 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Open-source World Models
Jan 28, 2026We present LingBot-World, an open-sourced world simulator stemming from video generation. Positioned as a top-tier world model, LingBot-World offers the following features. (1) It maintains high fidelity and robust dynamics in a broad spectrum of environments, including realism, scientific contexts, cartoon styles, and beyond. (2) It enables a minute-level horizon while preserving contextual consistency over time, which is also known as "long-term memory". (3) It supports real-time interactivity, achieving a latency of under 1 second when producing 16 frames per second. We provide public access to the code and model in an effort to narrow the divide between open-source and closed-source technologies. We believe our release will empower the community with practical applications across areas like content creation, gaming, and robot learning.
A Pragmatic VLA Foundation Model
Jan 26, 2026Offering great potential in robotic manipulation, a capable Vision-Language-Action (VLA) foundation model is expected to faithfully generalize across tasks and platforms while ensuring cost efficiency (e.g., data and GPU hours required for adaptation). To this end, we develop LingBot-VLA with around 20,000 hours of real-world data from 9 popular dual-arm robot configurations. Through a systematic assessment on 3 robotic platforms, each completing 100 tasks with 130 post-training episodes per task, our model achieves clear superiority over competitors, showcasing its strong performance and broad generalizability. We have also built an efficient codebase, which delivers a throughput of 261 samples per second per GPU with an 8-GPU training setup, representing a 1.5~2.8$\times$ (depending on the relied VLM base model) speedup over existing VLA-oriented codebases. The above features ensure that our model is well-suited for real-world deployment. To advance the field of robot learning, we provide open access to the code, base model, and benchmark data, with a focus on enabling more challenging tasks and promoting sound evaluation standards.
The World is Your Canvas: Painting Promptable Events with Reference Images, Trajectories, and Text
Dec 18, 2025



We present WorldCanvas, a framework for promptable world events that enables rich, user-directed simulation by combining text, trajectories, and reference images. Unlike text-only approaches and existing trajectory-controlled image-to-video methods, our multimodal approach combines trajectories -- encoding motion, timing, and visibility -- with natural language for semantic intent and reference images for visual grounding of object identity, enabling the generation of coherent, controllable events that include multi-agent interactions, object entry/exit, reference-guided appearance and counterintuitive events. The resulting videos demonstrate not only temporal coherence but also emergent consistency, preserving object identity and scene despite temporary disappearance. By supporting expressive world events generation, WorldCanvas advances world models from passive predictors to interactive, user-shaped simulators. Our project page is available at: https://worldcanvas.github.io/.
Aligned Better, Listen Better for Audio-Visual Large Language Models
Apr 02, 2025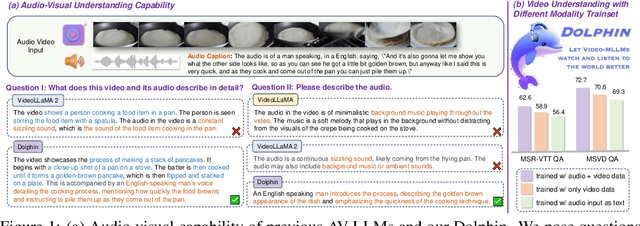

