 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScenePilot-Bench: A Large-Scale Dataset and Benchmark for Evaluation of Vision-Language Models in Autonomous Driving
Jan 27, 2026In this paper, we introduce ScenePilot-Bench, a large-scale first-person driving benchmark designed to evaluate vision-language models (VLMs) in autonomous driving scenarios. ScenePilot-Bench is built upon ScenePilot-4K, a diverse dataset comprising 3,847 hours of driving videos, annotated with multi-granularity information including scene descriptions, risk assessments, key participant identification, ego trajectories, and camera parameters. The benchmark features a four-axis evaluation suite that assesses VLM capabilities in scene understanding, spatial perception, motion planning, and GPT-Score, with safety-aware metrics and cross-region generalization settings. We benchmark representative VLMs on ScenePilot-Bench, providing empirical analyses that clarify current performance boundaries and identify gaps for driving-oriented reasoning. ScenePilot-Bench offers a comprehensive framework for evaluating and advancing VLMs in safety-critical autonomous driving contexts.
RAD: Retrieval-Augmented Decision-Making of Meta-Actions with Vision-Language Models in Autonomous Driving
Mar 18, 2025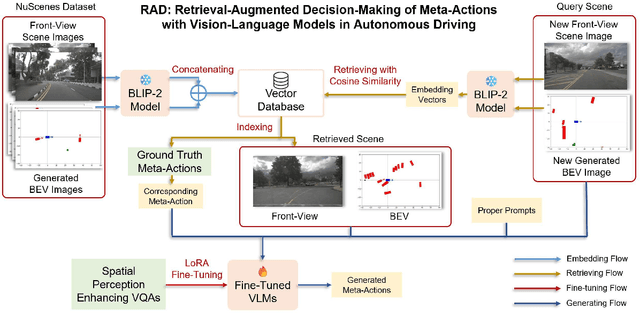
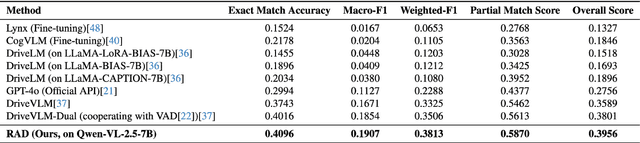
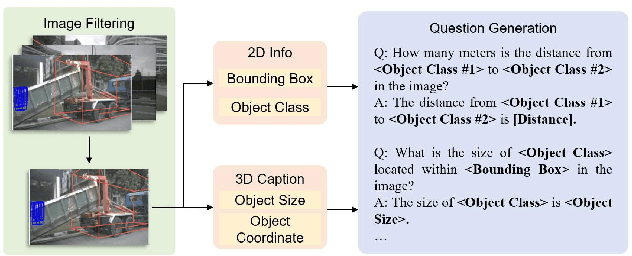
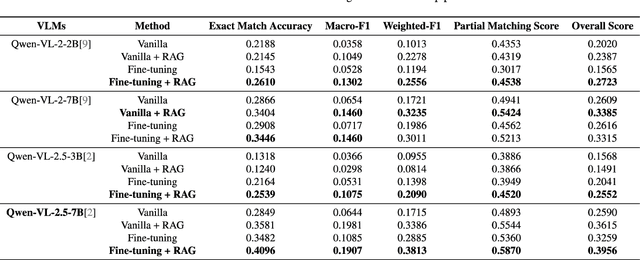
Accurately understanding and deciding high-level meta-actions is essential for ensuring reliable and safe autonomous driving systems. While vision-language models (VLMs) have shown significant potential in various autonomous driving tasks, they often suffer from limitations such as inadequate spatial perception and hallucination, reducing their effectiveness in complex autonomous driving scenarios. To address these challenges, we propose a retrieval-augmented decision-making (RAD) framework, a novel architecture designed to enhance VLMs' capabilities to reliably generate meta-actions in autonomous driving scenes. RAD leverages a retrieval-augmented generation (RAG) pipeline to dynamically improve decision accuracy through a three-stage process consisting of the embedding flow, retrieving flow, and generating flow. Additionally, we fine-tune VLMs on a specifically curated dataset derived from the NuScenes dataset to enhance their spatial perception and bird's-eye view image comprehension capabilities. Extensive experimental evaluations on the curated NuScenes-based dataset demonstrate that RAD outperforms baseline methods across key evaluation metrics, including match accuracy, and F1 score, and self-defined overall score, highlighting its effectiveness in improving meta-action decision-making for autonomous driving tasks.
