 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAR: Semantic-Temporal Adaptive Representation Learning for Few-Shot Action Recognition
May 13, 2026Few-shot action recognition (FSAR) requires models to generalize to novel action categories from only a handful of annotated samples. Despite progress with vision-language models, existing approaches still suffer from semantic-temporal misalignment, where static textual prompts fail to capture decisive visual cues that appear sparsely across sequences, and from inadequate modeling of multi-scale temporal dynamics, as short-term discriminative cues and long-range dependencies are often either oversmoothed or fragmented. To address these challenges, we propose Semantic Temporal Adaptive Representation Learning (STAR), a unified framework, consisting of a semantic-alignment component and a temporal-aware component, effectively bridging the semantic and temporal gaps and transferring the sequence modeling capability of Mamba into the FSAR. The semantic alignment module introduces a Temporal Semantic Attention (TSA) mechanism, which performs frame-level cross-modal alignment with textual cues, ensuring fine-grained semantic-temporal consistency. The temporal-aware module incorporates a Semantic Temporal Prototype Refiner (STPR) that integrates semantic-guided Mamba blocks with multi-frequency temporal sampling and bidirectional state-space refinement, yielding semantically aligned prototypes with enhanced discriminative fidelity and temporal consistency. Furthermore, temporally dependent class descriptors derived from large language models (LLMs) provide long-range semantic guidance. Extensive experiments on five FSAR benchmarks demonstrate the consistent superiority of STAR over state-of-the-art methods. For instance, STAR achieves up to 8.1% and 6.7% gains on the SSv2-Full and SSv2-Small datasets under the 1-shot setting, and 7.3% on HMDB51, validating its effectiveness under limited supervision. The code is available at https://github.com/HongliLiu1/STAR-main.
Fairness-Aware Beamforming for Polarimetric ISAC Systems with Polarization-Reconfigurable Antennas
Mar 18, 2026Polarization diversity offers significant flexibility for enhancing integrated sensing and communications (ISAC). However, conventional dual-polarized arrays typically require dedicated radio-frequency (RF) chains for each polarization branch, leading to prohibitive hardware costs. To address this, polarization-reconfigurable (PR) antennas have emerged as a cost-effective alternative, enabling polarization flexibility with reduced hardware complexity by driving two polarization branches with a single RF chain. In this paper, we investigate fairness-aware beamforming for ISAC systems equipped with PR antennas. Specifically, we jointly optimize the transmit beamforming and PR control coefficients to maximize the minimum signal-to-interference-plus-noise ratio (SINR) for communication users and the minimum signal-to-clutter-plus-noise ratio (SCNR) for sensing targets. The resulting problem is highly nonconvex and nonsmooth due to the strong coupling among optimization variables in the max-min objective, as well as the nonconvex spherical constraints imposed by the PR antennas. To tackle this, we derive an equivalent smooth reformulation by introducing auxiliary variables and transforming the minimum operators into inequality constraints. Subsequently, we develop an exact-penalty product Riemannian manifold gradient descent (EP-PRMGD) algorithm, which integrates an exact penalty method with Riemannian optimization to guarantee convergence to a Karush-Kuhn-Tucker (KKT) point. Numerical results demonstrate that the proposed PR-enabled ISAC scheme achieves performance comparable to dual-polarized architectures while utilizing only half the RF chains, thereby validating its effectiveness in balancing fairness and hardware efficiency.
Low-Cost Physical-Layer Security Design for IRS-Assisted mMIMO Systems with One-Bit DACs
Feb 15, 2026Integrating massive multiple-input multiple-output (mMIMO) systems with intelligent reflecting surfaces (IRS) presents a promising paradigm for enhancing physical-layer security (PLS) in wireless communications. However, deploying high-resolution quantizers in large-scale mMIMO arrays, along with numerous IRS elements, leads to substantial hardware complexity. To address these challenges, this paper proposes a cost-effective PLS design for IRS-assisted mMIMO systems by employing one-bit digital-to-analog converters (DACs). The focus is on jointly optimizing one-bit quantized precoding at the transmitter and constant-modulus phase shifts at the IRS to maximize the secrecy rate. This leads to a highly non-convex fractional secrecy rate maximization (SRM) problem. To efficiently solve this problem, two algorithms are proposed: (1) the WMMSE-PDD algorithm, which reformulates the SRM problem into a sequence of non-fractional programs with auxiliary variables using the weighted minimum mean-square error (WMMSE) method and solves them via the penalty dual decomposition (PDD) approach, achieving superior secrecy performance; and (2) the exact penalty product Riemannian gradient descent (EPPRGD) algorithm, which transforms the SRM problem into an unconstrained optimization over a product Riemannian manifold, eliminating auxiliary variables and enabling faster convergence with a slight trade-off in secrecy performance. Both algorithms provide analytical solutions at each iteration and are proven to converge to Karush-Kuhn-Tucker (KKT) points. Simulation results confirm the effectiveness of the proposed methods and highlight their respective advantages.
Domain Generalization for Cross-Receiver Radio Frequency Fingerprint Identification
Nov 06, 2024



