 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoF Analysis and Beamforming Design for Active IRS-aided Multi-user MIMO Wireless Communication in Rank-deficient Channels
Nov 13, 2024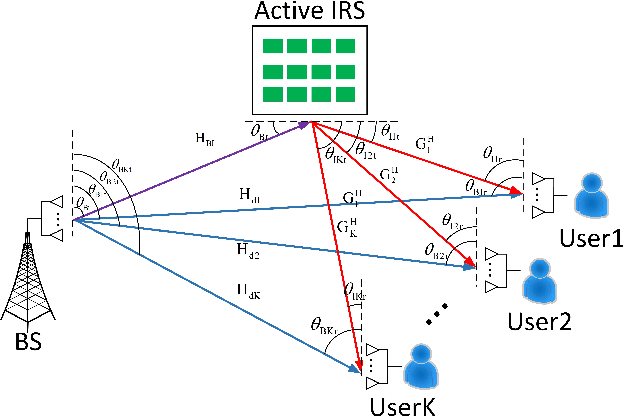
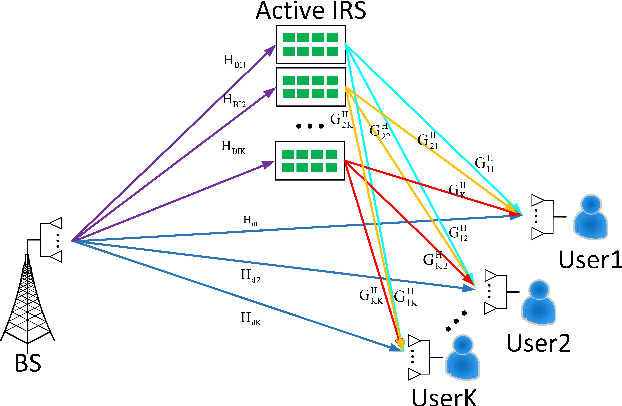
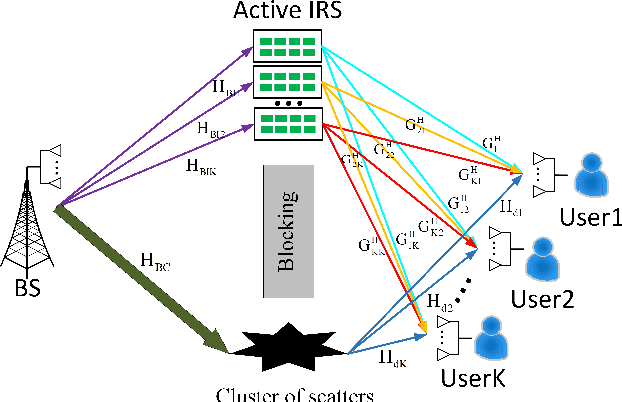
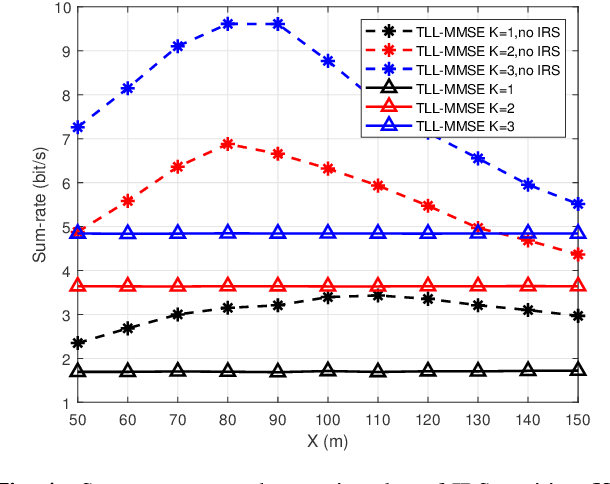
Due to its ability of significantly improving data rate, intelligent reflecting surface (IRS) will be a potential crucial technique for the future generation wireless networks like 6G. In this paper, we will focus on the analysis of degree of freedom (DoF) in IRS-aided multi-user MIMO network. Firstly, the DoF upper bound of IRS-aided single-user MIMO network, i.e., the achievable maximum DoF of such a system, is derived, and the corresponding results are extended to the case of IRS-aided multiuser MIMO by using the matrix rank inequalities. In particular, in serious rank-deficient, also called low-rank, channels like line-of-sight (LoS), the network DoF may doubles over no-IRS with the help of IRS. To verify the rate performance gain from augmented DoF, three closed-form beamforming methods, null-space projection plus maximize transmit power and maximize receive power (NSP-MTP-MRP), Schmidt orthogonalization plus minimum mean square error (SO-MMSE) and two-layer leakage plus MMSE (TLL-MMSE) are proposed to achieve the maximum DoF. Simulation results shows that IRS does make a dramatic rate enhancement. For example, in a serious deficient channel, the sum-rate of the proposed TLL-MMSE aided by IRS is about twice that of no IRS. This means that IRS may achieve a significant DoF improvement in such a channel.
Plausible-Parrots @ MSP2023: Enhancing Semantic Plausibility Modeling using Entity and Event Knowledge
Aug 29, 2024



