach paves the way for the integration of quantum sensing technologies in future 6G wireless communication networks.
ResVG: Enhancing Relation and Semantic Understanding in Multiple Instances for Visual Grounding
Aug 29, 2024Visual grounding aims to localize the object referred to in an image based on a natural language query. Although progress has been made recently, accurately localizing target objects within multiple-instance distractions (multiple objects of the same category as the target) remains a significant challenge. Existing methods demonstrate a significant performance drop when there are multiple distractions in an image, indicating an insufficient understanding of the fine-grained semantics and spatial relationships between objects. In this paper, we propose a novel approach, the Relation and Semantic-sensitive Visual Grounding (ResVG) model, to address this issue. Firstly, we enhance the model's understanding of fine-grained semantics by injecting semantic prior information derived from text queries into the model. This is achieved by leveraging text-to-image generation models to produce images representing the semantic attributes of target objects described in queries. Secondly, we tackle the lack of training samples with multiple distractions by introducing a relation-sensitive data augmentation method. This method generates additional training data by synthesizing images containing multiple objects of the same category and pseudo queries based on their spatial relationships. The proposed ReSVG model significantly improves the model's ability to comprehend both object semantics and spatial relations, leading to enhanced performance in visual grounding tasks, particularly in scenarios with multiple-instance distractions. We conduct extensive experiments to validate the effectiveness of our methods on five datasets. Code is available at https://github.com/minghangz/ResVG.
YUAN 2.0: A Large Language Model with Localized Filtering-based Attention
Dec 04, 2023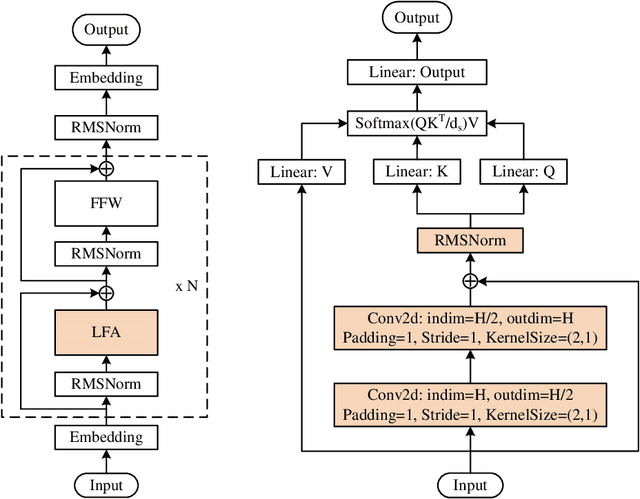

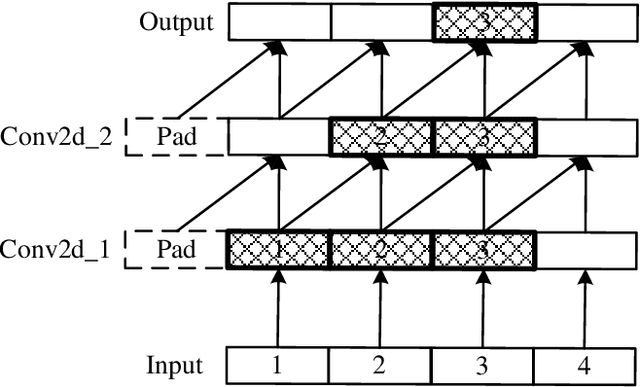
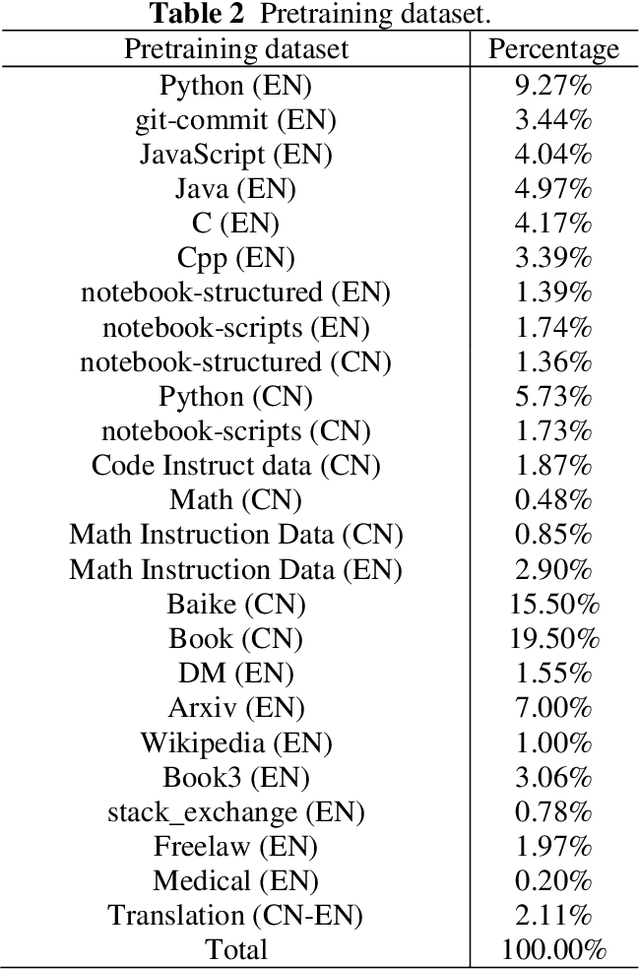
In this work, we develop and release Yuan 2.0, a series of large language models with parameters ranging from 2.1 billion to 102.6 billion. The Localized Filtering-based Attention (LFA) is introduced to incorporate prior knowledge of local dependencies of natural language into Attention. A data filtering and generating system is presented to build pre-training and fine-tuning dataset in high quality. A distributed training method with non-uniform pipeline parallel, data parallel, and optimizer parallel is proposed, which greatly reduces the bandwidth requirements of intra-node communication, and achieves good performance in large-scale distributed training. Yuan 2.0 models display impressive ability in code generation, math problem-solving, and chatting compared with existing models. The latest version of YUAN 2.0, including model weights and source code, is accessible at Github.