 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUrbanSense:AFramework for Quantitative Analysis of Urban Streetscapes leveraging Vision Large Language Models
Jun 12, 2025Urban cultures and architectural styles vary significantly across cities due to geographical, chronological, historical, and socio-political factors. Understanding these differences is essential for anticipating how cities may evolve in the future. As representative cases of historical continuity and modern innovation in China, Beijing and Shenzhen offer valuable perspectives for exploring the transformation of urban streetscapes. However, conventional approaches to urban cultural studies often rely on expert interpretation and historical documentation, which are difficult to standardize across different contexts. To address this, we propose a multimodal research framework based on vision-language models, enabling automated and scalable analysis of urban streetscape style differences. This approach enhances the objectivity and data-driven nature of urban form research. The contributions of this study are as follows: First, we construct UrbanDiffBench, a curated dataset of urban streetscapes containing architectural images from different periods and regions. Second, we develop UrbanSense, the first vision-language-model-based framework for urban streetscape analysis, enabling the quantitative generation and comparison of urban style representations. Third, experimental results show that Over 80% of generated descriptions pass the t-test (p less than 0.05). High Phi scores (0.912 for cities, 0.833 for periods) from subjective evaluations confirm the method's ability to capture subtle stylistic differences. These results highlight the method's potential to quantify and interpret urban style evolution, offering a scientifically grounded lens for future design.
FloorplanMAE:A self-supervised framework for complete floorplan generation from partial inputs
Jun 10, 2025In the architectural design process, floorplan design is often a dynamic and iterative process. Architects progressively draw various parts of the floorplan according to their ideas and requirements, continuously adjusting and refining throughout the design process. Therefore, the ability to predict a complete floorplan from a partial one holds significant value in the design process. Such prediction can help architects quickly generate preliminary designs, improve design efficiency, and reduce the workload associated with repeated modifications. To address this need, we propose FloorplanMAE, a self-supervised learning framework for restoring incomplete floor plans into complete ones. First, we developed a floor plan reconstruction dataset, FloorplanNet, specifically trained on architectural floor plans. Secondly, we propose a floor plan reconstruction method based on Masked Autoencoders (MAE), which reconstructs missing parts by masking sections of the floor plan and training a lightweight Vision Transformer (ViT). We evaluated the reconstruction accuracy of FloorplanMAE and compared it with state-of-the-art benchmarks. Additionally, we validated the model using real sketches from the early stages of architectural design. Experimental results show that the FloorplanMAE model can generate high-quality complete floor plans from incomplete partial plans. This framework provides a scalable solution for floor plan generation, with broad application prospects.
ArchiLense: A Framework for Quantitative Analysis of Architectural Styles Based on Vision Large Language Models
Jun 09, 2025Architectural cultures across regions are characterized by stylistic diversity, shaped by historical, social, and technological contexts in addition to geograph-ical conditions. Understanding architectural styles requires the ability to describe and analyze the stylistic features of different architects from various regions through visual observations of architectural imagery. However, traditional studies of architectural culture have largely relied on subjective expert interpretations and historical literature reviews, often suffering from regional biases and limited ex-planatory scope. To address these challenges, this study proposes three core contributions: (1) We construct a professional architectural style dataset named ArchDiffBench, which comprises 1,765 high-quality architectural images and their corresponding style annotations, collected from different regions and historical periods. (2) We propose ArchiLense, an analytical framework grounded in Vision-Language Models and constructed using the ArchDiffBench dataset. By integrating ad-vanced computer vision techniques, deep learning, and machine learning algo-rithms, ArchiLense enables automatic recognition, comparison, and precise classi-fication of architectural imagery, producing descriptive language outputs that ar-ticulate stylistic differences. (3) Extensive evaluations show that ArchiLense achieves strong performance in architectural style recognition, with a 92.4% con-sistency rate with expert annotations and 84.5% classification accuracy, effec-tively capturing stylistic distinctions across images. The proposed approach transcends the subjectivity inherent in traditional analyses and offers a more objective and accurate perspective for comparative studies of architectural culture.