MLLM-SUL: Multimodal Large Language Model for Semantic Scene Understanding and Localization in Traffic Scenarios
Dec 27, 2024
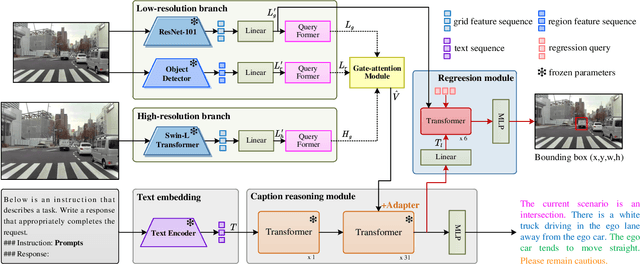
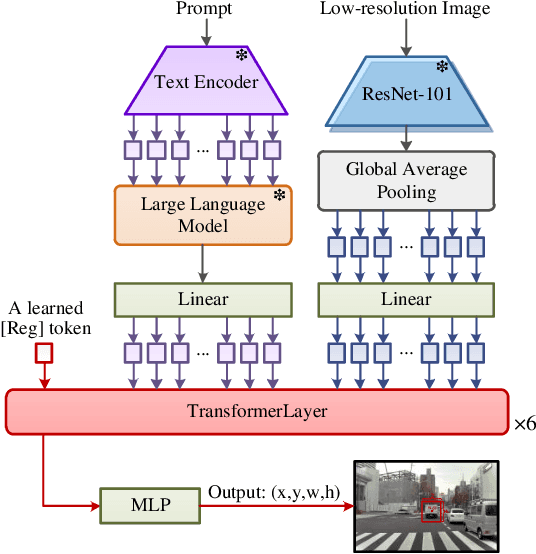

Multimodal large language models (MLLMs) have shown satisfactory effects in many autonomous driving tasks. In this paper, MLLMs are utilized to solve joint semantic scene understanding and risk localization tasks, while only relying on front-view images. In the proposed MLLM-SUL framework, a dual-branch visual encoder is first designed to extract features from two resolutions, and rich visual information is conducive to the language model describing risk objects of different sizes accurately. Then for the language generation, LLaMA model is fine-tuned to predict scene descriptions, containing the type of driving scenario, actions of risk objects, and driving intentions and suggestions of ego-vehicle. Ultimately, a transformer-based network incorporating a regression token is trained to locate the risk objects. Extensive experiments on the existing DRAMA-ROLISP dataset and the extended DRAMA-SRIS dataset demonstrate that our method is efficient, surpassing many state-of-the-art image-based and video-based methods. Specifically, our method achieves 80.1% BLEU-1 score and 298.5% CIDEr score in the scene understanding task, and 59.6% accuracy in the localization task. Codes and datasets are available at https://github.com/fjq-tongji/MLLM-SUL.
RAC3: Retrieval-Augmented Corner Case Comprehension for Autonomous Driving with Vision-Language Models
Dec 15, 2024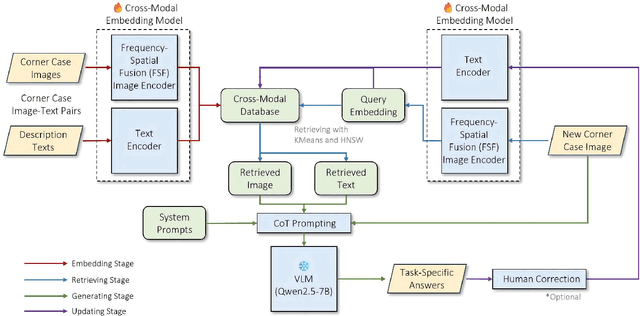
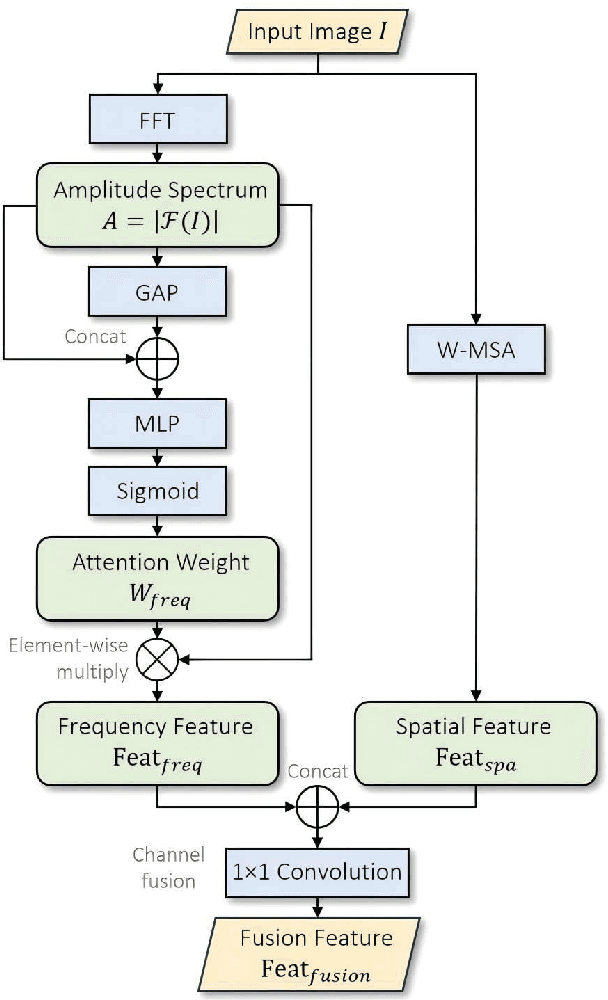
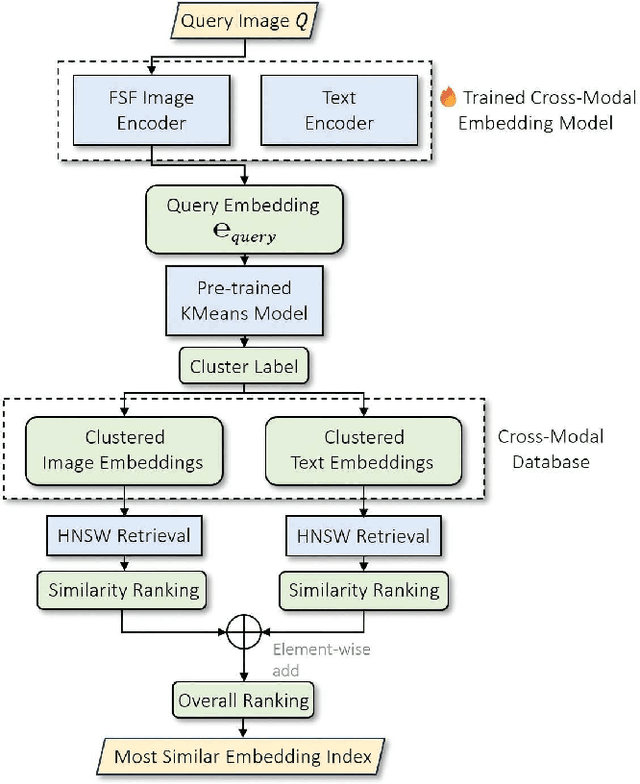

Understanding and addressing corner cases is essential for ensuring the safety and reliability of autonomous driving systems. Vision-Language Models (VLMs) play a crucial role in enhancing scenario comprehension, yet they face significant challenges, such as hallucination and insufficient real-world grounding, which compromise their performance in critical driving scenarios. In this work, we propose RAC3, a novel framework designed to improve VLMs' ability to handle corner cases effectively. The framework integrates Retrieval-Augmented Generation (RAG) to mitigate hallucination by dynamically incorporating context-specific external knowledge. A cornerstone of RAC3 is its cross-modal alignment