 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuan-TecSwin: A text conditioned Diffusion model with Swin-transformer blocks
Dec 18, 2025Diffusion models have shown remarkable capacity in image synthesis based on their U-shaped architecture and convolutional neural networks (CNN) as basic blocks. The locality of the convolution operation in CNN may limit the model's ability to understand long-range semantic information. To address this issue, we propose Yuan-TecSwin, a text-conditioned diffusion model with Swin-transformer in this work. The Swin-transformer blocks take the place of CNN blocks in the encoder and decoder, to improve the non-local modeling ability in feature extraction and image restoration. The text-image alignment is improved with a well-chosen text encoder, effective utilization of text embedding, and careful design in the incorporation of text condition. Using an adapted time step to search in different diffusion stages, inference performance is further improved by 10%. Yuan-TecSwin achieves the state-of-the-art FID score of 1.37 on ImageNet generation benchmark, without any additional models at different denoising stages. In a side-by-side comparison, we find it difficult for human interviewees to tell the model-generated images from the human-painted ones.
Energy-Efficient Split Learning for Fine-Tuning Large Language Models in Edge Networks
Nov 27, 2024



In this letter, we propose an energy-efficient split learning (SL) framework for fine-tuning large language models (LLMs) using geo-distributed personal data at the network edge, where LLMs are split and alternately across massive mobile devices and an edge server. Considering the device heterogeneity and channel dynamics in edge networks, a Cut lAyer and computing Resource Decision (CARD) algorithm is developed to minimize training delay and energy consumption. Simulation results demonstrate that the proposed approach reduces the average training delay and server's energy consumption by 70.8\% and 53.1\%, compared to the benchmarks, respectively.
SimpleBEV: Improved LiDAR-Camera Fusion Architecture for 3D Object Detection
Nov 08, 2024



More and more research works fuse the LiDAR and camera information to improve the 3D object detection of the autonomous driving system. Recently, a simple yet effective fusion framework has achieved an excellent detection performance, fusing the LiDAR and camera features in a unified bird's-eye-view (BEV) space. In this paper, we propose a LiDAR-camera fusion framework, named SimpleBEV, for accurate 3D object detection, which follows the BEV-based fusion framework and improves the camera and LiDAR encoders, respectively. Specifically, we perform the camera-based depth estimation using a cascade network and rectify the depth results with the depth information derived from the LiDAR points. Meanwhile, an auxiliary branch that implements the 3D object detection using only the camera-BEV features is introduced to exploit the camera information during the training phase. Besides, we improve the LiDAR feature extractor by fusing the multi-scaled sparse convolutional features. Experimental results demonstrate the effectiveness of our proposed method. Our method achieves 77.6\% NDS accuracy on the nuScenes dataset, showcasing superior performance in the 3D object detection track.
SimpleLLM4AD: An End-to-End Vision-Language Model with Graph Visual Question Answering for Autonomous Driving
Jul 31, 2024



Many fields could benefit from the rapid development of the large language models (LLMs). The end-to-end autonomous driving (e2eAD) is one of the typically fields facing new opportunities as the LLMs have supported more and more modalities. Here, by utilizing vision-language model (VLM), we proposed an e2eAD method called SimpleLLM4AD. In our method, the e2eAD task are divided into four stages, which are perception, prediction, planning, and behavior. Each stage consists of several visual question answering (VQA) pairs and VQA pairs interconnect with each other constructing a graph called Graph VQA (GVQA). By reasoning each VQA pair in the GVQA through VLM stage by stage, our method could achieve e2e driving with language. In our method, vision transformers (ViT) models are employed to process nuScenes visual data, while VLM are utilized to interpret and reason about the information extracted from the visual inputs. In the perception stage, the system identifies and classifies objects from the driving environment. The prediction stage involves forecasting the potential movements of these objects. The planning stage utilizes the gathered information to develop a driving strategy, ensuring the safety and efficiency of the autonomous vehicle. Finally, the behavior stage translates the planned actions into executable commands for the vehicle. Our experiments demonstrate that SimpleLLM4AD achieves competitive performance in complex driving scenarios.
Yuan 2.0-M32: Mixture of Experts with Attention Router
May 29, 2024