Radio Frequency Fingerprint Identification (RFFI) technology uniquely identifies emitters by analyzing unique distortions in the transmitted signal caused by non-ideal hardware. Recently, RFFI based on deep learning methods has gained popularity and is seen as a promising way to address the device authentication problem for Internet of Things (IoT) systems. However, in cross-receiver scenarios, where the RFFI model is trained over RF signals from some receivers but deployed at a new receiver, the alteration of receivers' characteristics would lead to data distribution shift and cause significant performance degradation at the new receiver. To address this problem, we first perform a theoretical analysis of the cross-receiver generalization error bound and propose a sufficient condition, named Separable Condition (SC), to minimize the classification error probability on the new receiver. Guided by the SC, a Receiver-Independent Emitter Identification (RIEI)model is devised to decouple the received signals into emitter-related features and receiver-related features and only the emitter-related features are used for identification. Furthermore, by leveraging federated learning, we also develop a FedRIEI model to eliminate the need for centralized collection of raw data from multiple receivers. Experiments on two real-world datasets demonstrate the superiority of our proposed methods over some baseline methods.
CAT: LoCalization and IdentificAtion Cascade Detection Transformer for Open-World Object Detection
Jan 05, 2023



Open-world object detection (OWOD), as a more general and challenging goal, requires the model trained from data on known objects to detect both known and unknown objects and incrementally learn to identify these unknown objects. The existing works which employ standard detection framework and fixed pseudo-labelling mechanism (PLM) have the following problems: (i) The inclusion of detecting unknown objects substantially reduces the model's ability to detect known ones. (ii) The PLM does not adequately utilize the priori knowledge of inputs. (iii) The fixed selection manner of PLM cannot guarantee that the model is trained in the right direction. We observe that humans subconsciously prefer to focus on all foreground objects and then identify each one in detail, rather than localize and identify a single object simultaneously, for alleviating the confusion. This motivates us to propose a novel solution called CAT: LoCalization and IdentificAtion Cascade Detection Transformer which decouples the detection process via the shared decoder in the cascade decoding way. In the meanwhile, we propose the self-adaptive pseudo-labelling mechanism which combines the model-driven with input-driven PLM and self-adaptively generates robust pseudo-labels for unknown objects, significantly improving the ability of CAT to retrieve unknown objects. Comprehensive experiments on two benchmark datasets, i.e., MS-COCO and PASCAL VOC, show that our model outperforms the state-of-the-art in terms of all metrics in the task of OWOD, incremental object detection (IOD) and open-set detection.
Yuan 1.0: Large-Scale Pre-trained Language Model in Zero-Shot and Few-Shot Learning
Oct 12, 2021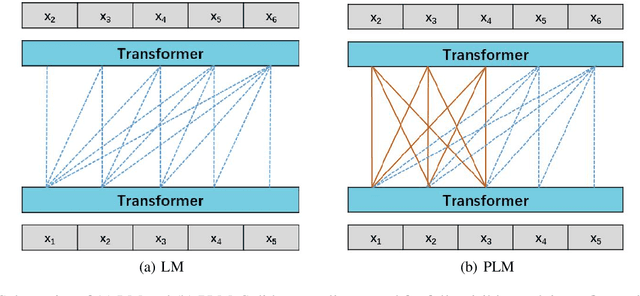