fine-tuning, which utilizes contrastive learning to embed image-text pairs into a unified semantic space, enabling robust retrieval of similar scenarios. We evaluate RAC3 through extensive experiments using a curated dataset of corner case scenarios, demonstrating its ability to enhance semantic alignment, improve hallucination mitigation, and achieve superior performance metrics, such as Cosine Similarity and ROUGE-L scores. For example, for the LLaVA-v1.6-34B VLM, the cosine similarity between the generated text and the reference text has increased by 5.22\%. The F1-score in ROUGE-L has increased by 39.91\%, the Precision has increased by 55.80\%, and the Recall has increased by 13.74\%. This work underscores the potential of retrieval-augmented VLMs to advance the robustness and safety of autonomous driving in complex environments.
Hallucination Elimination and Semantic Enhancement Framework for Vision-Language Models in Traffic Scenarios
Dec 10, 2024



Large vision-language models (LVLMs) have demonstrated remarkable capabilities in multimodal understanding and generation tasks. However, these models occasionally generate hallucinatory texts, resulting in descriptions that seem reasonable but do not correspond to the image. This phenomenon can lead to wrong driving decisions of the autonomous driving system. To address this challenge, this paper proposes HCOENet, a plug-and-play chain-of-thought correction method designed to eliminate object hallucinations and generate enhanced descriptions for critical objects overlooked in the initial response. Specifically, HCOENet employs a cross-checking mechanism to filter entities and directly extracts critical objects from the given image, enriching the descriptive text. Experimental results on the POPE benchmark demonstrate that HCOENet improves the F1-score of the Mini-InternVL-4B and mPLUG-Owl3 models by 12.58% and 4.28%, respectively. Additionally, qualitative results using images collected in open campus scene further highlight the practical applicability of the proposed method. Compared with the GPT-4o model, HCOENet achieves comparable descriptive performance while significantly reducing costs. Finally, two novel semantic understanding datasets, CODA_desc and nuScenes_desc, are created for traffic scenarios to support future research. The codes and datasets are publicly available at https://github.com/fjq-tongji/HCOENet.