 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNative Intelligence Emerges from Large-Scale Clinical Practice: A Retinal Foundation Model with Deployment Efficiency
Dec 16, 2025Current retinal foundation models remain constrained by curated research datasets that lack authentic clinical context, and require extensive task-specific optimization for each application, limiting their deployment efficiency in low-resource settings. Here, we show that these barriers can be overcome by building clinical native intelligence directly from real-world medical practice. Our key insight is that large-scale telemedicine programs, where expert centers provide remote consultations across distributed facilities, represent a natural reservoir for learning clinical image interpretation. We present ReVision, a retinal foundation model that learns from the natural alignment between 485,980 color fundus photographs and their corresponding diagnostic reports, accumulated through a decade-long telemedicine program spanning 162 medical institutions across China. Through extensive evaluation across 27 ophthalmic benchmarks, we demonstrate that ReVison enables deployment efficiency with minimal local resources. Without any task-specific training, ReVision achieves zero-shot disease detection with an average AUROC of 0.946 across 12 public benchmarks and 0.952 on 3 independent clinical cohorts. When minimal adaptation is feasible, ReVision matches extensively fine-tuned alternatives while requiring orders of magnitude fewer trainable parameters and labeled examples. The learned representations also transfer effectively to new clinical sites, imaging domains, imaging modalities, and systemic health prediction tasks. In a prospective reader study with 33 ophthalmologists, ReVision's zero-shot assistance improved diagnostic accuracy by 14.8% across all experience levels. These results demonstrate that clinical native intelligence can be directly extracted from clinical archives without any further annotation to build medical AI systems suited to various low-resource settings.
Careful Queries, Credible Results: Teaching RAG Models Advanced Web Search Tools with Reinforcement Learning
Aug 11, 2025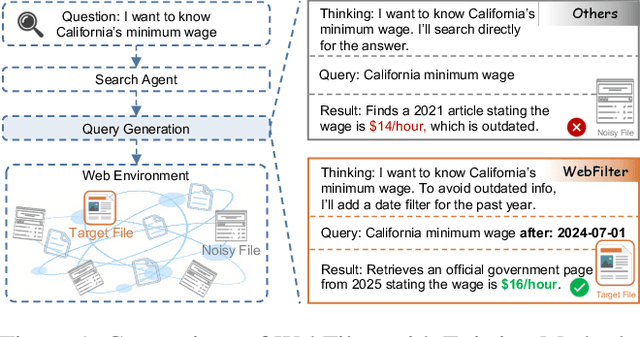
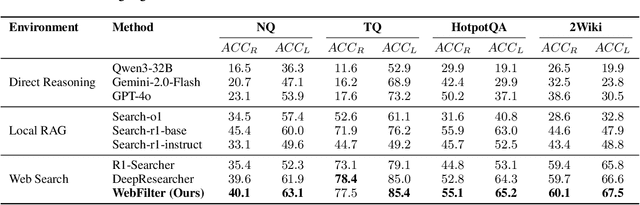
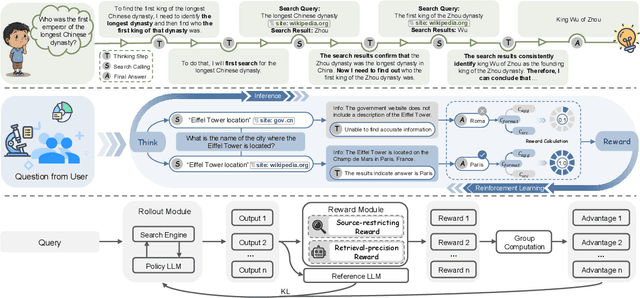
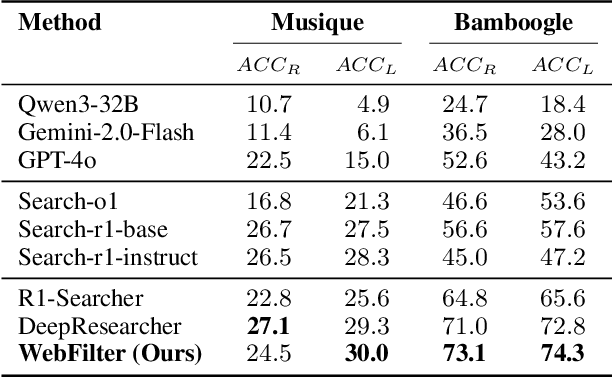
Retrieval-Augmented Generation (RAG) enhances large language models (LLMs) by integrating up-to-date external knowledge, yet real-world web environments present unique challenges. These limitations manifest as two key challenges: pervasive misinformation in the web environment, which introduces unreliable or misleading content that can degrade retrieval accuracy, and the underutilization of web tools, which, if effectively employed, could enhance query precision and help mitigate this noise, ultimately improving the retrieval results in RAG systems. To address these issues, we propose WebFilter, a novel RAG framework that generates source-restricted queries and filters out unreliable content. This approach combines a retrieval filtering mechanism with a behavior- and outcome-driven reward strategy, optimizing both query formulation and retrieval outcomes. Extensive experiments demonstrate that WebFilter improves answer quality and retrieval precision, outperforming existing RAG methods on both in-domain and out-of-domain benchmarks.
