 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen to Lock Attention: Training-Free KV Control in Video Diffusion
Mar 10, 2026Maintaining background consistency while enhancing foreground quality remains a core challenge in video editing. Injecting full-image information often leads to background artifacts, whereas rigid background locking severely constrains the model's capacity for foreground generation. To address this issue, we propose KV-Lock, a training-free framework tailored for DiT-based video diffusion models. Our core insight is that the hallucination metric (variance of denoising prediction) directly quantifies generation diversity, which is inherently linked to the classifier-free guidance (CFG) scale. Building upon this, KV-Lock leverages diffusion hallucination detection to dynamically schedule two key components: the fusion ratio between cached background key-values (KVs) and newly generated KVs, and the CFG scale. When hallucination risk is detected, KV-Lock strengthens background KV locking and simultaneously amplifies conditional guidance for foreground generation, thereby mitigating artifacts and improving generation fidelity. As a training-free, plug-and-play module, KV-Lock can be easily integrated into any pre-trained DiT-based models. Extensive experiments validate that our method outperforms existing approaches in improved foreground quality with high background fidelity across various video editing tasks.
LLM-MLFFN: Multi-Level Autonomous Driving Behavior Feature Fusion via Large Language Model
Mar 03, 2026Accurate classification of autonomous vehicle (AV) driving behaviors is critical for safety validation, performance diagnosis, and traffic integration analysis. However, existing approaches primarily rely on numerical time-series modeling and often lack semantic abstraction, limiting interpretability and robustness in complex traffic environments. This paper presents LLM-MLFFN, a novel large language model (LLM)-enhanced multi-level feature fusion network designed to address the complexities of multi-dimensional driving data. The proposed LLM-MLFFN framework integrates priors from largescale pre-trained models and employs a multi-level approach to enhance classification accuracy. LLM-MLFFN comprises three core components: (1) a multi-level feature extraction module that extracts statistical, behavioral, and dynamic features to capture the quantitative aspects of driving behaviors; (2) a semantic description module that leverages LLMs to transform raw data into high-level semantic features; and (3) a dual-channel multi-level feature fusion network that combines numerical and semantic features using weighted attention mechanisms to improve robustness and prediction accuracy. Evaluation on the Waymo open trajectory dataset demonstrates the superior performance of the proposed LLM-MLFFN, achieving a classification accuracy of over 94%, surpassing existing machine learning models. Ablation studies further validate the critical contributions of multi-level fusion, feature extraction strategies, and LLM-derived semantic reasoning. These results suggest that integrating structured feature modeling with language-driven semantic abstraction provides a principled and interpretable pathway for robust autonomous driving behavior classification.
PILD: Physics-Informed Learning via Diffusion
Jan 29, 2026Diffusion models have emerged as powerful generative tools for modeling complex data distributions, yet their purely data-driven nature limits applicability in practical engineering and scientific problems where physical laws need to be followed. This paper proposes Physics-Informed Learning via Diffusion (PILD), a framework that unifies diffusion modeling and first-principles physical constraints by introducing a virtual residual observation sampled from a Laplace distribution to supervise generation during training. To further integrate physical laws, a conditional embedding module is incorporated to inject physical information into the denoising network at multiple layers, ensuring consistent guidance throughout the diffusion process. The proposed PILD framework is concise, modular, and broadly applicable to problems governed by ordinary differential equations, partial differential equations, as well as algebraic equations or inequality constraints. Extensive experiments across engineering and scientific tasks including estimating vehicle trajectories, tire forces, Darcy flow and plasma dynamics, demonstrate that our PILD substantially improves accuracy, stability, and generalization over existing physics-informed and diffusion-based baselines.
HCOMC: A Hierarchical Cooperative On-Ramp Merging Control Framework in Mixed Traffic Environment on Two-Lane Highways
Jul 15, 2025Highway on-ramp merging areas are common bottlenecks to traffic congestion and accidents. Currently, a cooperative control strategy based on connected and automated vehicles (CAVs) is a fundamental solution to this problem. While CAVs are not fully widespread, it is necessary to propose a hierarchical cooperative on-ramp merging control (HCOMC) framework for heterogeneous traffic flow on two-lane highways to address this gap. This paper extends longitudinal car-following models based on the intelligent driver model and lateral lane-changing models using the quintic polynomial curve to account for human-driven vehicles (HDVs) and CAVs, comprehensively considering human factors and cooperative adaptive cruise control. Besides, this paper proposes a HCOMC framework, consisting of a hierarchical cooperative planning model based on the modified virtual vehicle model, a discretionary lane-changing model based on game theory, and a multi-objective optimization model using the elitist non-dominated sorting genetic algorithm to ensure the safe, smooth, and efficient merging process. Then, the performance of our HCOMC is analyzed under different traffic densities and CAV penetration rates through simulation. The findings underscore our HCOMC's pronounced comprehensive advantages in enhancing the safety of group vehicles, stabilizing and expediting merging process, optimizing traffic efficiency, and economizing fuel consumption compared with benchmarks.
