 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRewardFlow: Topology-Aware Reward Propagation on State Graphs for Agentic RL with Large Language Models
Mar 19, 2026Reinforcement learning (RL) holds significant promise for enhancing the agentic reasoning capabilities of large language models (LLMs) with external environments. However, the inherent sparsity of terminal rewards hinders fine-grained, state-level optimization. Although process reward modeling offers a promising alternative, training dedicated reward models often entails substantial computational costs and scaling difficulties. To address these challenges, we introduce RewardFlow, a lightweight method for estimating state-level rewards tailored to agentic reasoning tasks. RewardFlow leverages the intrinsic topological structure of states within reasoning trajectories by constructing state graphs. This enables an analysis of state-wise contributions to success, followed by topology-aware graph propagation to quantify contributions and yield objective, state-level rewards. When integrated as dense rewards for RL optimization, RewardFlow substantially outperforms prior RL baselines across four agentic reasoning benchmarks, demonstrating superior performance, robustness, and training efficiency. The implementation of RewardFlow is publicly available at https://github.com/tmlr-group/RewardFlow.
MLLM-SUL: Multimodal Large Language Model for Semantic Scene Understanding and Localization in Traffic Scenarios
Dec 27, 2024
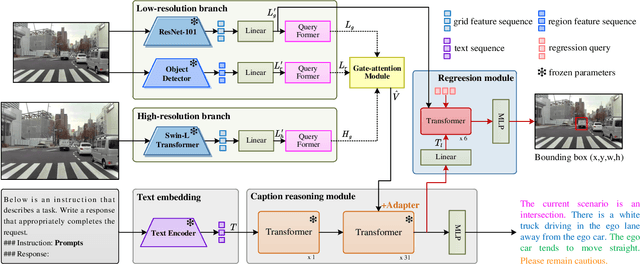
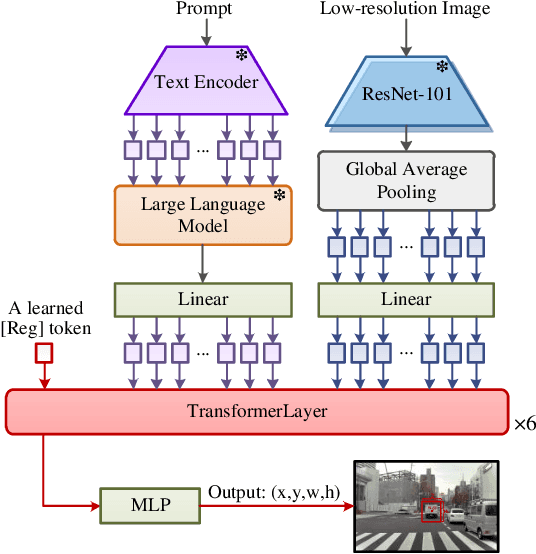

Multimodal large language models (MLLMs) have shown satisfactory effects in many autonomous driving tasks. In this paper, MLLMs are utilized to solve joint semantic scene understanding and risk localization tasks, while only relying on front-view images. In the proposed MLLM-SUL framework, a dual-branch visual encoder is first designed to extract features from two resolutions, and rich visual information is conducive to the language model describing risk objects of different sizes accurately. Then for the language generation, LLaMA model is fine-tuned to predict scene descriptions, containing the type of driving scenario, actions of risk objects, and driving intentions and suggestions of ego-vehicle. Ultimately, a transformer-based network incorporating a regression token is trained to locate the risk objects. Extensive experiments on the existing DRAMA-ROLISP dataset and the extended DRAMA-SRIS dataset demonstrate that our method is efficient, surpassing many state-of-the-art image-based and video-based methods. Specifically, our method achieves 80.1% BLEU-1 score and 298.5% CIDEr score in the scene understanding task, and 59.6% accuracy in the localization task. Codes and datasets are available at https://github.com/fjq-tongji/MLLM-SUL.
