 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust and Efficient Cloud-Edge Elastic Model Adaptation via Selective Entropy Distillation
Feb 29, 2024The conventional deep learning paradigm often involves training a deep model on a server and then deploying the model or its distilled ones to resource-limited edge devices. Usually, the models shall remain fixed once deployed (at least for some period) due to the potential high cost of model adaptation for both the server and edge sides. However, in many real-world scenarios, the test environments may change dynamically (known as distribution shifts), which often results in degraded performance. Thus, one has to adapt the edge models promptly to attain promising performance. Moreover, with the increasing data collected at the edge, this paradigm also fails to further adapt the cloud model for better performance. To address these, we encounter two primary challenges: 1) the edge model has limited computation power and may only support forward propagation; 2) the data transmission budget between cloud and edge devices is limited in latency-sensitive scenarios. In this paper, we establish a Cloud-Edge Elastic Model Adaptation (CEMA) paradigm in which the edge models only need to perform forward propagation and the edge models can be adapted online. In our CEMA, to reduce the communication burden, we devise two criteria to exclude unnecessary samples from uploading to the cloud, i.e., dynamic unreliable and low-informative sample exclusion. Based on the uploaded samples, we update and distribute the affine parameters of normalization layers by distilling from the stronger foundation model to the edge model with a sample replay strategy. Extensive experimental results on ImageNet-C and ImageNet-R verify the effectiveness of our CEMA.
Towards Efficient Task-Driven Model Reprogramming with Foundation Models
Apr 05, 2023

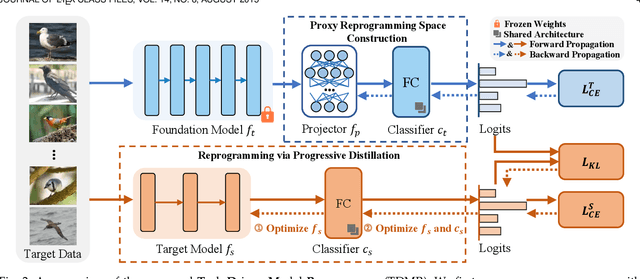
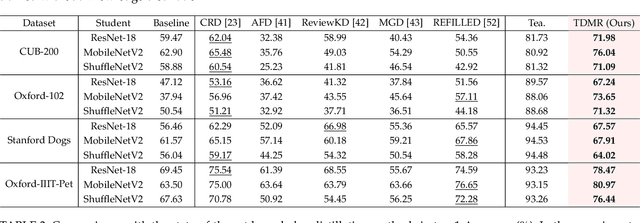
Vision foundation models exhibit impressive power, benefiting from the extremely large model capacity and broad training data. However, in practice, downstream scenarios may only support a small model due to the limited computational resources or efficiency considerations. Moreover, the data used for pretraining foundation models are usually invisible and very different from the target data of downstream tasks. This brings a critical challenge for the real-world application of foundation models: one has to transfer the knowledge of a foundation model to the downstream task that has a quite different architecture with only downstream target data. Existing transfer learning or knowledge distillation methods depend on either the same model structure or finetuning of the foundation model. Thus, naively introducing these methods can be either infeasible or very inefficient. To address this, we propose a Task-Driven Model Reprogramming (TDMR) framework. Specifically, we reprogram the foundation model to project the knowledge into a proxy space, which alleviates the adverse effect of task mismatch and domain inconsistency. Then, we reprogram the target model via progressive distillation from the proxy space to efficiently learn the knowledge from the reprogrammed foundation model. TDMR is compatible with different pre-trained model types (CNN, transformer or their mix) and limited target data, and promotes the wide applications of vision foundation models to downstream tasks in a cost-effective manner. Extensive experiments on different downstream classification tasks and target model structures demonstrate the effectiveness of our methods with both CNNs and transformer foundation models.
Generative Low-bitwidth Data Free Quantization
Mar 07, 2020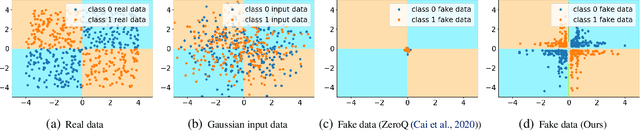
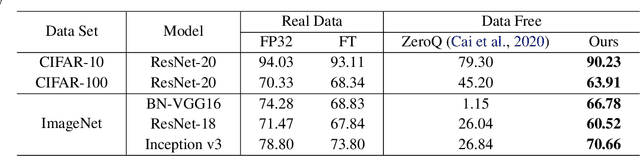
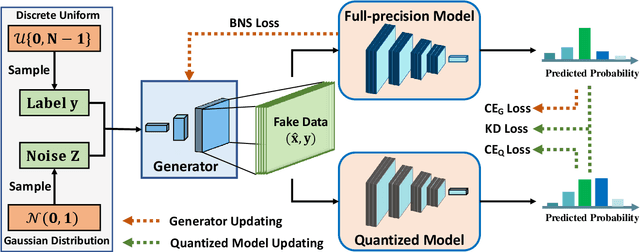
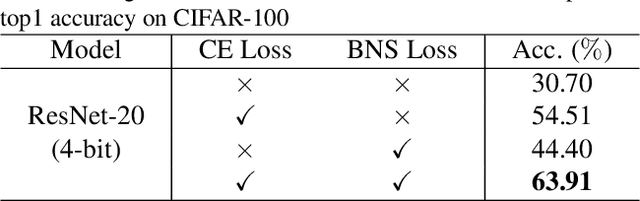
Neural network quantization is an effective way to compress deep models and improve the execution latency and energy efficiency, so that they can be deployed on mobile or embedded devices. Existing quantization methods require original data for calibration or fine-tuning to get better performance. However, in many real-world scenarios, the data may not be available due to confidential or private issues, making existing quantization methods not applicable. Moreover, due to the absence of original data, the recently developed generative adversarial networks (GANs) can not be applied to generate data. Although the full precision model may contain the entire data information, such information alone is hard to exploit for recovering the original data or generating new meaningful data. In this paper, we investigate a simple-yet-effective method called Generative Low-bitwidth Data Free Quantization to remove the data dependence burden. Specifically, we propose a Knowledge Matching Generator to produce meaningful fake data by exploiting classification boundary knowledge and distribution information in the pre-trained model. With the help of generated data, we are able to quantize a model by learning knowledge from the pre-trained model. Extensive experiments on three data sets demonstrate the effectiveness of our method. More critically, our method achieves much higher accuracy on 4-bit quantization than the existing data free quantization method.