CLIPin: A Non-contrastive Plug-in to CLIP for Multimodal Semantic Alignment
Aug 08, 2025Large-scale natural image-text datasets, especially those automatically collected from the web, often suffer from loose semantic alignment due to weak supervision, while medical datasets tend to have high cross-modal correlation but low content diversity. These properties pose a common challenge for contrastive language-image pretraining (CLIP): they hinder the model's ability to learn robust and generalizable representations. In this work, we propose CLIPin, a unified non-contrastive plug-in that can be seamlessly integrated into CLIP-style architectures to improve multimodal semantic alignment, providing stronger supervision and enhancing alignment robustness. Furthermore, two shared pre-projectors are designed for image and text modalities respectively to facilitate the integration of contrastive and non-contrastive learning in a parameter-compromise manner. Extensive experiments on diverse downstream tasks demonstrate the effectiveness and generality of CLIPin as a plug-and-play component compatible with various contrastive frameworks. Code is available at https://github.com/T6Yang/CLIPin.
UrbanSense:AFramework for Quantitative Analysis of Urban Streetscapes leveraging Vision Large Language Models
Jun 12, 2025Urban cultures and architectural styles vary significantly across cities due to geographical, chronological, historical, and socio-political factors. Understanding these differences is essential for anticipating how cities may evolve in the future. As representative cases of historical continuity and modern innovation in China, Beijing and Shenzhen offer valuable perspectives for exploring the transformation of urban streetscapes. However, conventional approaches to urban cultural studies often rely on expert interpretation and historical documentation, which are difficult to standardize across different contexts. To address this, we propose a multimodal research framework based on vision-language models, enabling automated and scalable analysis of urban streetscape style differences. This approach enhances the objectivity and data-driven nature of urban form research. The contributions of this study are as follows: First, we construct UrbanDiffBench, a curated dataset of urban streetscapes containing architectural images from different periods and regions. Second, we develop UrbanSense, the first vision-language-model-based framework for urban streetscape analysis, enabling the quantitative generation and comparison of urban style representations. Third, experimental results show that Over 80% of generated descriptions pass the t-test (p less than 0.05). High Phi scores (0.912 for cities, 0.833 for periods) from subjective evaluations confirm the method's ability to capture subtle stylistic differences. These results highlight the method's potential to quantify and interpret urban style evolution, offering a scientifically grounded lens for future design.
FloorplanMAE:A self-supervised framework for complete floorplan generation from partial inputs
Jun 10, 2025In the architectural design process, floorplan design is often a dynamic and iterative process. Architects progressively draw various parts of the floorplan according to their ideas and requirements, continuously adjusting and refining throughout the design process. Therefore, the ability to predict a complete floorplan from a partial one holds significant value in the design process. Such prediction can help architects quickly generate preliminary designs, improve design efficiency, and reduce the workload associated with repeated modifications. To address this need, we propose FloorplanMAE, a self-supervised learning framework for restoring incomplete floor plans into complete ones. First, we developed a floor plan reconstruction dataset, FloorplanNet, specifically trained on architectural floor plans. Secondly, we propose a floor plan reconstruction method based on Masked Autoencoders (MAE), which reconstructs missing parts by masking sections of the floor plan and training a lightweight Vision Transformer (ViT). We evaluated the reconstruction accuracy of FloorplanMAE and compared it with state-of-the-art benchmarks. Additionally, we validated the model using real sketches from the early stages of architectural design. Experimental results show that the FloorplanMAE model can generate high-quality complete floor plans from incomplete partial plans. This framework provides a scalable solution for floor plan generation, with broad application prospects.
