 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DFlowAction: Learning Cross-Embodiment Manipulation from 3D Flow World Model
Jun 06, 2025Manipulation has long been a challenging task for robots, while humans can effortlessly perform complex interactions with objects, such as hanging a cup on the mug rack. A key reason is the lack of a large and uniform dataset for teaching robots manipulation skills. Current robot datasets often record robot action in different action spaces within a simple scene. This hinders the robot to learn a unified and robust action representation for different robots within diverse scenes. Observing how humans understand a manipulation task, we find that understanding how the objects should move in the 3D space is a critical clue for guiding actions. This clue is embodiment-agnostic and suitable for both humans and different robots. Motivated by this, we aim to learn a 3D flow world model from both human and robot manipulation data. This model predicts the future movement of the interacting objects in 3D space, guiding action planning for manipulation. Specifically, we synthesize a large-scale 3D optical flow dataset, named ManiFlow-110k, through a moving object auto-detect pipeline. A video diffusion-based world model then learns manipulation physics from these data, generating 3D optical flow trajectories conditioned on language instructions. With the generated 3D object optical flow, we propose a flow-guided rendering mechanism, which renders the predicted final state and leverages GPT-4o to assess whether the predicted flow aligns with the task description. This equips the robot with a closed-loop planning ability. Finally, we consider the predicted 3D optical flow as constraints for an optimization policy to determine a chunk of robot actions for manipulation. Extensive experiments demonstrate strong generalization across diverse robotic manipulation tasks and reliable cross-embodiment adaptation without hardware-specific training.
Enhancing User-Oriented Proactivity in Open-Domain Dialogues with Critic Guidance
May 18, 2025
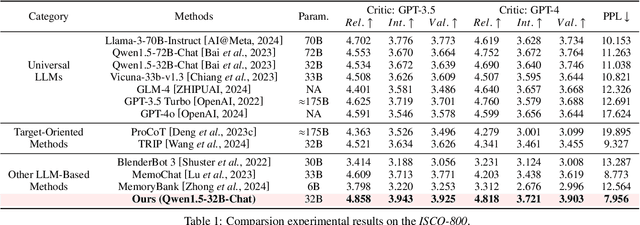
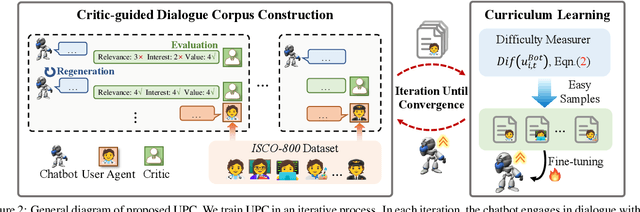

Open-domain dialogue systems aim to generate natural and engaging conversations, providing significant practical value in real applications such as social robotics and personal assistants. The advent of large language models (LLMs) has greatly advanced this field by improving context understanding and conversational fluency. However, existing LLM-based dialogue systems often fall short in proactively understanding the user's chatting preferences and guiding conversations toward user-centered topics. This lack of user-oriented proactivity can lead users to feel unappreciated, reducing their satisfaction and willingness to continue the conversation in human-computer interactions. To address this issue, we propose a User-oriented Proactive Chatbot (UPC) to enhance the user-oriented proactivity. Specifically, we first construct a critic to evaluate this proactivity inspired by the LLM-as-a-judge strategy. Given the scarcity of high-quality training data, we then employ the critic to guide dialogues between the chatbot and user agents, generating a corpus with enhanced user-oriented proactivity. To ensure the diversity of the user backgrounds, we introduce the ISCO-800, a diverse user background dataset for constructing user agents. Moreover, considering the communication difficulty varies among users, we propose an iterative curriculum learning method that trains the chatbot from easy-to-communicate users to more challenging ones, thereby gradually enhancing its performance. Experiments demonstrate that our proposed training method is applicable to different LLMs, improving user-oriented proactivity and attractiveness in open-domain dialogues.