RAC3: Retrieval-Augmented Corner Case Comprehension for Autonomous Driving with Vision-Language Models
Dec 15, 2024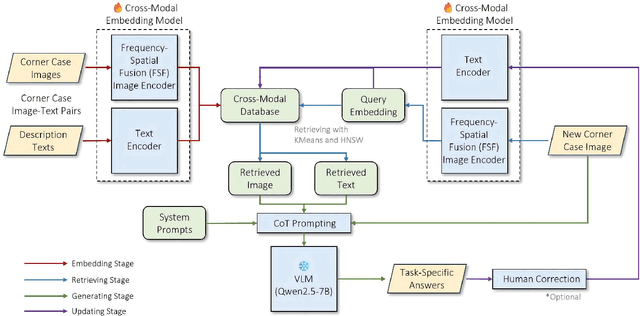
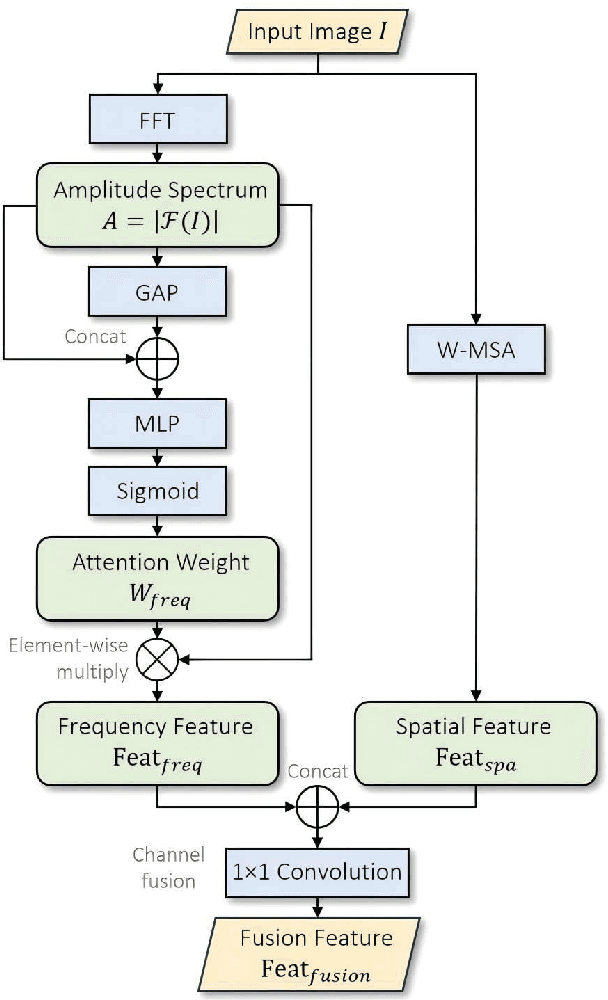
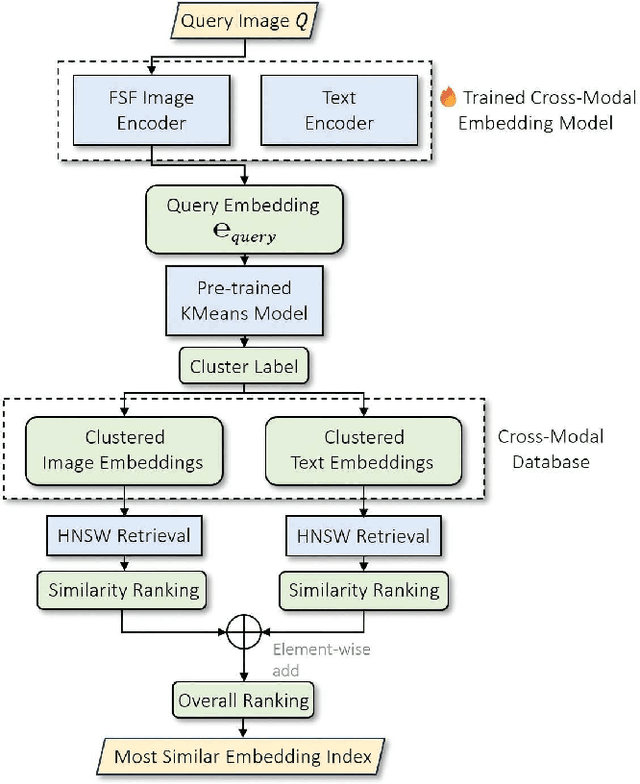

Understanding and addressing corner cases is essential for ensuring the safety and reliability of autonomous driving systems. Vision-Language Models (VLMs) play a crucial role in enhancing scenario comprehension, yet they face significant challenges, such as hallucination and insufficient real-world grounding, which compromise their performance in critical driving scenarios. In this work, we propose RAC3, a novel framework designed to improve VLMs' ability to handle corner cases effectively. The framework integrates Retrieval-Augmented Generation (RAG) to mitigate hallucination by dynamically incorporating context-specific external knowledge. A cornerstone of RAC3 is its cross-modal alignment fine-tuning, which utilizes contrastive learning to embed image-text pairs into a unified semantic space, enabling robust retrieval of similar scenarios. We evaluate RAC3 through extensive experiments using a curated dataset of corner case scenarios, demonstrating its ability to enhance semantic alignment, improve hallucination mitigation, and achieve superior performance metrics, such as Cosine Similarity and ROUGE-L scores. For example, for the LLaVA-v1.6-34B VLM, the cosine similarity between the generated text and the reference text has increased by 5.22\%. The F1-score in ROUGE-L has increased by 39.91\%, the Precision has increased by 55.80\%, and the Recall has increased by 13.74\%. This work underscores the potential of retrieval-augmented VLMs to advance the robustness and safety of autonomous driving in complex environments.