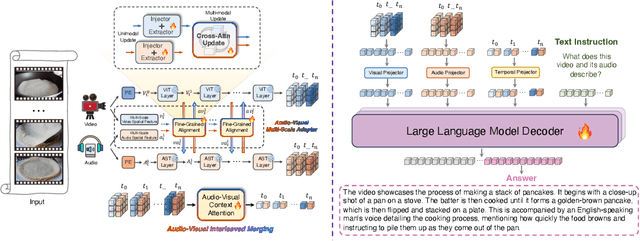
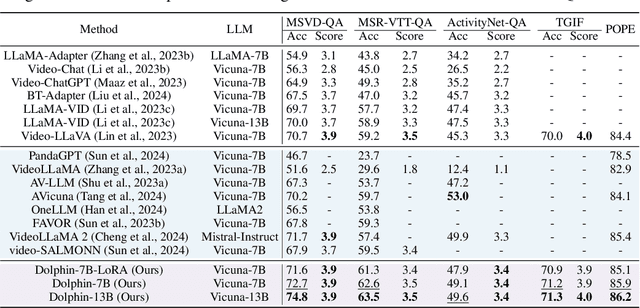
Audio is essential for multimodal video understanding. On the one hand, video inherently contains audio, which supplies complementary information to vision. Besides, video large language models (Video-LLMs) can encounter many audio-centric settings. However, existing Video-LLMs and Audio-Visual Large Language Models (AV-LLMs) exhibit deficiencies in exploiting audio information, leading to weak understanding and hallucinations. To solve the issues, we delve into the model architecture and dataset. (1) From the architectural perspective, we propose a fine-grained AV-LLM, namely Dolphin. The concurrent alignment of audio and visual modalities in both temporal and spatial dimensions ensures a comprehensive and accurate understanding of videos. Specifically, we devise an audio-visual multi-scale adapter for multi-scale information aggregation, which achieves spatial alignment. For temporal alignment, we propose audio-visual interleaved merging. (2) From the dataset perspective, we curate an audio-visual caption and instruction-tuning dataset, called AVU. It comprises 5.2 million diverse, open-ended data tuples (video, audio, question, answer) and introduces a novel data partitioning strategy. Extensive experiments show our model not only achieves remarkable performance in audio-visual understanding, but also mitigates potential hallucinations.
Benchmarking Large Vision-Language Models via Directed Scene Graph for Comprehensive Image Captioning
Dec 12, 2024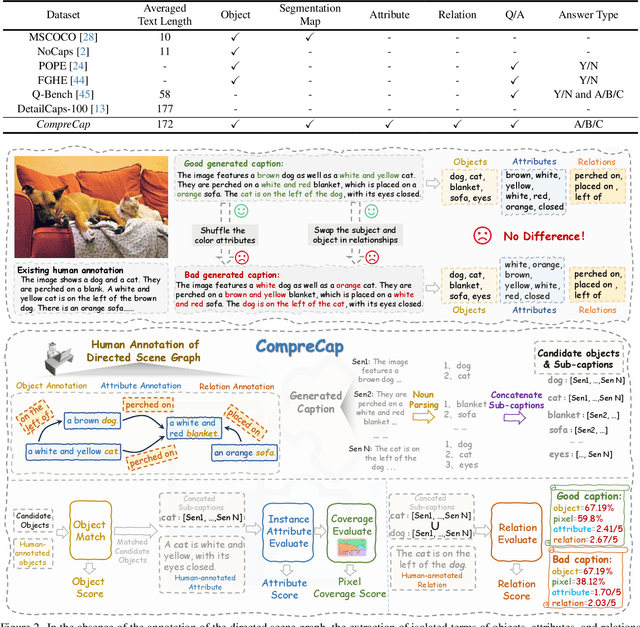
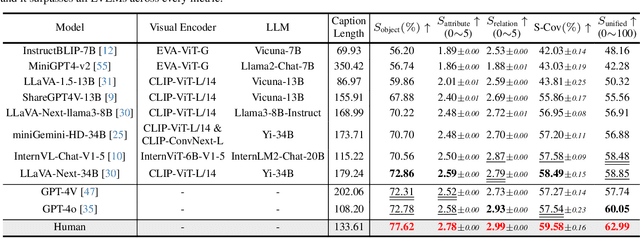

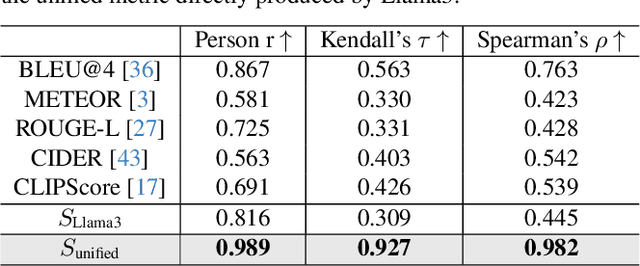
Generating detailed captions comprehending text-rich visual content in images has received growing attention for Large Vision-Language Models (LVLMs). However, few studies have developed benchmarks specifically tailored for detailed captions to measure their accuracy and comprehensiveness. In this paper, we introduce a detailed caption benchmark, termed as CompreCap, to evaluate the visual context from a directed scene graph view. Concretely, we first manually segment the image into semantically meaningful regions (i.e., semantic segmentation mask) according to common-object vocabulary, while also distinguishing attributes of objects within all those regions. Then directional relation labels of these objects are annotated to compose a directed scene graph that can well encode rich compositional information of the image. Based on our directed scene graph, we develop a pipeline to assess the generated detailed captions from LVLMs on multiple levels, including the object-level coverage, the accuracy of attribute descriptions, the score of key relationships, etc. Experimental results on the CompreCap dataset confirm that our evaluation method aligns closely with human evaluation scores across LVLMs.
Learning Visual Generative Priors without Text
Dec 10, 2024