Learning 3D Persistent Embodied World Models
May 05, 2025
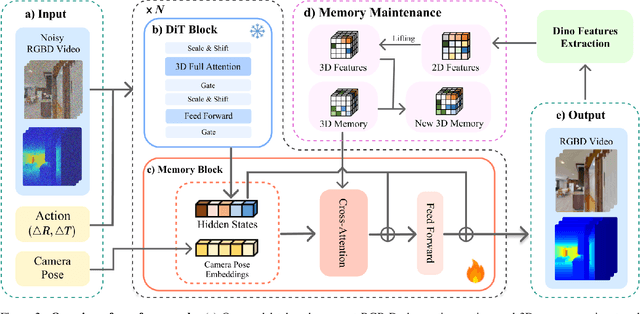
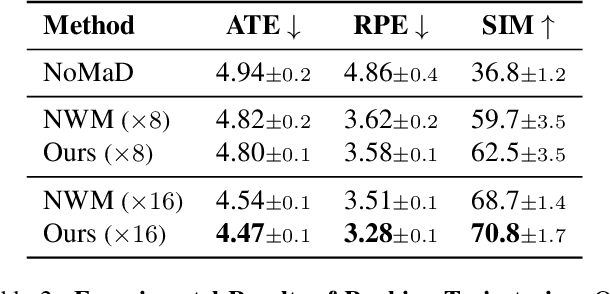
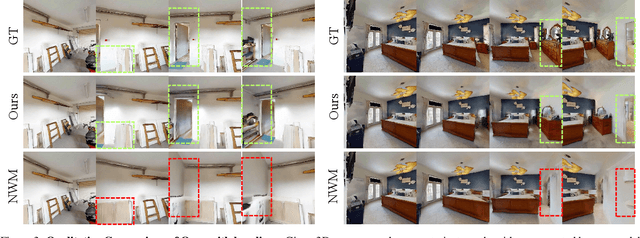
The ability to simulate the effects of future actions on the world is a crucial ability of intelligent embodied agents, enabling agents to anticipate the effects of their actions and make plans accordingly. While a large body of existing work has explored how to construct such world models using video models, they are often myopic in nature, without any memory of a scene not captured by currently observed images, preventing agents from making consistent long-horizon plans in complex environments where many parts of the scene are partially observed. We introduce a new persistent embodied world model with an explicit memory of previously generated content, enabling much more consistent long-horizon simulation. During generation time, our video diffusion model predicts RGB-D video of the future observations of the agent. This generation is then aggregated into a persistent 3D map of the environment. By conditioning the video model on this 3D spatial map, we illustrate how this enables video world models to faithfully simulate both seen and unseen parts of the world. Finally, we illustrate the efficacy of such a world model in downstream embodied applications, enabling effective planning and policy learning.
LSceneLLM: Enhancing Large 3D Scene Understanding Using Adaptive Visual Preferences
Dec 02, 2024



Research on 3D Vision-Language Models (3D-VLMs) is gaining increasing attention, which is crucial for developing embodied AI within 3D scenes, such as visual navigation and embodied question answering. Due to the high density of visual features, especially in large 3D scenes, accurately locating task-relevant visual information is challenging. Existing works attempt to segment all objects and consider their features as scene representations. However, these task-agnostic object features include much redundant information and missing details for the task-relevant area. To tackle these problems, we propose LSceneLLM, an adaptive framework that automatically identifies task-relevant areas by leveraging LLM's visual preference for different tasks, followed by a plug-and-play scene magnifier module to capture fine-grained details in focused areas. Specifically, a dense token selector examines the attention map of LLM to identify visual preferences for the instruction input. It then magnifies fine-grained details of the focusing area. An adaptive self-attention module is leveraged to fuse the coarse-grained and selected fine-grained visual information. To comprehensively evaluate the large scene understanding ability of 3D-VLMs, we further introduce a cross-room understanding benchmark, XR-Scene, which contains a series of large scene understanding tasks including XR-QA, XR-EmbodiedPlanning, and XR-SceneCaption. Experiments show that our method surpasses existing methods on both large scene understanding and existing scene understanding benchmarks. Plunging our scene magnifier module into the existing 3D-VLMs also brings significant improvement.
SnapMem: Snapshot-based 3D Scene Memory for Embodied Exploration and Reasoning
Nov 23, 2024



Constructing compact and informative 3D scene representations is essential for effective embodied exploration and reasoning, especially in complex environments over long periods. Existing scene representations, such as object-centric 3D scene graphs, have significant limitations. They oversimplify spatial relationships by modeling scenes as individual objects, with inter-object relationships described by restrictive texts, making it difficult to answer queries that require nuanced spatial understanding. Furthermore, these representations lack natural mechanisms for active exploration and memory management, which hampers their application to lifelong autonomy. In this work, we propose SnapMem, a novel snapshot-based scene representation serving as 3D scene memory for embodied agents. SnapMem employs informative images, termed Memory Snapshots, to capture rich visual information of explored regions. It also integrates frontier-based exploration by introducing Frontier Snapshots-glimpses of unexplored areas-that enable agents to make informed exploration decisions by considering both known and potential new information. Meanwhile, to support lifelong memory in active exploration settings, we further present an incremental construction pipeline for SnapMem, as well as an effective memory retrieval technique for memory management. Experimental results on three benchmarks demonstrate that SnapMem significantly enhances agents' exploration and reasoning capabilities in 3D environments over extended periods, highlighting its potential for advancing applications in embodied AI.
