 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Let a Few Network Failures Slow the Entire AllReduce
Jun 01, 2026Network failures are among the most frequent hardware faults in large-scale GPU clusters and a leading cause of training-job interruptions. Modern collective communication libraries such as NCCL mitigate network failures by rerouting traffic through surviving NICs on the same server, trading reduced inter-node bandwidth for uninterrupted training. However, the degraded server remains on the critical path of the standard ring algorithm, slowing the entire collective. We present the first information-theoretic lower bound on AllReduce completion time under asymmetric network bandwidth and show that when the straggler retains at least half of its original bandwidth, the unavoidable overhead relative to the fault-free optimum is only O(1/p) for p GPUs. We then design OptCC, a four-stage pipelined AllReduce algorithm that approaches this lower bound. Experiments on SimAI confirm that OptCC closes the gap left by existing fault-tolerant schemes: under practical network failures with up to 50% bandwidth loss, OptCC completes AllReduce within 2-6% of NCCL's fault-free ring performance, whereas the state-of-the-art incurs up to 57% overhead.
Automated Conjecture Resolution with Formal Verification
Apr 04, 2026Recent advances in large language models have significantly improved their ability to perform mathematical reasoning, extending from elementary problem solving to increasingly capable performance on research-level problems. However, reliably solving and verifying such problems remains challenging due to the inherent ambiguity of natural language reasoning. In this paper, we propose an automated framework for tackling research-level mathematical problems that integrates natural language reasoning with formal verification, enabling end-to-end problem solving with minimal human intervention. Our framework consists of two components: an informal reasoning agent, Rethlas, and a formal verification agent, Archon. Rethlas mimics the workflow of human mathematicians by combining reasoning primitives with our theorem search engine, Matlas, to explore solution strategies and construct candidate proofs. Archon, equipped with our formal theorem search engine LeanSearch, translates informal arguments into formalized Lean 4 projects through structured task decomposition, iterative refinement, and automated proof synthesis, ensuring machine-checkable correctness. Using this framework, we automatically resolve an open problem in commutative algebra and formally verify the resulting proof in Lean 4 with essentially no human involvement. Our experiments demonstrate that strong theorem retrieval tools enable the discovery and application of cross-domain mathematical techniques, while the formal agent is capable of autonomously filling nontrivial gaps in informal arguments. More broadly, our work illustrates a promising paradigm for mathematical research in which informal and formal reasoning systems, equipped with theorem retrieval tools, operate in tandem to produce verifiable results, substantially reduce human effort, and offer a concrete instantiation of human-AI collaborative mathematical research.
A Simple Knowledge Distillation Framework for Open-world Object Detection
Dec 14, 2023Open World Object Detection (OWOD) is a novel computer vision task with a considerable challenge, bridging the gap between classic object detection (OD) benchmarks and real-world object detection. In addition to detecting and classifying seen/known objects, OWOD algorithms are expected to localize all potential unseen/unknown objects and incrementally learn them. The large pre-trained vision-language grounding models (VLM,eg, GLIP) have rich knowledge about the open world, but are limited by text prompts and cannot localize indescribable objects. However, there are many detection scenarios which pre-defined language descriptions are unavailable during inference. In this paper, we attempt to specialize the VLM model for OWOD task by distilling its open-world knowledge into a language-agnostic detector. Surprisingly, we observe that the combination of a simple knowledge distillation approach and the automatic pseudo-labeling mechanism in OWOD can achieve better performance for unknown object detection, even with a small amount of data. Unfortunately, knowledge distillation for unknown objects severely affects the learning of detectors with conventional structures for known objects, leading to catastrophic forgetting. To alleviate these problems, we propose the down-weight loss function for knowledge distillation from vision-language to single vision modality. Meanwhile, we decouple the learning of localization and recognition to reduce the impact of category interactions of known and unknown objects on the localization learning process. Comprehensive experiments performed on MS-COCO and PASCAL VOC demonstrate the effectiveness of our methods.
