 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocratic-Geo: Synthetic Data Generation and Geometric Reasoning via Multi-Agent Interaction
Feb 03, 2026Multimodal Large Language Models (MLLMs) have significantly advanced vision-language understanding. However, even state-of-the-art models struggle with geometric reasoning, revealing a critical bottleneck: the extreme scarcity of high-quality image-text pairs. Human annotation is prohibitively expensive, while automated methods fail to ensure fidelity and training effectiveness. Existing approaches either passively adapt to available images or employ inefficient random exploration with filtering, decoupling generation from learning needs. We propose Socratic-Geo, a fully autonomous framework that dynamically couples data synthesis with model learning through multi-agent interaction. The Teacher agent generates parameterized Python scripts with reflective feedback (Reflect for solvability, RePI for visual validity), ensuring image-text pair purity. The Solver agent optimizes reasoning through preference learning, with failure paths guiding Teacher's targeted augmentation. Independently, the Generator learns image generation capabilities on accumulated "image-code-instruction" triplets, distilling programmatic drawing intelligence into visual generation. Starting from only 108 seed problems, Socratic-Solver achieves 49.11 on six benchmarks using one-quarter of baseline data, surpassing strong baselines by 2.43 points. Socratic-Generator achieves 42.4% on GenExam, establishing new state-of-the-art for open-source models, surpassing Seedream-4.0 (39.8%) and approaching Gemini-2.5-Flash-Image (43.1%).
Beyond Quantity: Trajectory Diversity Scaling for Code Agents
Feb 03, 2026As code large language models (LLMs) evolve into tool-interactive agents via the Model Context Protocol (MCP), their generalization is increasingly limited by low-quality synthetic data and the diminishing returns of quantity scaling. Moreover, quantity-centric scaling exhibits an early bottleneck that underutilizes trajectory data. We propose TDScaling, a Trajectory Diversity Scaling-based data synthesis framework for code agents that scales performance through diversity rather than raw volume. Under a fixed training budget, increasing trajectory diversity yields larger gains than adding more trajectories, improving the performance-cost trade-off for agent training. TDScaling integrates four innovations: (1) a Business Cluster mechanism that captures real-service logical dependencies; (2) a blueprint-driven multi-agent paradigm that enforces trajectory coherence; (3) an adaptive evolution mechanism that steers synthesis toward long-tail scenarios using Domain Entropy, Reasoning Mode Entropy, and Cumulative Action Complexity to prevent mode collapse; and (4) a sandboxed code tool that mitigates catastrophic forgetting of intrinsic coding capabilities. Experiments on general tool-use benchmarks (BFCL, tau^2-Bench) and code agent tasks (RebenchT, CodeCI, BIRD) demonstrate a win-win outcome: TDScaling improves both tool-use generalization and inherent coding proficiency. We plan to release the full codebase and the synthesized dataset (including 30,000+ tool clusters) upon publication.
Agentic Proposing: Enhancing Large Language Model Reasoning via Compositional Skill Synthesis
Feb 03, 2026Advancing complex reasoning in large language models relies on high-quality, verifiable datasets, yet human annotation remains cost-prohibitive and difficult to scale. Current synthesis paradigms often face a recurring trade-off: maintaining structural validity typically restricts problem complexity, while relaxing constraints to increase difficulty frequently leads to inconsistent or unsolvable instances. To address this, we propose Agentic Proposing, a framework that models problem synthesis as a goal-driven sequential decision process where a specialized agent dynamically selects and composes modular reasoning skills. Through an iterative workflow of internal reflection and tool-use, we develop the Agentic-Proposer-4B using Multi-Granularity Policy Optimization (MGPO) to generate high-precision, verifiable training trajectories across mathematics, coding, and science. Empirical results demonstrate that downstream solvers trained on agent-synthesized data significantly outperform leading baselines and exhibit robust cross-domain generalization. Notably, a 30B solver trained on only 11,000 synthesized trajectories achieves a state-of-the-art 91.6% accuracy on AIME25, rivaling frontier-scale proprietary models such as GPT-5 and proving that a small volume of high-quality synthetic signals can effectively substitute for massive human-curated datasets.