FlexAttention for Efficient High-Resolution Vision-Language Models
Jul 29, 2024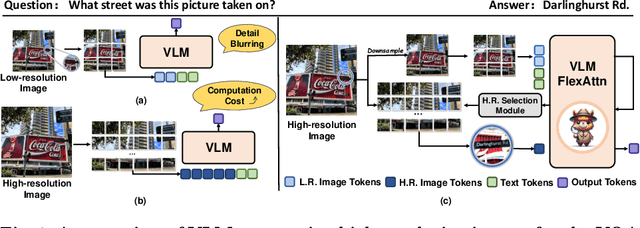
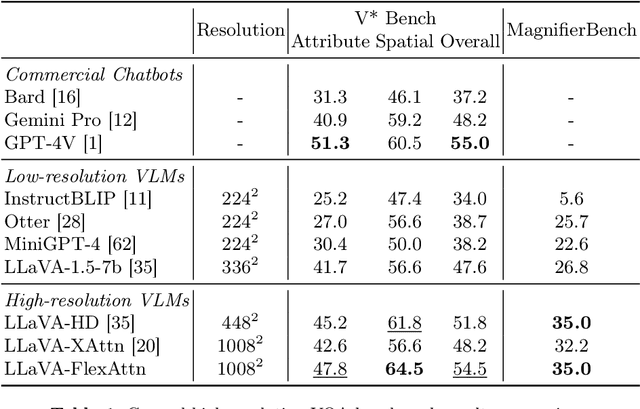
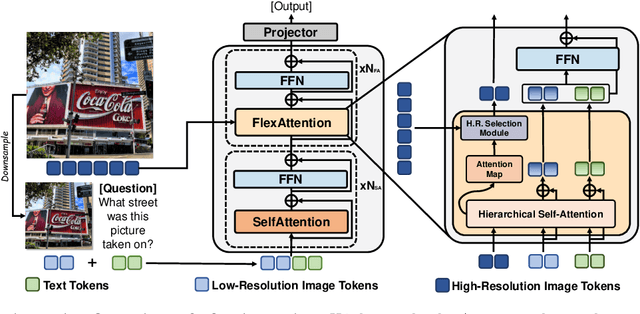
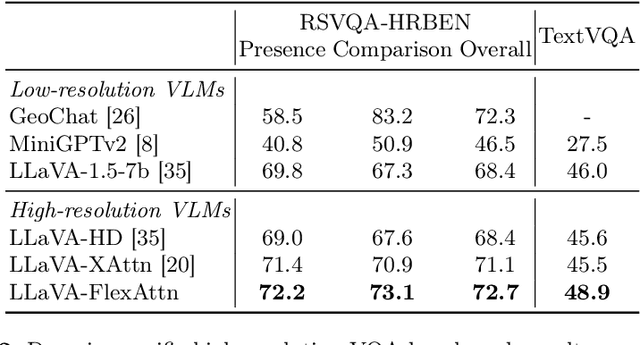
Current high-resolution vision-language models encode images as high-resolution image tokens and exhaustively take all these tokens to compute attention, which significantly increases the computational cost. To address this problem, we propose FlexAttention, a flexible attention mechanism for efficient high-resolution vision-language models. Specifically, a high-resolution image is encoded both as high-resolution tokens and low-resolution tokens, where only the low-resolution tokens and a few selected high-resolution tokens are utilized to calculate the attention map, which greatly shrinks the computational cost. The high-resolution tokens are selected via a high-resolution selection module which could retrieve tokens of relevant regions based on an input attention map. The selected high-resolution tokens are then concatenated to the low-resolution tokens and text tokens, and input to a hierarchical self-attention layer which produces an attention map that could be used for the next-step high-resolution token selection. The hierarchical self-attention process and high-resolution token selection process are performed iteratively for each attention layer. Experiments on multimodal benchmarks prove that our FlexAttention outperforms existing high-resolution VLMs (e.g., relatively ~9% in V* Bench, ~7% in TextVQA), while also significantly reducing the computational cost by nearly 40%.