Although text-to-image (T2I) models have recently thrived as visual generative priors, their reliance on high-quality text-image pairs makes scaling up expensive. We argue that grasping the cross-modality alignment is not a necessity for a sound visual generative prior, whose focus should be on texture modeling. Such a philosophy inspires us to study image-to-image (I2I) generation, where models can learn from in-the-wild images in a self-supervised manner. We first develop a pure vision-based training framework, Lumos, and confirm the feasibility and the scalability of learning I2I models. We then find that, as an upstream task of T2I, our I2I model serves as a more foundational visual prior and achieves on-par or better performance than existing T2I models using only 1/10 text-image pairs for fine-tuning. We further demonstrate the superiority of I2I priors over T2I priors on some text-irrelevant visual generative tasks, like image-to-3D and image-to-video.
LSceneLLM: Enhancing Large 3D Scene Understanding Using Adaptive Visual Preferences
Dec 02, 2024



Research on 3D Vision-Language Models (3D-VLMs) is gaining increasing attention, which is crucial for developing embodied AI within 3D scenes, such as visual navigation and embodied question answering. Due to the high density of visual features, especially in large 3D scenes, accurately locating task-relevant visual information is challenging. Existing works attempt to segment all objects and consider their features as scene representations. However, these task-agnostic object features include much redundant information and missing details for the task-relevant area. To tackle these problems, we propose LSceneLLM, an adaptive framework that automatically identifies task-relevant areas by leveraging LLM's visual preference for different tasks, followed by a plug-and-play scene magnifier module to capture fine-grained details in focused areas. Specifically, a dense token selector examines the attention map of LLM to identify visual preferences for the instruction input. It then magnifies fine-grained details of the focusing area. An adaptive self-attention module is leveraged to fuse the coarse-grained and selected fine-grained visual information. To comprehensively evaluate the large scene understanding ability of 3D-VLMs, we further introduce a cross-room understanding benchmark, XR-Scene, which contains a series of large scene understanding tasks including XR-QA, XR-EmbodiedPlanning, and XR-SceneCaption. Experiments show that our method surpasses existing methods on both large scene understanding and existing scene understanding benchmarks. Plunging our scene magnifier module into the existing 3D-VLMs also brings significant improvement.
LoTLIP: Improving Language-Image Pre-training for Long Text Understanding
Oct 07, 2024
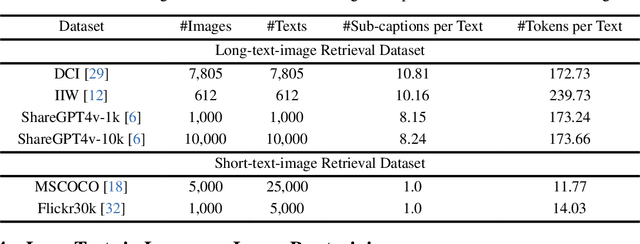


Understanding long text is of great demands in practice but beyond the reach of most language-image pre-training (LIP) models. In this work, we empirically confirm that the key reason causing such an issue is that the training images are usually paired with short captions, leaving certain tokens easily overshadowed by salient tokens. Towards this problem, our initial attempt is to relabel the data with long captions, however, directly learning with which may lead to performance degradation in understanding short text (e.g., in the image classification task). Then, after incorporating corner tokens to aggregate diverse textual information, we manage to help the model catch up to its original level of short text understanding yet greatly enhance its capability of long text understanding. We further look into whether the model can continuously benefit from longer captions and notice a clear trade-off between the performance and the efficiency. Finally, we validate the effectiveness of our approach using a self-constructed large-scale dataset, which consists of 100M long caption oriented text-image pairs. It is noteworthy that, on the task of long-text image retrieval, we beat the competitor using long captions with 11.1% improvement (i.e., from 72.62% to 83.72%). We will release the code, the model, and the new dataset to facilitate the reproducibility and further research. The project page is available at https://wuw2019.github.io/lotlip.
ControlMTR: Control-Guided Motion Transformer with Scene-Compliant Intention Points for Feasible Motion Prediction
Apr 17, 2024