SafeMate: A Modular RAG-Based Agent for Context-Aware Emergency Guidance
May 19, 2025



Despite the abundance of public safety documents and emergency protocols, most individuals remain ill-equipped to interpret and act on such information during crises. Traditional emergency decision support systems (EDSS) are designed for professionals and rely heavily on static documents like PDFs or SOPs, which are difficult for non-experts to navigate under stress. This gap between institutional knowledge and public accessibility poses a critical barrier to effective emergency preparedness and response. We introduce SafeMate, a retrieval-augmented AI assistant that delivers accurate, context-aware guidance to general users in both preparedness and active emergency scenarios. Built on the Model Context Protocol (MCP), SafeMate dynamically routes user queries to tools for document retrieval, checklist generation, and structured summarization. It uses FAISS with cosine similarity to identify relevant content from trusted sources.
Investigating Robotaxi Crash Severity Using Geographical Random Forest
May 10, 2025This paper quantitatively investigates the crash severity of Autonomous Vehicles (AVs) with spatially localized machine learning and macroscopic measures of the urban built environment. We address spatial heterogeneity and spatial autocorrelation, while focusing on land use patterns and human behavior. Our Geographical Random Forest (GRF) model, accompanied with a crash severity risk map of San Francisco, presents three findings that are useful for commercial operations of AVs and robotaxis. First, spatially localized machine learning performed better than regular machine learning, when predicting AV crash severity. Bias-variance tradeoff was evident as we adjust the localization weight hyperparameter. Second, land use was the most important built environment measure, compared to intersections, building footprints, public transit stops, and Points Of Interests (POIs). Third, it was predicted that city center areas with greater diversity and commercial activities were more likely to result in low-severity AV crashes, than residential neighborhoods. Residential land use may be associated with higher severity due to human behavior and less restrictive environment. This paper recommends to explicitly consider geographic locations, and to design safety measures specific to residential neighborhoods, when robotaxi operators train their AV systems.
SafeMate: A Model Context Protocol-Based Multimodal Agent for Emergency Preparedness
May 05, 2025Despite the abundance of public safety documents and emergency protocols, most individuals remain ill-equipped to interpret and act on such information during crises. Traditional emergency decision support systems (EDSS) are designed for professionals and rely heavily on static documents like PDFs or SOPs, which are difficult for non-experts to navigate under stress. This gap between institutional knowledge and public accessibility poses a critical barrier to effective emergency preparedness and response. We introduce SafeMate, a retrieval-augmented AI assistant that delivers accurate, context-aware guidance to general users in both preparedness and active emergency scenarios. Built on the Model Context Protocol (MCP), SafeMate dynamically routes user queries to tools for document retrieval, checklist generation, and structured summarization. It uses FAISS with cosine similarity to identify relevant content from trusted sources.
GAIR: Improving Multimodal Geo-Foundation Model with Geo-Aligned Implicit Representations
Mar 20, 2025



Advancements in vision and language foundation models have inspired the development of geo-foundation models (GeoFMs), enhancing performance across diverse geospatial tasks. However, many existing GeoFMs primarily focus on overhead remote sensing (RS) data while neglecting other data modalities such as ground-level imagery. A key challenge in multimodal GeoFM development is to explicitly model geospatial relationships across modalities, which enables generalizability across tasks, spatial scales, and temporal contexts. To address these limitations, we propose GAIR, a novel multimodal GeoFM architecture integrating overhead RS data, street view (SV) imagery, and their geolocation metadata. We utilize three factorized neural encoders to project an SV image, its geolocation, and an RS image into the embedding space. The SV image needs to be located within the RS image's spatial footprint but does not need to be at its geographic center. In order to geographically align the SV image and RS image, we propose a novel implicit neural representations (INR) module that learns a continuous RS image representation and looks up the RS embedding at the SV image's geolocation. Next, these geographically aligned SV embedding, RS embedding, and location embedding are trained with contrastive learning objectives from unlabeled data. We evaluate GAIR across 10 geospatial tasks spanning RS image-based, SV image-based, and location embedding-based benchmarks. Experimental results demonstrate that GAIR outperforms state-of-the-art GeoFMs and other strong baselines, highlighting its effectiveness in learning generalizable and transferable geospatial representations.