Detecting the open-world objects with the help of the Brain
Mar 21, 2023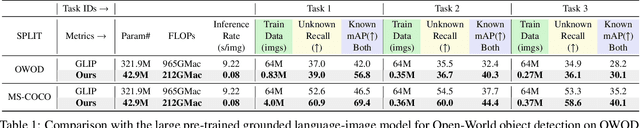
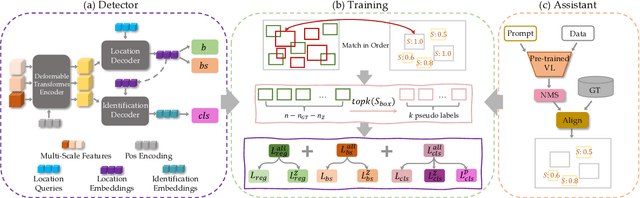
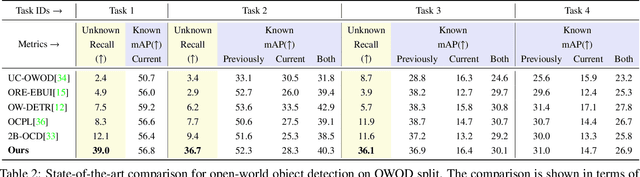
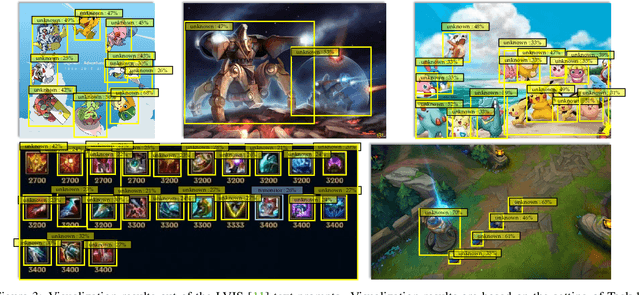
Open World Object Detection (OWOD) is a novel computer vision task with a considerable challenge, bridging the gap between classic object detection (OD) benchmarks and real-world object detection. In addition to detecting and classifying seen/known objects, OWOD algorithms are expected to detect unseen/unknown objects and incrementally learn them. The natural instinct of humans to identify unknown objects in their environments mainly depends on their brains' knowledge base. It is difficult for a model to do this only by learning from the annotation of several tiny datasets. The large pre-trained grounded language-image models - VL (\ie GLIP) have rich knowledge about the open world but are limited to the text prompt. We propose leveraging the VL as the ``Brain'' of the open-world detector by simply generating unknown labels. Leveraging it is non-trivial because the unknown labels impair the model's learning of known objects. In this paper, we alleviate these problems by proposing the down-weight loss function and decoupled detection structure. Moreover, our detector leverages the ``Brain'' to learn novel objects beyond VL through our pseudo-labeling scheme.
FGAHOI: Fine-Grained Anchors for Human-Object Interaction Detection
Jan 08, 2023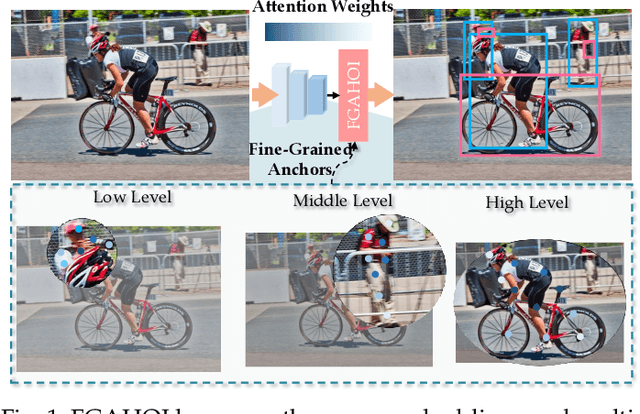



Human-Object Interaction (HOI), as an important problem in computer vision, requires locating the human-object pair and identifying the interactive relationships between them. The HOI instance has a greater span in spatial, scale, and task than the individual object instance, making its detection more susceptible to noisy backgrounds. To alleviate the disturbance of noisy backgrounds on HOI detection, it is necessary to consider the input image information to generate fine-grained anchors which are then leveraged to guide the detection of HOI instances. However, it is challenging for the following reasons. i) how to extract pivotal features from the images with complex background information is still an open question. ii) how to semantically align the extracted features and query embeddings is also a difficult issue. In this paper, a novel end-to-end transformer-based framework (FGAHOI) is proposed to alleviate the above problems. FGAHOI comprises three dedicated components namely, multi-scale sampling (MSS), hierarchical spatial-aware merging (HSAM) and task-aware merging mechanism (TAM). MSS extracts features of humans, objects and interaction areas from noisy backgrounds for HOI instances of various scales. HSAM and TAM semantically align and merge the extracted features and query embeddings in the hierarchical spatial and task perspectives in turn. In the meanwhile, a novel training strategy Stage-wise Training Strategy is designed to reduce the training pressure caused by overly complex tasks done by FGAHOI. In addition, we propose two ways to measure the difficulty of HOI detection and a novel dataset, i.e., HOI-SDC for the two challenges (Uneven Distributed Area in Human-Object Pairs and Long Distance Visual Modeling of Human-Object Pairs) of HOI instances detection.