Yuan 2.0-M32, with a similar base architecture as Yuan-2.0 2B, uses a mixture-of-experts architecture with 32 experts of which 2 experts are active. A new router network, Attention Router, is proposed and adopted for a more efficient selection of experts, which improves the accuracy compared to the model with classical router network. Yuan 2.0-M32 is trained with 2000B tokens from scratch, and the training computation consumption is only 9.25% of a dense model at the same parameter scale. Yuan 2.0-M32 demonstrates competitive capability on coding, math, and various domains of expertise, with only 3.7B active parameters of 40B in total, and 7.4 GFlops forward computation per token, both of which are only 1/19 of Llama3-70B. Yuan 2.0-M32 surpass Llama3-70B on MATH and ARC-Challenge benchmark, with accuracy of 55.89 and 95.8 respectively. The models and source codes of Yuan 2.0-M32 are released at Github1.
Adaptive Split Learning over Energy-Constrained Wireless Edge Networks
Mar 08, 2024Split learning (SL) is a promising approach for training artificial intelligence (AI) models, in which devices collaborate with a server to train an AI model in a distributed manner, based on a same fixed split point. However, due to the device heterogeneity and variation of channel conditions, this way is not optimal in training delay and energy consumption. In this paper, we design an adaptive split learning (ASL) scheme which can dynamically select split points for devices and allocate computing resource for the server in wireless edge networks. We formulate an optimization problem to minimize the average training latency subject to long-term energy consumption constraint. The difficulties in solving this problem are the lack of future information and mixed integer programming (MIP). To solve it, we propose an online algorithm leveraging the Lyapunov theory, named OPEN, which decomposes it into a new MIP problem only with the current information. Then, a two-layer optimization method is proposed to solve the MIP problem. Extensive simulation results demonstrate that the ASL scheme can reduce the average training delay and energy consumption by 53.7% and 22.1%, respectively, as compared to the existing SL schemes.
YUAN 2.0: A Large Language Model with Localized Filtering-based Attention
Dec 04, 2023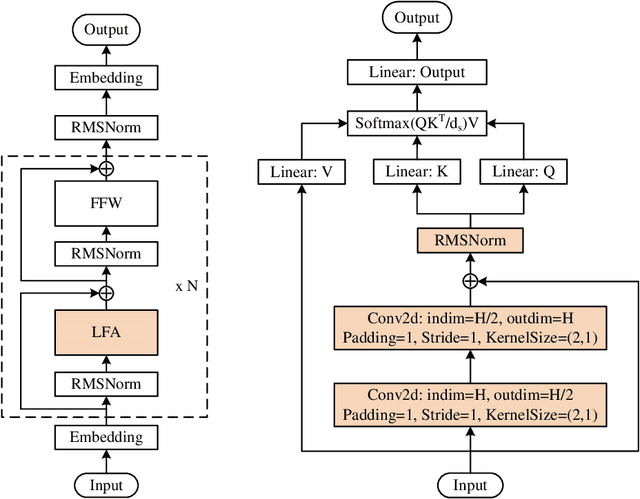

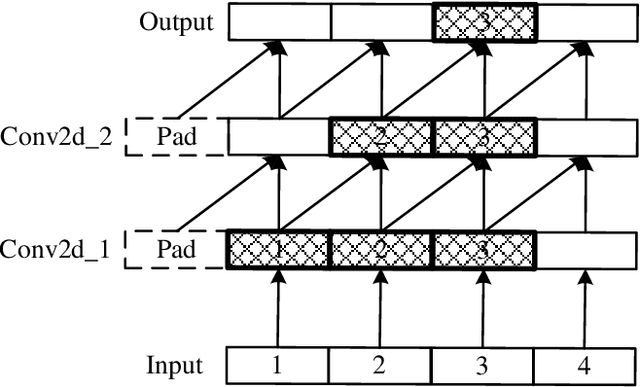
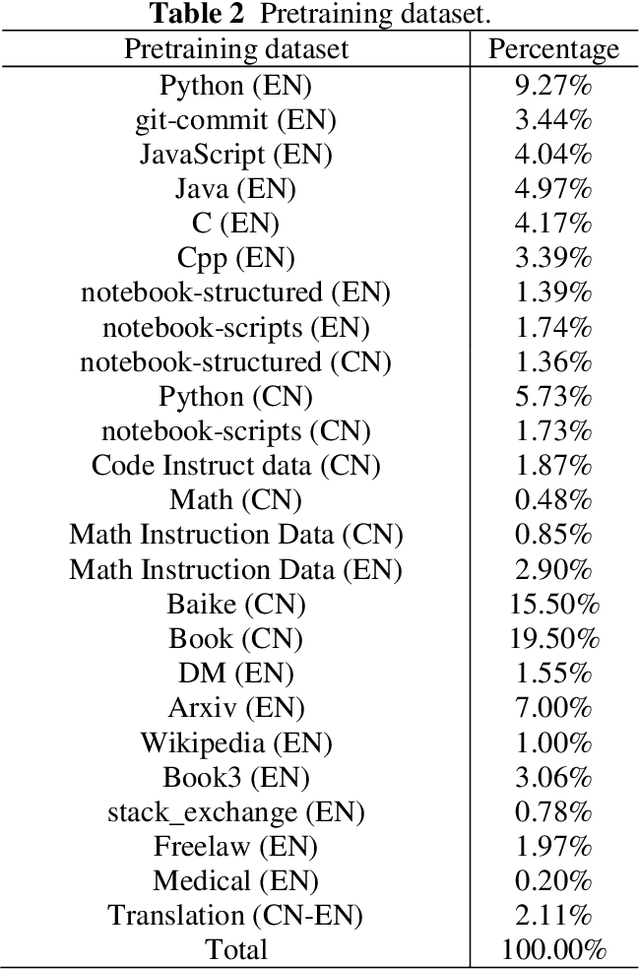
In this work, we develop and release Yuan 2.0, a series of large language models with parameters ranging from 2.1 billion to 102.6 billion. The Localized Filtering-based Attention (LFA) is introduced to incorporate prior knowledge of local dependencies of natural language into Attention. A data filtering and generating system is presented to build pre-training and fine-tuning dataset in high quality. A distributed training method with non-uniform pipeline parallel, data parallel, and optimizer parallel is proposed, which greatly reduces the bandwidth requirements of intra-node communication, and achieves good performance in large-scale distributed training. Yuan 2.0 models display impressive ability in code generation, math problem-solving, and chatting compared with existing models. The latest version of YUAN 2.0, including model weights and source code, is accessible at Github.
Goal-oriented Tensor: Beyond Age of Information Towards Semantics-Empowered Goal-Oriented Communications
Jul 02, 2023