CoNav: A Benchmark for Human-Centered Collaborative Navigation
Jun 04, 2024Human-robot collaboration, in which the robot intelligently assists the human with the upcoming task, is an appealing objective. To achieve this goal, the agent needs to be equipped with a fundamental collaborative navigation ability, where the agent should reason human intention by observing human activities and then navigate to the human's intended destination in advance of the human. However, this vital ability has not been well studied in previous literature. To fill this gap, we propose a collaborative navigation (CoNav) benchmark. Our CoNav tackles the critical challenge of constructing a 3D navigation environment with realistic and diverse human activities. To achieve this, we design a novel LLM-based humanoid animation generation framework, which is conditioned on both text descriptions and environmental context. The generated humanoid trajectory obeys the environmental context and can be easily integrated into popular simulators. We empirically find that the existing navigation methods struggle in CoNav task since they neglect the perception of human intention. To solve this problem, we propose an intention-aware agent for reasoning both long-term and short-term human intention. The agent predicts navigation action based on the predicted intention and panoramic observation. The emergent agent behavior including observing humans, avoiding human collision, and navigation reveals the efficiency of the proposed datasets and agents.
MAGIC: Map-Guided Few-Shot Audio-Visual Acoustics Modeling
May 22, 2024Few-shot audio-visual acoustics modeling seeks to synthesize the room impulse response in arbitrary locations with few-shot observations. To sufficiently exploit the provided few-shot data for accurate acoustic modeling, we present a *map-guided* framework by constructing acoustic-related visual semantic feature maps of the scenes. Visual features preserve semantic details related to sound and maps provide explicit structural regularities of sound propagation, which are valuable for modeling environment acoustics. We thus extract pixel-wise semantic features derived from observations and project them into a top-down map, namely the **observation semantic map**. This map contains the relative positional information among points and the semantic feature information associated with each point. Yet, limited information extracted by few-shot observations on the map is not sufficient for understanding and modeling the whole scene. We address the challenge by generating a **scene semantic map** via diffusing features and anticipating the observation semantic map. The scene semantic map then interacts with echo encoding by a transformer-based encoder-decoder to predict RIR for arbitrary speaker-listener query pairs. Extensive experiments on Matterport3D and Replica dataset verify the efficacy of our framework.
3D-VLA: A 3D Vision-Language-Action Generative World Model
Mar 14, 2024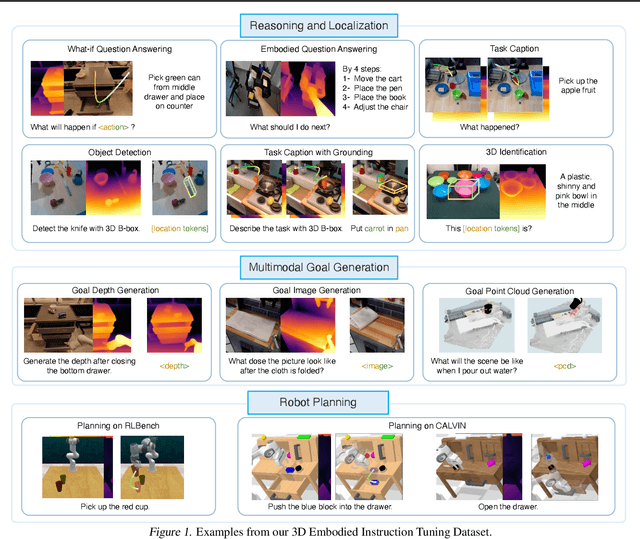
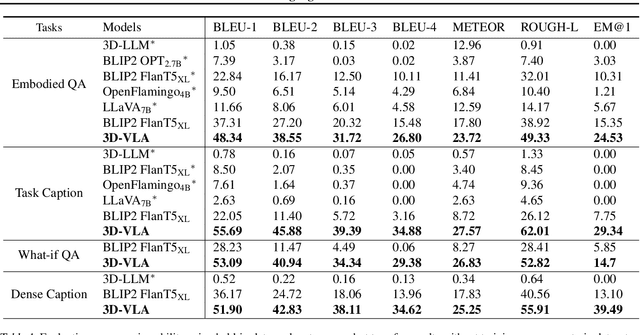
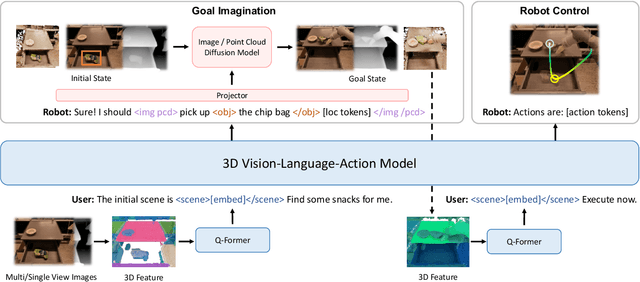
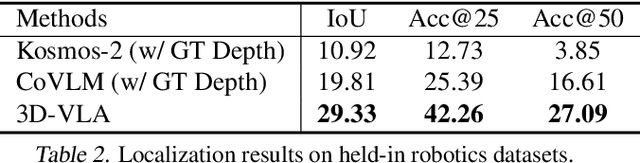