Hallucination Elimination and Semantic Enhancement Framework for Vision-Language Models in Traffic Scenarios
Dec 10, 2024



Large vision-language models (LVLMs) have demonstrated remarkable capabilities in multimodal understanding and generation tasks. However, these models occasionally generate hallucinatory texts, resulting in descriptions that seem reasonable but do not correspond to the image. This phenomenon can lead to wrong driving decisions of the autonomous driving system. To address this challenge, this paper proposes HCOENet, a plug-and-play chain-of-thought correction method designed to eliminate object hallucinations and generate enhanced descriptions for critical objects overlooked in the initial response. Specifically, HCOENet employs a cross-checking mechanism to filter entities and directly extracts critical objects from the given image, enriching the descriptive text. Experimental results on the POPE benchmark demonstrate that HCOENet improves the F1-score of the Mini-InternVL-4B and mPLUG-Owl3 models by 12.58% and 4.28%, respectively. Additionally, qualitative results using images collected in open campus scene further highlight the practical applicability of the proposed method. Compared with the GPT-4o model, HCOENet achieves comparable descriptive performance while significantly reducing costs. Finally, two novel semantic understanding datasets, CODA_desc and nuScenes_desc, are created for traffic scenarios to support future research. The codes and datasets are publicly available at https://github.com/fjq-tongji/HCOENet.
Understanding the Multi-modal Prompts of the Pre-trained Vision-Language Model
Dec 18, 2023



Prompt learning has emerged as an efficient alternative for fine-tuning foundational models, such as CLIP, for various downstream tasks. However, there is no work that provides a comprehensive explanation for the working mechanism of the multi-modal prompts. In this paper, we conduct a direct analysis of the multi-modal prompts by asking the following questions: $(i)$ How do the learned multi-modal prompts improve the recognition performance? $(ii)$ What do the multi-modal prompts learn? To answer these questions, we begin by isolating the component of the formula where the prompt influences the calculation of self-attention at each layer in two distinct ways, \ie, $(1)$ introducing prompt embeddings makes the $[cls]$ token focus on foreground objects. $(2)$ the prompts learn a bias term during the update of token embeddings, allowing the model to adapt to the target domain. Subsequently, we conduct extensive visualization and statistical experiments on the eleven diverse downstream recognition datasets. From the experiments, we reveal that the learned prompts improve the performance mainly through the second way, which acts as the dataset bias to improve the recognition performance of the pre-trained model on the corresponding dataset. Based on this finding, we propose the bias tuning way and demonstrate that directly incorporating the learnable bias outperforms the learnable prompts in the same parameter settings. In datasets with limited category information, \ie, EuroSAT, bias tuning surpasses prompt tuning by a large margin. With a deeper understanding of the multi-modal prompt, we hope our work can inspire new and solid research in this direction.