RAD: Retrieval-Augmented Decision-Making of Meta-Actions with Vision-Language Models in Autonomous Driving
Mar 18, 2025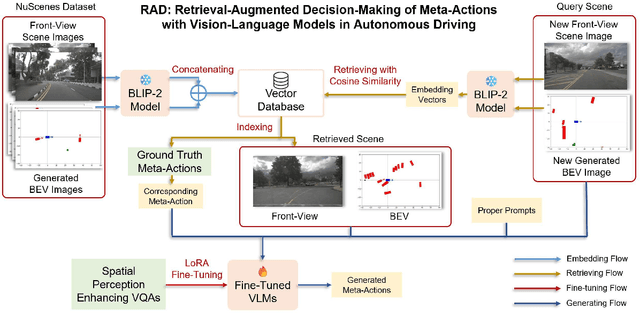
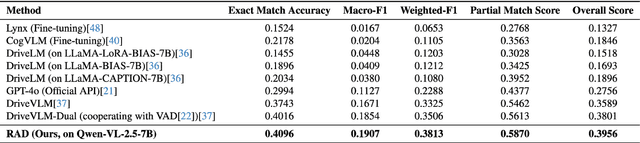
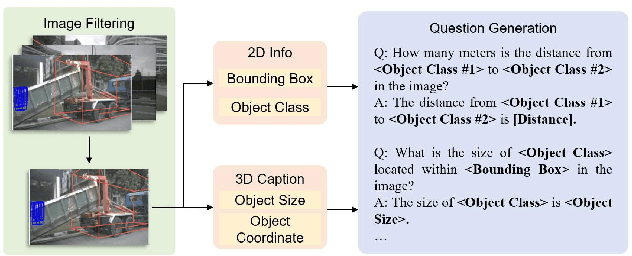
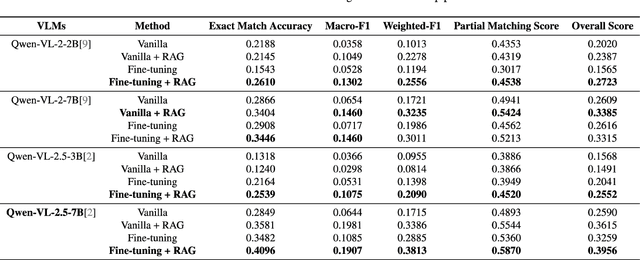
Accurately understanding and deciding high-level meta-actions is essential for ensuring reliable and safe autonomous driving systems. While vision-language models (VLMs) have shown significant potential in various autonomous driving tasks, they often suffer from limitations such as inadequate spatial perception and hallucination, reducing their effectiveness in complex autonomous driving scenarios. To address these challenges, we propose a retrieval-augmented decision-making (RAD) framework, a novel architecture designed to enhance VLMs' capabilities to reliably generate meta-actions in autonomous driving scenes. RAD leverages a retrieval-augmented generation (RAG) pipeline to dynamically improve decision accuracy through a three-stage process consisting of the embedding flow, retrieving flow, and generating flow. Additionally, we fine-tune VLMs on a specifically curated dataset derived from the NuScenes dataset to enhance their spatial perception and bird's-eye view image comprehension capabilities. Extensive experimental evaluations on the curated NuScenes-based dataset demonstrate that RAD outperforms baseline methods across key evaluation metrics, including match accuracy, and F1 score, and self-defined overall score, highlighting its effectiveness in improving meta-action decision-making for autonomous driving tasks.
A Cascading Cooperative Multi-agent Framework for On-ramp Merging Control Integrating Large Language Models
Mar 11, 2025Traditional Reinforcement Learning (RL) suffers from replicating human-like behaviors, generalizing effectively in multi-agent scenarios, and overcoming inherent interpretability issues.These tasks are compounded when deep environment understanding, agent coordination and dynamic optimization are required. While Large Language Model (LLM) enhanced methods have shown promise in generalization and interoperability, they often neglect necessary multi-agent coordination. Therefore, we introduce the Cascading Cooperative Multi-agent (CCMA) framework, integrating RL for individual interactions, a fine-tuned LLM for regional cooperation, a reward function for global optimization, and the Retrieval-augmented Generation mechanism to dynamically optimize decision-making across complex driving scenarios. Our experiments demonstrate that the CCMA outperforms existing RL methods, demonstrating significant improvements in both micro and macro-level performance in complex driving environments.