ArchiLense: A Framework for Quantitative Analysis of Architectural Styles Based on Vision Large Language Models
Jun 09, 2025Architectural cultures across regions are characterized by stylistic diversity, shaped by historical, social, and technological contexts in addition to geograph-ical conditions. Understanding architectural styles requires the ability to describe and analyze the stylistic features of different architects from various regions through visual observations of architectural imagery. However, traditional studies of architectural culture have largely relied on subjective expert interpretations and historical literature reviews, often suffering from regional biases and limited ex-planatory scope. To address these challenges, this study proposes three core contributions: (1) We construct a professional architectural style dataset named ArchDiffBench, which comprises 1,765 high-quality architectural images and their corresponding style annotations, collected from different regions and historical periods. (2) We propose ArchiLense, an analytical framework grounded in Vision-Language Models and constructed using the ArchDiffBench dataset. By integrating ad-vanced computer vision techniques, deep learning, and machine learning algo-rithms, ArchiLense enables automatic recognition, comparison, and precise classi-fication of architectural imagery, producing descriptive language outputs that ar-ticulate stylistic differences. (3) Extensive evaluations show that ArchiLense achieves strong performance in architectural style recognition, with a 92.4% con-sistency rate with expert annotations and 84.5% classification accuracy, effec-tively capturing stylistic distinctions across images. The proposed approach transcends the subjectivity inherent in traditional analyses and offers a more objective and accurate perspective for comparative studies of architectural culture.
A Cascading Cooperative Multi-agent Framework for On-ramp Merging Control Integrating Large Language Models
Mar 11, 2025Traditional Reinforcement Learning (RL) suffers from replicating human-like behaviors, generalizing effectively in multi-agent scenarios, and overcoming inherent interpretability issues.These tasks are compounded when deep environment understanding, agent coordination and dynamic optimization are required. While Large Language Model (LLM) enhanced methods have shown promise in generalization and interoperability, they often neglect necessary multi-agent coordination. Therefore, we introduce the Cascading Cooperative Multi-agent (CCMA) framework, integrating RL for individual interactions, a fine-tuned LLM for regional cooperation, a reward function for global optimization, and the Retrieval-augmented Generation mechanism to dynamically optimize decision-making across complex driving scenarios. Our experiments demonstrate that the CCMA outperforms existing RL methods, demonstrating significant improvements in both micro and macro-level performance in complex driving environments.
PromptLNet: Region-Adaptive Aesthetic Enhancement via Prompt Guidance in Low-Light Enhancement Net
Mar 11, 2025Learning and improving large language models through human preference feedback has become a mainstream approach, but it has rarely been applied to the field of low-light image enhancement. Existing low-light enhancement evaluations typically rely on objective metrics (such as FID, PSNR, etc.), which often result in models that perform well objectively but lack aesthetic quality. Moreover, most low-light enhancement models are primarily designed for global brightening, lacking detailed refinement. Therefore, the generated images often require additional local adjustments, leading to research gaps in practical applications. To bridge this gap, we propose the following innovations: 1) We collect human aesthetic evaluation text pairs and aesthetic scores from multiple low-light image datasets (e.g., LOL, LOL2, LOM, DCIM, MEF, etc.) to train a low-light image aesthetic evaluation model, supplemented by an optimization algorithm designed to fine-tune the diffusion model. 2) We propose a prompt-driven brightness adjustment module capable of performing fine-grained brightness and aesthetic adjustments for specific instances or regions. 3) We evaluate our method alongside existing state-of-the-art algorithms on mainstream benchmarks. Experimental results show that our method not only outperforms traditional methods in terms of visual quality but also provides greater flexibility and controllability, paving the way for improved aesthetic quality.