A Simple Knowledge Distillation Framework for Open-world Object Detection
Dec 14, 2023Open World Object Detection (OWOD) is a novel computer vision task with a considerable challenge, bridging the gap between classic object detection (OD) benchmarks and real-world object detection. In addition to detecting and classifying seen/known objects, OWOD algorithms are expected to localize all potential unseen/unknown objects and incrementally learn them. The large pre-trained vision-language grounding models (VLM,eg, GLIP) have rich knowledge about the open world, but are limited by text prompts and cannot localize indescribable objects. However, there are many detection scenarios which pre-defined language descriptions are unavailable during inference. In this paper, we attempt to specialize the VLM model for OWOD task by distilling its open-world knowledge into a language-agnostic detector. Surprisingly, we observe that the combination of a simple knowledge distillation approach and the automatic pseudo-labeling mechanism in OWOD can achieve better performance for unknown object detection, even with a small amount of data. Unfortunately, knowledge distillation for unknown objects severely affects the learning of detectors with conventional structures for known objects, leading to catastrophic forgetting. To alleviate these problems, we propose the down-weight loss function for knowledge distillation from vision-language to single vision modality. Meanwhile, we decouple the learning of localization and recognition to reduce the impact of category interactions of known and unknown objects on the localization learning process. Comprehensive experiments performed on MS-COCO and PASCAL VOC demonstrate the effectiveness of our methods.
Detecting the open-world objects with the help of the Brain
Mar 21, 2023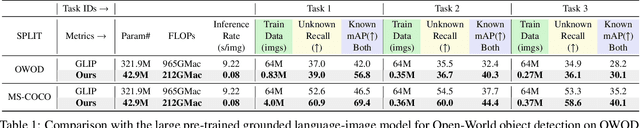
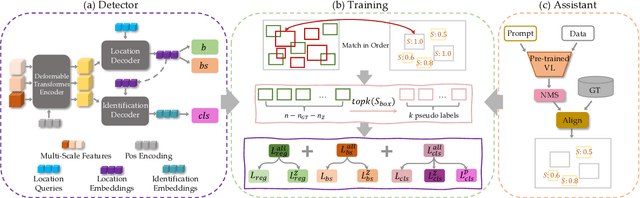
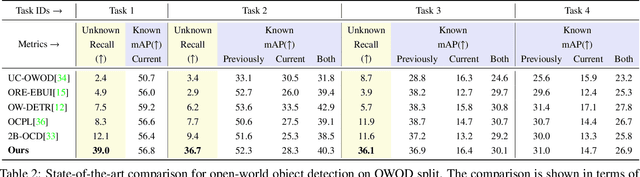
Open World Object Detection (OWOD) is a novel computer vision task with a considerable challenge, bridging the gap between classic object detection (OD) benchmarks and real-world object detection. In addition to detecting and classifying seen/known objects, OWOD algorithms are expected to detect unseen/unknown objects and incrementally learn them. The natural instinct of humans to identify unknown objects in their environments mainly depends on their brains' knowledge base. It is difficult for a model to do this only by learning from the annotation of several tiny datasets. The large pre-trained grounded language-image models - VL (\ie GLIP) have rich knowledge about the open world but are limited to the text prompt. We propose leveraging the VL as the ``Brain'' of the open-world detector by simply generating unknown labels. Leveraging it is non-trivial because the unknown labels impair the model's learning of known objects. In this paper, we alleviate these problems by proposing the down-weight loss function and decoupled detection structure. Moreover, our detector leverages the ``Brain'' to learn novel objects beyond VL through our pseudo-labeling scheme.