Recent vision-language-action (VLA) models rely on 2D inputs, lacking integration with the broader realm of the 3D physical world. Furthermore, they perform action prediction by learning a direct mapping from perception to action, neglecting the vast dynamics of the world and the relations between actions and dynamics. In contrast, human beings are endowed with world models that depict imagination about future scenarios to plan actions accordingly. To this end, we propose 3D-VLA by introducing a new family of embodied foundation models that seamlessly link 3D perception, reasoning, and action through a generative world model. Specifically, 3D-VLA is built on top of a 3D-based large language model (LLM), and a set of interaction tokens is introduced to engage with the embodied environment. Furthermore, to inject generation abilities into the model, we train a series of embodied diffusion models and align them into the LLM for predicting the goal images and point clouds. To train our 3D-VLA, we curate a large-scale 3D embodied instruction dataset by extracting vast 3D-related information from existing robotics datasets. Our experiments on held-in datasets demonstrate that 3D-VLA significantly improves the reasoning, multimodal generation, and planning capabilities in embodied environments, showcasing its potential in real-world applications.
MultiPLY: A Multisensory Object-Centric Embodied Large Language Model in 3D World
Jan 16, 2024
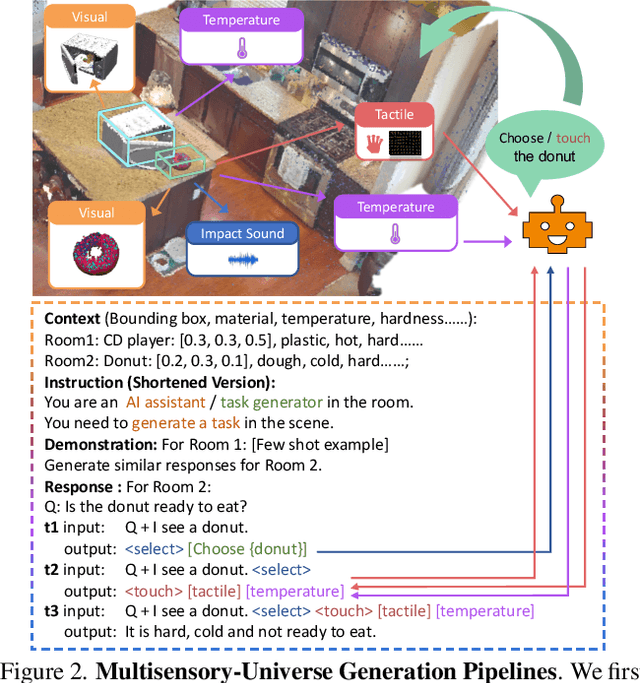


Human beings possess the capability to multiply a melange of multisensory cues while actively exploring and interacting with the 3D world. Current multi-modal large language models, however, passively absorb sensory data as inputs, lacking the capacity to actively interact with the objects in the 3D environment and dynamically collect their multisensory information. To usher in the study of this area, we propose MultiPLY, a multisensory embodied large language model that could incorporate multisensory interactive data, including visual, audio, tactile, and thermal information into large language models, thereby establishing the correlation among words, actions, and percepts. To this end, we first collect Multisensory Universe, a large-scale multisensory interaction dataset comprising 500k data by deploying an LLM-powered embodied agent to engage with the 3D environment. To perform instruction tuning with pre-trained LLM on such generated data, we first encode the 3D scene as abstracted object-centric representations and then introduce action tokens denoting that the embodied agent takes certain actions within the environment, as well as state tokens that represent the multisensory state observations of the agent at each time step. In the inference time, MultiPLY could generate action tokens, instructing the agent to take the action in the environment and obtain the next multisensory state observation. The observation is then appended back to the LLM via state tokens to generate subsequent text or action tokens. We demonstrate that MultiPLY outperforms baselines by a large margin through a diverse set of embodied tasks involving object retrieval, tool use, multisensory captioning, and task decomposition.