TSCnet: A Text-driven Semantic-level Controllable Framework for Customized Low-Light Image Enhancement
Mar 11, 2025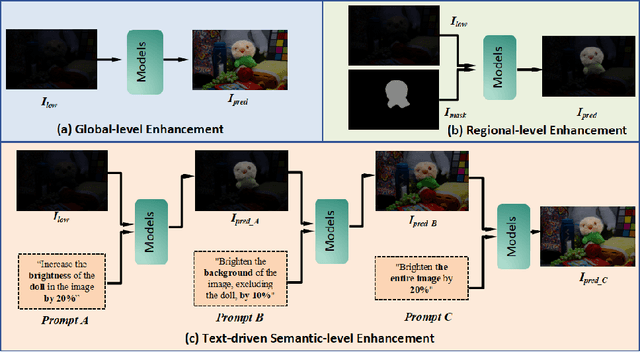
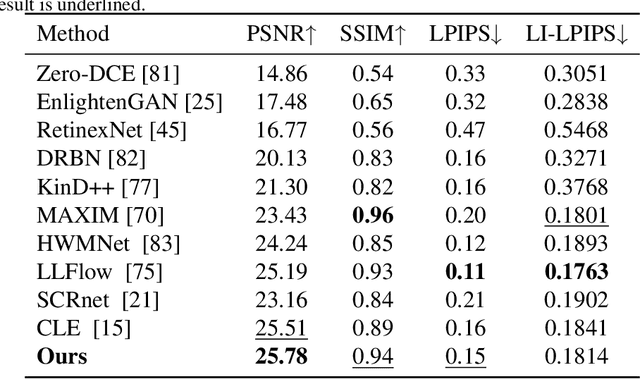
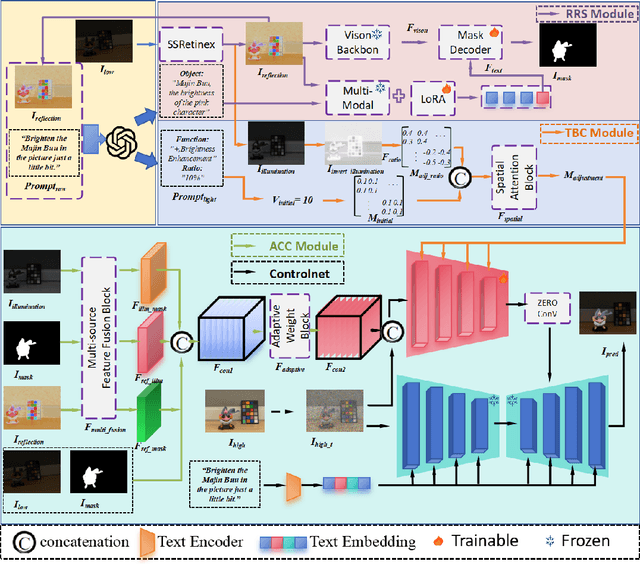
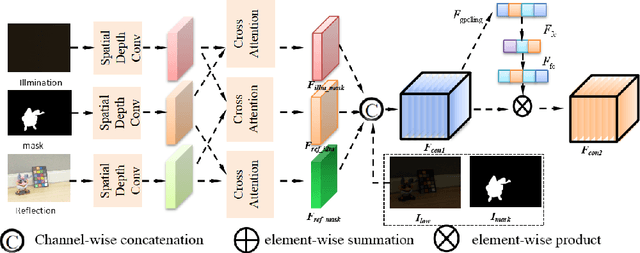
Deep learning-based image enhancement methods show significant advantages in reducing noise and improving visibility in low-light conditions. These methods are typically based on one-to-one mapping, where the model learns a direct transformation from low light to specific enhanced images. Therefore, these methods are inflexible as they do not allow highly personalized mapping, even though an individual's lighting preferences are inherently personalized. To overcome these limitations, we propose a new light enhancement task and a new framework that provides customized lighting control through prompt-driven, semantic-level, and quantitative brightness adjustments. The framework begins by leveraging a Large Language Model (LLM) to understand natural language prompts, enabling it to identify target objects for brightness adjustments. To localize these target objects, the Retinex-based Reasoning Segment (RRS) module generates precise target localization masks using reflection images. Subsequently, the Text-based Brightness Controllable (TBC) module adjusts brightness levels based on the generated illumination map. Finally, an Adaptive Contextual Compensation (ACC) module integrates multi-modal inputs and controls a conditional diffusion model to adjust the lighting, ensuring seamless and precise enhancements accurately. Experimental results on benchmark datasets demonstrate our framework's superior performance at increasing visibility, maintaining natural color balance, and amplifying fine details without creating artifacts. Furthermore, its robust generalization capabilities enable complex semantic-level lighting adjustments in diverse open-world environments through natural language interactions.
MindAligner: Explicit Brain Functional Alignment for Cross-Subject Visual Decoding from Limited fMRI Data
Feb 07, 2025



Brain decoding aims to reconstruct visual perception of human subject from fMRI signals, which is crucial for understanding brain's perception mechanisms. Existing methods are confined to the single-subject paradigm due to substantial brain variability, which leads to weak generalization across individuals and incurs high training costs, exacerbated by limited availability of fMRI data. To address these challenges, we propose MindAligner, an explicit functional alignment framework for cross-subject brain decoding from limited fMRI data. The proposed MindAligner enjoys several merits. First, we learn a Brain Transfer Matrix (BTM) that projects the brain signals of an arbitrary new subject to one of the known subjects, enabling seamless use of pre-trained decoding models. Second, to facilitate reliable BTM learning, a Brain Functional Alignment module is proposed to perform soft cross-subject brain alignment under different visual stimuli with a multi-level brain alignment loss, uncovering fine-grained functional correspondences with high interpretability. Experiments indicate that MindAligner not only outperforms existing methods in visual decoding under data-limited conditions, but also provides valuable neuroscience insights in cross-subject functional analysis. The code will be made publicly available.