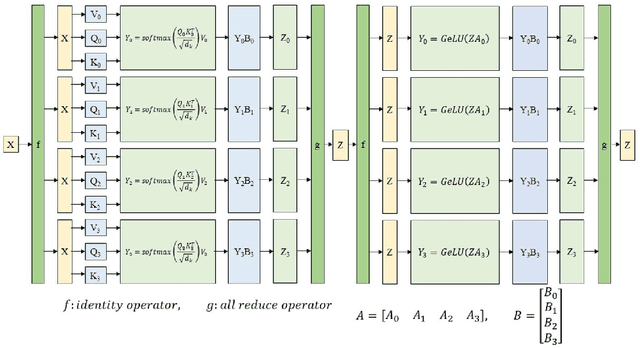

Recent work like GPT-3 has demonstrated excellent performance of Zero-Shot and Few-Shot learning on many natural language processing (NLP) tasks by scaling up model size, dataset size and the amount of computation. However, training a model like GPT-3 requires huge amount of computational resources which makes it challengeable to researchers. In this work, we propose a method that incorporates large-scale distributed training performance into model architecture design. With this method, Yuan 1.0, the current largest singleton language model with 245B parameters, achieves excellent performance on thousands GPUs during training, and the state-of-the-art results on NLP tasks. A data processing method is designed to efficiently filter massive amount of raw data. The current largest high-quality Chinese corpus with 5TB high quality texts is built based on this method. In addition, a calibration and label expansion method is proposed to improve the Zero-Shot and Few-Shot performance, and steady improvement is observed on the accuracy of various tasks. Yuan 1.0 presents strong capacity of natural language generation, and the generated articles are difficult to distinguish from the human-written ones.
Multi-view Face Analysis Based on Gabor Features
Mar 06, 2014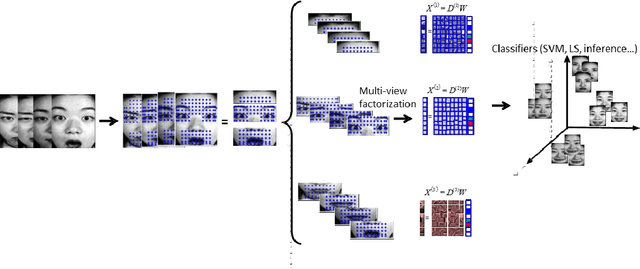
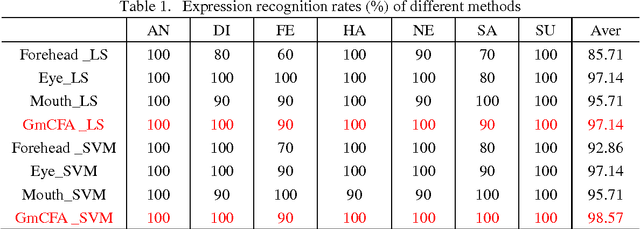


Facial analysis has attracted much attention in the technology for human-machine interface. Different methods of classification based on sparse representation and Gabor kernels have been widely applied in the fields of facial analysis. However, most of these methods treat face from a whole view standpoint. In terms of the importance of different facial views, in this paper, we present multi-view face analysis based on sparse representation and Gabor wavelet coefficients. To evaluate the performance, we conduct face analysis experiments including face recognition (FR) and face expression recognition (FER) on JAFFE database. Experiments are conducted from two parts: (1) Face images are divided into three facial parts which are forehead, eye and mouth. (2) Face images are divided into 8 parts by the orientation of Gabor kernels. Experimental results demonstrate that the proposed methods can significantly boost the performance and perform better than the other methods.
* 8 pages, 3 figures, Journal of Information and Computational Science