The ability to accurately predict feasible multimodal future trajectories of surrounding traffic participants is crucial for behavior planning in autonomous vehicles. The Motion Transformer (MTR), a state-of-the-art motion prediction method, alleviated mode collapse and instability during training and enhanced overall prediction performance by replacing conventional dense future endpoints with a small set of fixed prior motion intention points. However, the fixed prior intention points make the MTR multi-modal prediction distribution over-scattered and infeasible in many scenarios. In this paper, we propose the ControlMTR framework to tackle the aforementioned issues by generating scene-compliant intention points and additionally predicting driving control commands, which are then converted into trajectories by a simple kinematic model with soft constraints. These control-generated trajectories will guide the directly predicted trajectories by an auxiliary loss function. Together with our proposed scene-compliant intention points, they can effectively restrict the prediction distribution within the road boundaries and suppress infeasible off-road predictions while enhancing prediction performance. Remarkably, without resorting to additional model ensemble techniques, our method surpasses the baseline MTR model across all performance metrics, achieving notable improvements of 5.22% in SoftmAP and a 4.15% reduction in MissRate. Our approach notably results in a 41.85% reduction in the cross-boundary rate of the MTR, effectively ensuring that the prediction distribution is confined within the drivable area.
CoReS: Orchestrating the Dance of Reasoning and Segmentation
Apr 08, 2024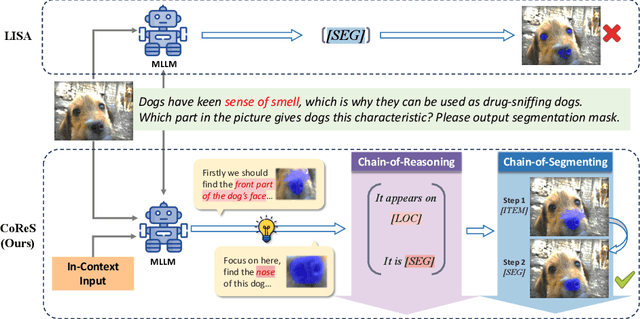
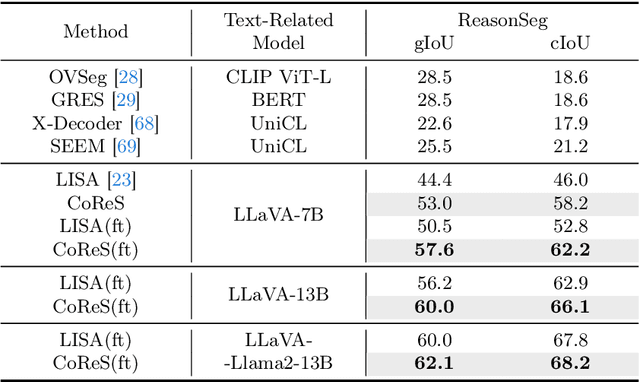
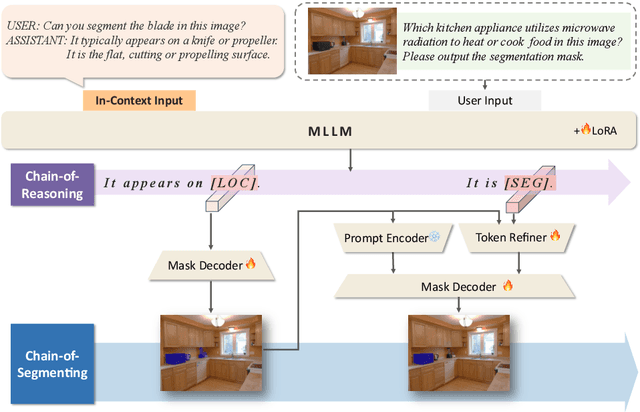
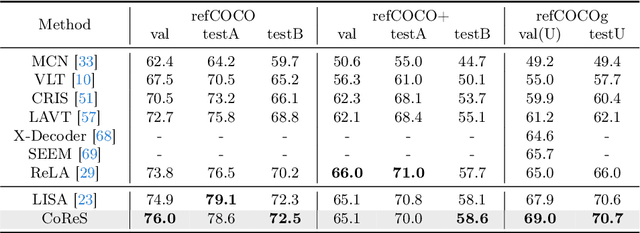
The reasoning segmentation task, which demands a nuanced comprehension of intricate queries to accurately pinpoint object regions, is attracting increasing attention. However, Multi-modal Large Language Models (MLLM) often find it difficult to accurately localize the objects described in complex reasoning contexts. We believe that the act of reasoning segmentation should mirror the cognitive stages of human visual search, where each step is a progressive refinement of thought toward the final object. Thus we introduce the Chains of Reasoning and Segmenting (CoReS) and find this top-down visual hierarchy indeed enhances the visual search process. Specifically, we propose a dual-chain structure that generates multi-modal, chain-like outputs to aid the segmentation process. Furthermore, to steer the MLLM's outputs into this intended hierarchy, we incorporate in-context inputs as guidance. Extensive experiments demonstrate the superior performance of our CoReS, which surpasses the state-of-the-art method by 7.1\% on the ReasonSeg dataset. The code will be released at https://github.com/baoxiaoyi/CoReS.