 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DFlowAction: Learning Cross-Embodiment Manipulation from 3D Flow World Model
Jun 06, 2025Manipulation has long been a challenging task for robots, while humans can effortlessly perform complex interactions with objects, such as hanging a cup on the mug rack. A key reason is the lack of a large and uniform dataset for teaching robots manipulation skills. Current robot datasets often record robot action in different action spaces within a simple scene. This hinders the robot to learn a unified and robust action representation for different robots within diverse scenes. Observing how humans understand a manipulation task, we find that understanding how the objects should move in the 3D space is a critical clue for guiding actions. This clue is embodiment-agnostic and suitable for both humans and different robots. Motivated by this, we aim to learn a 3D flow world model from both human and robot manipulation data. This model predicts the future movement of the interacting objects in 3D space, guiding action planning for manipulation. Specifically, we synthesize a large-scale 3D optical flow dataset, named ManiFlow-110k, through a moving object auto-detect pipeline. A video diffusion-based world model then learns manipulation physics from these data, generating 3D optical flow trajectories conditioned on language instructions. With the generated 3D object optical flow, we propose a flow-guided rendering mechanism, which renders the predicted final state and leverages GPT-4o to assess whether the predicted flow aligns with the task description. This equips the robot with a closed-loop planning ability. Finally, we consider the predicted 3D optical flow as constraints for an optimization policy to determine a chunk of robot actions for manipulation. Extensive experiments demonstrate strong generalization across diverse robotic manipulation tasks and reliable cross-embodiment adaptation without hardware-specific training.
LSceneLLM: Enhancing Large 3D Scene Understanding Using Adaptive Visual Preferences
Dec 02, 2024



Research on 3D Vision-Language Models (3D-VLMs) is gaining increasing attention, which is crucial for developing embodied AI within 3D scenes, such as visual navigation and embodied question answering. Due to the high density of visual features, especially in large 3D scenes, accurately locating task-relevant visual information is challenging. Existing works attempt to segment all objects and consider their features as scene representations. However, these task-agnostic object features include much redundant information and missing details for the task-relevant area. To tackle these problems, we propose LSceneLLM, an adaptive framework that automatically identifies task-relevant areas by leveraging LLM's visual preference for different tasks, followed by a plug-and-play scene magnifier module to capture fine-grained details in focused areas. Specifically, a dense token selector examines the attention map of LLM to identify visual preferences for the instruction input. It then magnifies fine-grained details of the focusing area. An adaptive self-attention module is leveraged to fuse the coarse-grained and selected fine-grained visual information. To comprehensively evaluate the large scene understanding ability of 3D-VLMs, we further introduce a cross-room understanding benchmark, XR-Scene, which contains a series of large scene understanding tasks including XR-QA, XR-EmbodiedPlanning, and XR-SceneCaption. Experiments show that our method surpasses existing methods on both large scene understanding and existing scene understanding benchmarks. Plunging our scene magnifier module into the existing 3D-VLMs also brings significant improvement.
$A^2$Nav: Action-Aware Zero-Shot Robot Navigation by Exploiting Vision-and-Language Ability of Foundation Models
Aug 15, 2023
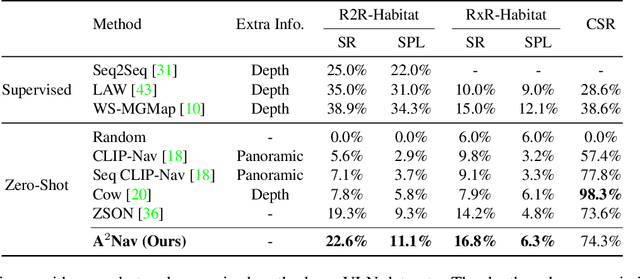
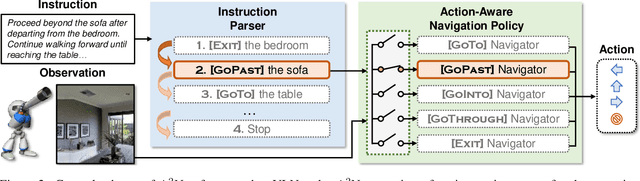
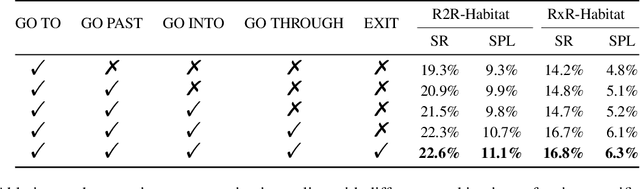
We study the task of zero-shot vision-and-language navigation (ZS-VLN), a practical yet challenging problem in which an agent learns to navigate following a path described by language instructions without requiring any path-instruction annotation data. Normally, the instructions have complex grammatical structures and often contain various action descriptions (e.g., "proceed beyond", "depart from"). How to correctly understand and execute these action demands is a critical problem, and the absence of annotated data makes it even more challenging. Note that a well-educated human being can easily understand path instructions without the need for any special training. In this paper, we propose an action-aware zero-shot VLN method ($A^2$Nav) by exploiting the vision-and-language ability of foundation models. Specifically, the proposed method consists of an instruction parser and an action-aware navigation policy. The instruction parser utilizes the advanced reasoning ability of large language models (e.g., GPT-3) to decompose complex navigation instructions into a sequence of action-specific object navigation sub-tasks. Each sub-task requires the agent to localize the object and navigate to a specific goal position according to the associated action demand. To accomplish these sub-tasks, an action-aware navigation policy is learned from freely collected action-specific datasets that reveal distinct characteristics of each action demand. We use the learned navigation policy for executing sub-tasks sequentially to follow the navigation instruction. Extensive experiments show $A^2$Nav achieves promising ZS-VLN performance and even surpasses the supervised learning methods on R2R-Habitat and RxR-Habitat datasets.