CAT: LoCalization and IdentificAtion Cascade Detection Transformer for Open-World Object Detection
Jan 05, 2023



Open-world object detection (OWOD), as a more general and challenging goal, requires the model trained from data on known objects to detect both known and unknown objects and incrementally learn to identify these unknown objects. The existing works which employ standard detection framework and fixed pseudo-labelling mechanism (PLM) have the following problems: (i) The inclusion of detecting unknown objects substantially reduces the model's ability to detect known ones. (ii) The PLM does not adequately utilize the priori knowledge of inputs. (iii) The fixed selection manner of PLM cannot guarantee that the model is trained in the right direction. We observe that humans subconsciously prefer to focus on all foreground objects and then identify each one in detail, rather than localize and identify a single object simultaneously, for alleviating the confusion. This motivates us to propose a novel solution called CAT: LoCalization and IdentificAtion Cascade Detection Transformer which decouples the detection process via the shared decoder in the cascade decoding way. In the meanwhile, we propose the self-adaptive pseudo-labelling mechanism which combines the model-driven with input-driven PLM and self-adaptively generates robust pseudo-labels for unknown objects, significantly improving the ability of CAT to retrieve unknown objects. Comprehensive experiments on two benchmark datasets, i.e., MS-COCO and PASCAL VOC, show that our model outperforms the state-of-the-art in terms of all metrics in the task of OWOD, incremental object detection (IOD) and open-set detection.
Discriminative-Region Attention and Orthogonal-View Generation Model for Vehicle Re-Identification
Apr 28, 2022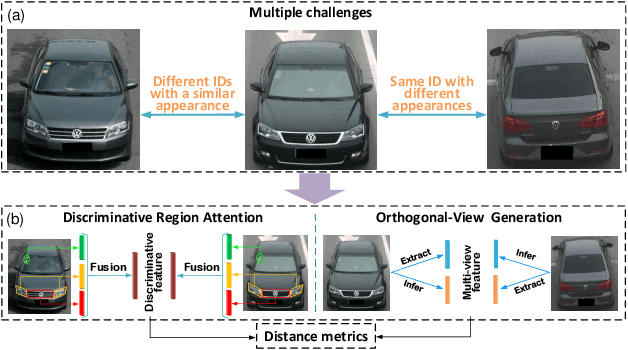


Vehicle re-identification (Re-ID) is urgently demanded to alleviate thepressure caused by the increasingly onerous task of urban traffic management. Multiple challenges hamper the applications of vision-based vehicle Re-ID methods: (1) The appearances of different vehicles of the same brand/model are often similar; However, (2) the appearances of the same vehicle differ significantly from different viewpoints. Previous methods mainly use manually annotated multi-attribute datasets to assist the network in getting detailed cues and in inferencing multi-view to improve the vehicle Re-ID performance. However, finely labeled vehicle datasets are usually unattainable in real application scenarios. Hence, we propose a Discriminative-Region Attention and Orthogonal-View Generation (DRA-OVG) model, which only requires identity (ID) labels to conquer the multiple challenges of vehicle Re-ID.The proposed DRA model can automatically extract the discriminative region features, which can distinguish similar vehicles. And the OVG model can generate multi-view features based on the input view features to reduce the impact of viewpoint mismatches. Finally, the distance between vehicle appearances is presented by the discriminative region features and multi-view features together. Therefore, the significance of pairwise distance measure between vehicles is enhanced in acomplete feature space. Extensive experiments substantiate the effectiveness of each proposed ingredient, and experimental results indicate that our approach achieves remarkable improvements over the state- of-the-art vehicle Re-ID methods on VehicleID and VeRi-776 datasets.