PLawBench: A Rubric-Based Benchmark for Evaluating LLMs in Real-World Legal Practice
Jan 23, 2026As large language models (LLMs) are increasingly applied to legal domain-specific tasks, evaluating their ability to perform legal work in real-world settings has become essential. However, existing legal benchmarks rely on simplified and highly standardized tasks, failing to capture the ambiguity, complexity, and reasoning demands of real legal practice. Moreover, prior evaluations often adopt coarse, single-dimensional metrics and do not explicitly assess fine-grained legal reasoning. To address these limitations, we introduce PLawBench, a Practical Law Benchmark designed to evaluate LLMs in realistic legal practice scenarios. Grounded in real-world legal workflows, PLawBench models the core processes of legal practitioners through three task categories: public legal consultation, practical case analysis, and legal document generation. These tasks assess a model's ability to identify legal issues and key facts, perform structured legal reasoning, and generate legally coherent documents. PLawBench comprises 850 questions across 13 practical legal scenarios, with each question accompanied by expert-designed evaluation rubrics, resulting in approximately 12,500 rubric items for fine-grained assessment. Using an LLM-based evaluator aligned with human expert judgments, we evaluate 10 state-of-the-art LLMs. Experimental results show that none achieves strong performance on PLawBench, revealing substantial limitations in the fine-grained legal reasoning capabilities of current LLMs and highlighting important directions for future evaluation and development of legal LLMs. Data is available at: https://github.com/skylenage/PLawbench.
Logics-STEM: Empowering LLM Reasoning via Failure-Driven Post-Training and Document Knowledge Enhancement
Jan 08, 2026We present Logics-STEM, a state-of-the-art reasoning model fine-tuned on Logics-STEM-SFT-Dataset, a high-quality and diverse dataset at 10M scale that represents one of the largest-scale open-source long chain-of-thought corpora. Logics-STEM targets reasoning tasks in the domains of Science, Technology, Engineering, and Mathematics (STEM), and exhibits exceptional performance on STEM-related benchmarks with an average improvement of 4.68% over the next-best model at 8B scale. We attribute the gains to our data-algorithm co-design engine, where they are jointly optimized to fit a gold-standard distribution behind reasoning. Data-wise, the Logics-STEM-SFT-Dataset is constructed from a meticulously designed data curation engine with 5 stages to ensure the quality, diversity, and scalability, including annotation, deduplication, decontamination, distillation, and stratified sampling. Algorithm-wise, our failure-driven post-training framework leverages targeted knowledge retrieval and data synthesis around model failure regions in the Supervised Fine-tuning (SFT) stage to effectively guide the second-stage SFT or the reinforcement learning (RL) for better fitting the target distribution. The superior empirical performance of Logics-STEM reveals the vast potential of combining large-scale open-source data with carefully designed synthetic data, underscoring the critical role of data-algorithm co-design in enhancing reasoning capabilities through post-training. We make both the Logics-STEM models (8B and 32B) and the Logics-STEM-SFT-Dataset (10M and downsampled 2.2M versions) publicly available to support future research in the open-source community.
Let It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
Dec 31, 2025Agentic crafting requires LLMs to operate in real-world environments over multiple turns by taking actions, observing outcomes, and iteratively refining artifacts. Despite its importance, the open-source community lacks a principled, end-to-end ecosystem to streamline agent development. We introduce the Agentic Learning Ecosystem (ALE), a foundational infrastructure that optimizes the production pipeline for agent LLMs. ALE consists of three components: ROLL, a post-training framework for weight optimization; ROCK, a sandbox environment manager for trajectory generation; and iFlow CLI, an agent framework for efficient context engineering. We release ROME (ROME is Obviously an Agentic Model), an open-source agent grounded by ALE and trained on over one million trajectories. Our approach includes data composition protocols for synthesizing complex behaviors and a novel policy optimization algorithm, Interaction-based Policy Alignment (IPA), which assigns credit over semantic interaction chunks rather than individual tokens to improve long-horizon training stability. Empirically, we evaluate ROME within a structured setting and introduce Terminal Bench Pro, a benchmark with improved scale and contamination control. ROME demonstrates strong performance across benchmarks like SWE-bench Verified and Terminal Bench, proving the effectiveness of the ALE infrastructure.