Predictions of photophysical properties of phosphorescent platinum(II) complexes based on ensemble machine learning approach
Jan 08, 2023Phosphorescent metal complexes have been under intense investigations as emissive dopants for energy efficient organic light emitting diodes (OLEDs). Among them, cyclometalated Pt(II) complexes are widespread triplet emitters with color-tunable emissions. To render their practical applications as OLED emitters, it is in great need to develop Pt(II) complexes with high radiative decay rate constant ($k_r$) and photoluminescence (PL) quantum yield. Thus, an efficient and accurate prediction tool is highly desirable. Here, we develop a general protocol for accurate predictions of emission wavelength, radiative decay rate constant, and PL quantum yield for phosphorescent Pt(II) emitters based on the combination of first-principles quantum mechanical method, machine learning (ML) and experimental calibration. A new dataset concerning phosphorescent Pt(II) emitters is constructed, with more than two hundred samples collected from the literature. Features containing pertinent electronic properties of the complexes are chosen. Our results demonstrate that ensemble learning models combined with stacking-based approaches exhibit the best performance, where the values of squared correlation coefficients ($R^2$), mean absolute error (MAE), and root mean square error (RMSE) are 0.96, 7.21 nm and 13.00 nm for emission wavelength prediction, and 0.81, 0.11 and 0.15 for PL quantum yield prediction. For radiative decay rate constant ($k_r$), the obtained value of $R^2$ is 0.67 while MAE and RMSE are 0.21 and 0.25 (both in log scale), respectively. The accuracy of the protocol is further confirmed using 24 recently reported Pt(II) complexes, which demonstrates its reliability for a broad palette of Pt(II) emitters.We expect this protocol will become a valuable tool, accelerating the rational design of novel OLED materials with desired properties.
CAT: LoCalization and IdentificAtion Cascade Detection Transformer for Open-World Object Detection
Jan 05, 2023



Open-world object detection (OWOD), as a more general and challenging goal, requires the model trained from data on known objects to detect both known and unknown objects and incrementally learn to identify these unknown objects. The existing works which employ standard detection framework and fixed pseudo-labelling mechanism (PLM) have the following problems: (i) The inclusion of detecting unknown objects substantially reduces the model's ability to detect known ones. (ii) The PLM does not adequately utilize the priori knowledge of inputs. (iii) The fixed selection manner of PLM cannot guarantee that the model is trained in the right direction. We observe that humans subconsciously prefer to focus on all foreground objects and then identify each one in detail, rather than localize and identify a single object simultaneously, for alleviating the confusion. This motivates us to propose a novel solution called CAT: LoCalization and IdentificAtion Cascade Detection Transformer which decouples the detection process via the shared decoder in the cascade decoding way. In the meanwhile, we propose the self-adaptive pseudo-labelling mechanism which combines the model-driven with input-driven PLM and self-adaptively generates robust pseudo-labels for unknown objects, significantly improving the ability of CAT to retrieve unknown objects. Comprehensive experiments on two benchmark datasets, i.e., MS-COCO and PASCAL VOC, show that our model outperforms the state-of-the-art in terms of all metrics in the task of OWOD, incremental object detection (IOD) and open-set detection.
Interpretable Compositional Convolutional Neural Networks
Jul 09, 2021
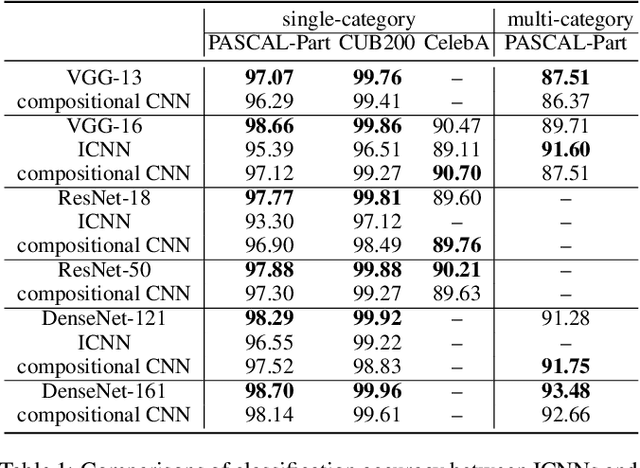
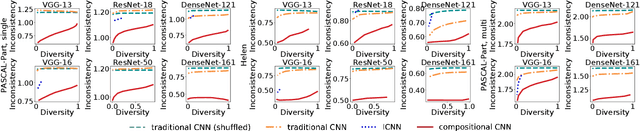

The reasonable definition of semantic interpretability presents the core challenge in explainable AI. This paper proposes a method to modify a traditional convolutional neural network (CNN) into an interpretable compositional CNN, in order to learn filters that encode meaningful visual patterns in intermediate convolutional layers. In a compositional CNN, each filter is supposed to consistently represent a specific compositional object part or image region with a clear meaning. The compositional CNN learns from image labels for classification without any annotations of parts or regions for supervision. Our method can be broadly applied to different types of CNNs. Experiments have demonstrated the effectiveness of our method.