In this work, we investigate the effectiveness of injecting external knowledge to a large language model (LLM) to identify semantic plausibility of simple events. Specifically, we enhance the LLM with fine-grained entity types, event types and their definitions extracted from an external knowledge base. These knowledge are injected into our system via designed templates. We also augment the data to balance the label distribution and adapt the task setting to real world scenarios in which event mentions are expressed as natural language sentences. The experimental results show the effectiveness of the injected knowledge on modeling semantic plausibility of events. An error analysis further emphasizes the importance of identifying non-trivial entity and event types.
Yuan 2.0-M32: Mixture of Experts with Attention Router
May 29, 2024Yuan 2.0-M32, with a similar base architecture as Yuan-2.0 2B, uses a mixture-of-experts architecture with 32 experts of which 2 experts are active. A new router network, Attention Router, is proposed and adopted for a more efficient selection of experts, which improves the accuracy compared to the model with classical router network. Yuan 2.0-M32 is trained with 2000B tokens from scratch, and the training computation consumption is only 9.25% of a dense model at the same parameter scale. Yuan 2.0-M32 demonstrates competitive capability on coding, math, and various domains of expertise, with only 3.7B active parameters of 40B in total, and 7.4 GFlops forward computation per token, both of which are only 1/19 of Llama3-70B. Yuan 2.0-M32 surpass Llama3-70B on MATH and ARC-Challenge benchmark, with accuracy of 55.89 and 95.8 respectively. The models and source codes of Yuan 2.0-M32 are released at Github1.
Precoding and Beamforming Design for Intelligent Reconfigurable Surface-Aided Hybrid Secure Spatial Modulation
Feb 15, 2023Intelligent reflecting surface (IRS) is an emerging technology for wireless communication composed of a large number of low-cost passive devices with reconfigurable parameters, which can reflect signals with a certain phase shift and is capable of building programmable communication environment. In this paper, to avoid the high hardware cost and energy consumption in spatial modulation (SM), an IRS-aided hybrid secure SM (SSM) system with a hybrid precoder is proposed. To improve the security performance, we formulate an optimization problem to maximize the secrecy rate (SR) by jointly optimizing the beamforming at IRS and hybrid precoding at the transmitter. Considering that the SR has no closed form expression, an approximate SR (ASR) expression is derived as the objective function. To improve the SR performance, three IRS beamforming methods, called IRS alternating direction method of multipliers (IRS-ADMM), IRS block coordinate ascend (IRS-BCA) and IRS semi-definite relaxation (IRS-SDR), are proposed. As for the hybrid precoding design, approximated secrecy rate-successive convex approximation (ASR-SCA) method and cut-off rate-gradient ascend (COR-GA) method are proposed. Simulation results demonstrate that the proposed IRS-SDR and IRS-ADMM beamformers harvest substantial SR performance gains over IRS-BCA. Particularly, the proposed IRS-ADMM and IRS-BCA are of low-complexity at the expense of a little performance loss compared with IRS-SDR. For hybrid precoding, the proposed ASR-SCA performs better than COR-GA in the high transmit power region.
Yuan 1.0: Large-Scale Pre-trained Language Model in Zero-Shot and Few-Shot Learning
Oct 12, 2021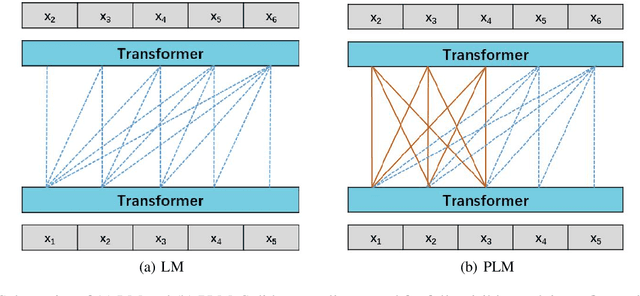

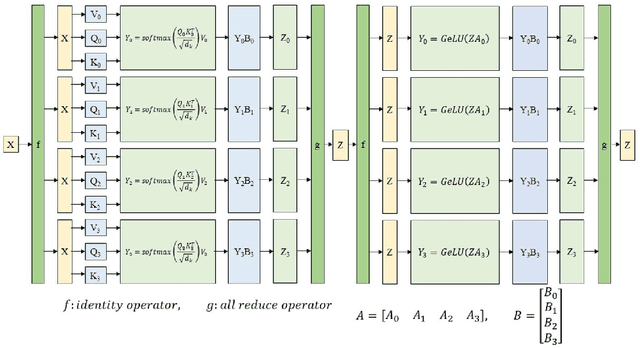

Recent work like GPT-3 has demonstrated excellent performance of Zero-Shot and Few-Shot learning on many natural language processing (NLP) tasks by scaling up model size, dataset size and the amount of computation. However, training a model like GPT-3 requires huge amount of computational resources which makes it challengeable to researchers. In this work, we propose a method that incorporates large-scale distributed training performance into model architecture design. With this method, Yuan 1.0, the current largest singleton language model with 245B parameters, achieves excellent performance on thousands GPUs during training, and the state-of-the-art results on NLP tasks. A data processing method is designed to efficiently filter massive amount of raw data. The current largest high-quality Chinese corpus with 5TB high quality texts is built based on this method. In addition, a calibration and label expansion method is proposed to improve the Zero-Shot and Few-Shot performance, and steady improvement is observed on the accuracy of various tasks. Yuan 1.0 presents strong capacity of natural language generation, and the generated articles are difficult to distinguish from the human-written ones.