StructVRM: Aligning Multimodal Reasoning with Structured and Verifiable Reward Models
Aug 07, 2025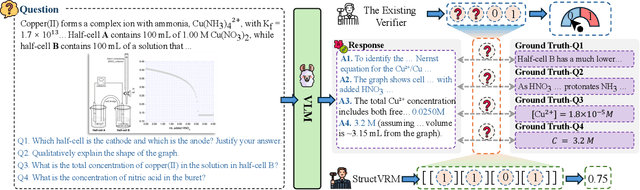

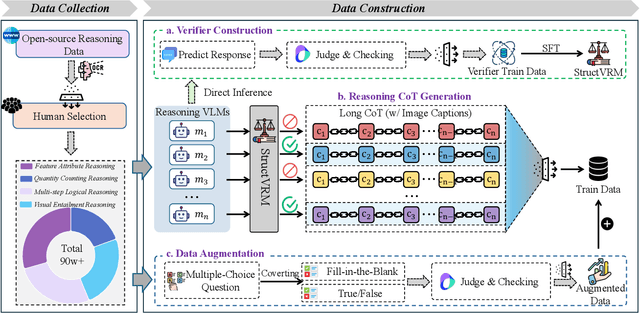
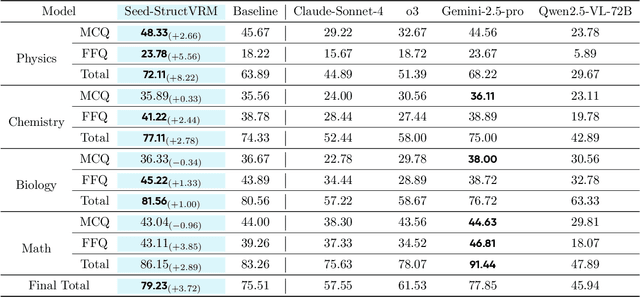
Existing Vision-Language Models often struggle with complex, multi-question reasoning tasks where partial correctness is crucial for effective learning. Traditional reward mechanisms, which provide a single binary score for an entire response, are too coarse to guide models through intricate problems with multiple sub-parts. To address this, we introduce StructVRM, a method that aligns multimodal reasoning with Structured and Verifiable Reward Models. At its core is a model-based verifier trained to provide fine-grained, sub-question-level feedback, assessing semantic and mathematical equivalence rather than relying on rigid string matching. This allows for nuanced, partial credit scoring in previously intractable problem formats. Extensive experiments demonstrate the effectiveness of StructVRM. Our trained model, Seed-StructVRM, achieves state-of-the-art performance on six out of twelve public multimodal benchmarks and our newly curated, high-difficulty STEM-Bench. The success of StructVRM validates that training with structured, verifiable rewards is a highly effective approach for advancing the capabilities of multimodal models in complex, real-world reasoning domains.
SafeGenBench: A Benchmark Framework for Security Vulnerability Detection in LLM-Generated Code
Jun 06, 2025The code generation capabilities of large language models(LLMs) have emerged as a critical dimension in evaluating their overall performance. However, prior research has largely overlooked the security risks inherent in the generated code. In this work, we introduce \benchmark, a benchmark specifically designed to assess the security of LLM-generated code. The dataset encompasses a wide range of common software development scenarios and vulnerability types. Building upon this benchmark, we develop an automatic evaluation framework that leverages both static application security testing(SAST) and LLM-based judging to assess the presence of security vulnerabilities in model-generated code. Through the empirical evaluation of state-of-the-art LLMs on \benchmark, we reveal notable deficiencies in their ability to produce vulnerability-free code. Our findings highlight pressing challenges and offer actionable insights for future advancements in the secure code generation performance of LLMs. The data and code will be released soon.