Optimizations premised on open-loop metrics such as Age of Information (AoI) indirectly enhance the system's decision-making utility. We therefore propose a novel closed-loop metric named Goal-oriented Tensor (GoT) to directly quantify the impact of semantic mismatches on goal-oriented decision-making utility. Leveraging the GoT, we consider a sampler & decision-maker pair that works collaboratively and distributively to achieve a shared goal of communications. We formulate a two-agent infinite-horizon Decentralized Partially Observable Markov Decision Process (Dec-POMDP) to conjointly deduce the optimal deterministic sampling policy and decision-making policy. To circumvent the curse of dimensionality in obtaining an optimal deterministic joint policy through Brute-Force-Search, a sub-optimal yet computationally efficient algorithm is developed. This algorithm is predicated on the search for a Nash Equilibrium between the sampler and the decision-maker. Simulation results reveal that the proposed sampler & decision-maker co-design surpasses the current literature on AoI and its variants in terms of both goal achievement utility and sparse sampling rate, signifying progress in the semantics-conscious, goal-driven sparse sampling design.
Deep Reinforcement Learning-Assisted Age-optimal Transmission Policy for HARQ-aided NOMA Networks
Apr 16, 2023



The recent interweaving of AI-6G technologies has sparked extensive research interest in further enhancing reliable and timely communications. \emph{Age of Information} (AoI), as a novel and integrated metric implying the intricate trade-offs among reliability, latency, and update frequency, has been well-researched since its conception. This paper contributes new results in this area by employing a Deep Reinforcement Learning (DRL) approach to intelligently decide how to allocate power resources and when to retransmit in a \emph{freshness-sensitive} downlink multi-user Hybrid Automatic Repeat reQuest with Chase Combining (HARQ-CC) aided Non-Orthogonal Multiple Access (NOMA) network. Specifically, an AoI minimization problem is formulated as a Markov Decision Process (MDP) problem. Then, to achieve deterministic, age-optimal, and intelligent power allocations and retransmission decisions, the Double-Dueling-Deep Q Network (DQN) is adopted. Furthermore, a more flexible retransmission scheme, referred to as Retransmit-At-Will scheme, is proposed to further facilitate the timeliness of the HARQ-aided NOMA network. Simulation results verify the superiority of the proposed intelligent scheme and demonstrate the threshold structure of the retransmission policy. Also, answers to whether user pairing is necessary are discussed by extensive simulation results.
Yuan 1.0: Large-Scale Pre-trained Language Model in Zero-Shot and Few-Shot Learning
Oct 12, 2021

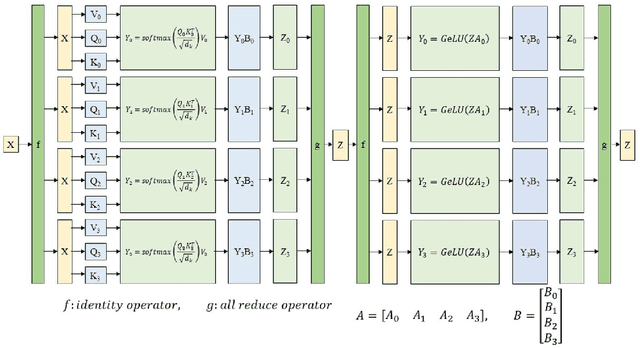

Recent work like GPT-3 has demonstrated excellent performance of Zero-Shot and Few-Shot learning on many natural language processing (NLP) tasks by scaling up model size, dataset size and the amount of computation. However, training a model like GPT-3 requires huge amount of computational resources which makes it challengeable to researchers. In this work, we propose a method that incorporates large-scale distributed training performance into model architecture design. With this method, Yuan 1.0, the current largest singleton language model with 245B parameters, achieves excellent performance on thousands GPUs during training, and the state-of-the-art results on NLP tasks. A data processing method is designed to efficiently filter massive amount of raw data. The current largest high-quality Chinese corpus with 5TB high quality texts is built based on this method. In addition, a calibration and label expansion method is proposed to improve the Zero-Shot and Few-Shot performance, and steady improvement is observed on the accuracy of various tasks. Yuan 1.0 presents strong capacity of natural language generation, and the generated articles are difficult to distinguish from the human-written ones.