Segment Any Architectural Facades (SAAF):An automatic segmentation model for building facades, walls and windows based on multimodal semantics guidance
Jun 09, 2025In the context of the digital development of architecture, the automatic segmentation of walls and windows is a key step in improving the efficiency of building information models and computer-aided design. This study proposes an automatic segmentation model for building facade walls and windows based on multimodal semantic guidance, called Segment Any Architectural Facades (SAAF). First, SAAF has a multimodal semantic collaborative feature extraction mechanism. By combining natural language processing technology, it can fuse the semantic information in text descriptions with image features, enhancing the semantic understanding of building facade components. Second, we developed an end-to-end training framework that enables the model to autonomously learn the mapping relationship from text descriptions to image segmentation, reducing the influence of manual intervention on the segmentation results and improving the automation and robustness of the model. Finally, we conducted extensive experiments on multiple facade datasets. The segmentation results of SAAF outperformed existing methods in the mIoU metric, indicating that the SAAF model can maintain high-precision segmentation ability when faced with diverse datasets. Our model has made certain progress in improving the accuracy and generalization ability of the wall and window segmentation task. It is expected to provide a reference for the development of architectural computer vision technology and also explore new ideas and technical paths for the application of multimodal learning in the architectural field.
Automated Review Generation Method Based on Large Language Models
Jul 30, 2024

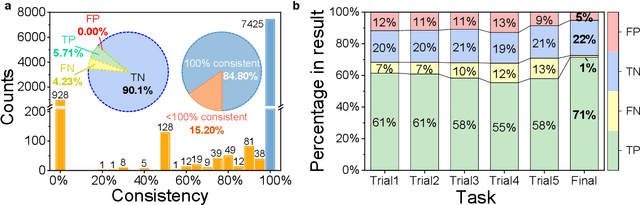
Literature research, vital for scientific advancement, is overwhelmed by the vast ocean of available information. Addressing this, we propose an automated review generation method based on Large Language Models (LLMs) to streamline literature processing and reduce cognitive load. In case study on propane dehydrogenation (PDH) catalysts, our method swiftly generated comprehensive reviews from 343 articles, averaging seconds per article per LLM account. Extended analysis of 1041 articles provided deep insights into catalysts' composition, structure, and performance. Recognizing LLMs' hallucinations, we employed a multi-layered quality control strategy, ensuring our method's reliability and effective hallucination mitigation. Expert verification confirms the accuracy and citation integrity of generated reviews, demonstrating LLM hallucination risks reduced to below 0.5% with over 95% confidence. Released Windows application enables one-click review generation, aiding researchers in tracking advancements and recommending literature. This approach showcases LLMs' role in enhancing scientific research productivity and sets the stage for further exploration.
Towards Efficient Task-Driven Model Reprogramming with Foundation Models
Apr 05, 2023

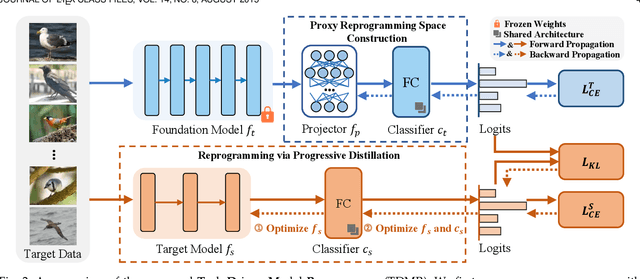
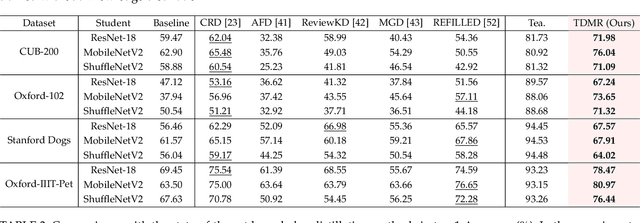
Vision foundation models exhibit impressive power, benefiting from the extremely large model capacity and broad training data. However, in practice, downstream scenarios may only support a small model due to the limited computational resources or efficiency considerations. Moreover, the data used for pretraining foundation models are usually invisible and very different from the target data of downstream tasks. This brings a critical challenge for the real-world application of foundation models: one has to transfer the knowledge of a foundation model to the downstream task that has a quite different architecture with only downstream target data. Existing transfer learning or knowledge distillation methods depend on either the same model structure or finetuning of the foundation model. Thus, naively introducing these methods can be either infeasible or very inefficient. To address this, we propose a Task-Driven Model Reprogramming (TDMR) framework. Specifically, we reprogram the foundation model to project the knowledge into a proxy space, which alleviates the adverse effect of task mismatch and domain inconsistency. Then, we reprogram the target model via progressive distillation from the proxy space to efficiently learn the knowledge from the reprogrammed foundation model. TDMR is compatible with different pre-trained model types (CNN, transformer or their mix) and limited target data, and promotes the wide applications of vision foundation models to downstream tasks in a cost-effective manner. Extensive experiments on different downstream classification tasks and target model structures demonstrate the effectiveness of our methods with both CNNs and transformer foundation models.