Infinite-Instruct: Synthesizing Scaling Code instruction Data with Bidirectional Synthesis and Static Verification
May 29, 2025Traditional code instruction data synthesis methods suffer from limited diversity and poor logic. We introduce Infinite-Instruct, an automated framework for synthesizing high-quality question-answer pairs, designed to enhance the code generation capabilities of large language models (LLMs). The framework focuses on improving the internal logic of synthesized problems and the quality of synthesized code. First, "Reverse Construction" transforms code snippets into diverse programming problems. Then, through "Backfeeding Construction," keywords in programming problems are structured into a knowledge graph to reconstruct them into programming problems with stronger internal logic. Finally, a cross-lingual static code analysis pipeline filters invalid samples to ensure data quality. Experiments show that on mainstream code generation benchmarks, our fine-tuned models achieve an average performance improvement of 21.70% on 7B-parameter models and 36.95% on 32B-parameter models. Using less than one-tenth of the instruction fine-tuning data, we achieved performance comparable to the Qwen-2.5-Coder-Instruct. Infinite-Instruct provides a scalable solution for LLM training in programming. We open-source the datasets used in the experiments, including both unfiltered versions and filtered versions via static analysis. The data are available at https://github.com/xingwenjing417/Infinite-Instruct-dataset
YUAN 2.0: A Large Language Model with Localized Filtering-based Attention
Dec 04, 2023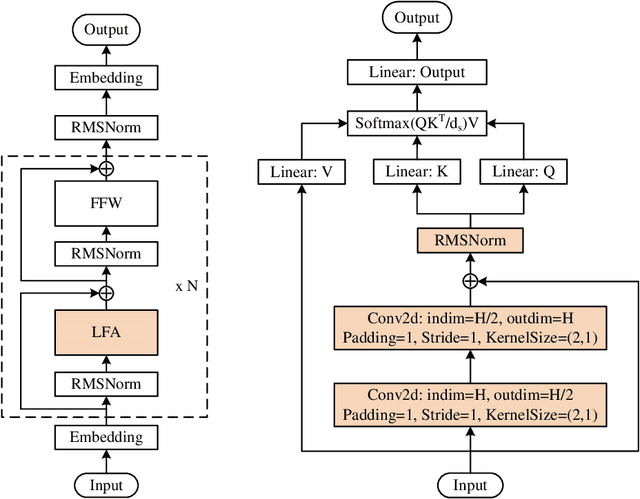

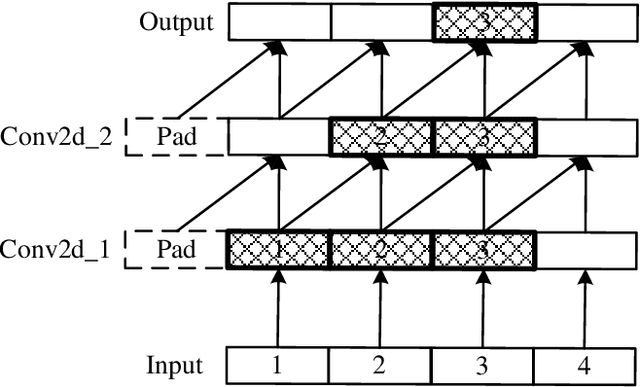
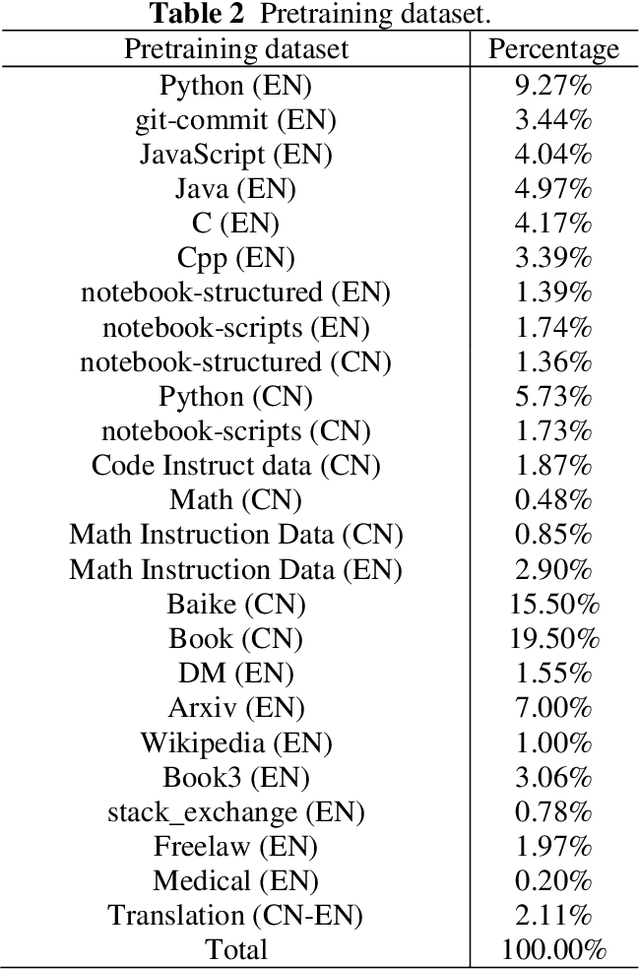
In this work, we develop and release Yuan 2.0, a series of large language models with parameters ranging from 2.1 billion to 102.6 billion. The Localized Filtering-based Attention (LFA) is introduced to incorporate prior knowledge of local dependencies of natural language into Attention. A data filtering and generating system is presented to build pre-training and fine-tuning dataset in high quality. A distributed training method with non-uniform pipeline parallel, data parallel, and optimizer parallel is proposed, which greatly reduces the bandwidth requirements of intra-node communication, and achieves good performance in large-scale distributed training. Yuan 2.0 models display impressive ability in code generation, math problem-solving, and chatting compared with existing models. The latest version of YUAN 2.0, including model weights and source code, is accessible at Github.