 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent-Condensed Transformer for Efficient Long Context Modeling
Apr 14, 2026Large language models (LLMs) face significant challenges in processing long contexts due to the linear growth of the key-value (KV) cache and quadratic complexity of self-attention. Existing approaches address these bottlenecks separately: Multi-head Latent Attention (MLA) reduces the KV cache by projecting tokens into a low-dimensional latent space, while sparse attention reduces computation. However, sparse methods cannot operate natively on MLA's compressed latent structure, missing opportunities for joint optimization. In this paper, we propose Latent-Condensed Attention (LCA), which directly condenses context within MLA's latent space, where the representation is disentangled into semantic latent vectors and positional keys. LCA separately aggregates semantic vectors via query-aware pooling and preserves positional keys via anchor selection. This approach jointly reduces both computational cost and KV cache without adding parameters. Beyond MLA, LCA's design is architecture-agnostic and readily extends to other attention mechanisms such as GQA. Theoretically, we prove a length-independent error bound. Experiments show LCA achieves up to 2.5$\times$ prefilling speedup and 90% KV cache reduction at 128K context while maintaining competitive performance.
Precedent-Informed Reasoning: Mitigating Overthinking in Large Reasoning Models via Test-Time Precedent Learning
Feb 16, 2026Reasoning in Large Language Models (LLMs) often suffers from inefficient long chain-of-thought traces with redundant self-exploration and validation, which inflate computational costs and even degrade performance. Inspired by human reasoning patterns where people solve new problems by leveraging past related cases to constrain search spaces and reduce trial-and-error, we propose Precedent Informed Reasoning (PIR) transforming LRMs'reasoning paradigm from exhaustive self-exploration to guided learning from precedents. PIR addresses two key challenges: what precedents to adopt and how to utilize them. First, Adaptive Precedent Selection (APS) constructs, for each question and LRM, a compact set of precedents that are both semantically related and informative for the model. It ranks examples by a joint score with semantic similarity and model perplexity, then adapts the amount of precedents to maximize perplexity reduction. Second, Test-time Experience Internalization (TEI) is treated as the test-time learning on precedent-informed instruction, updating lightweight adapters to internalize solution patterns and use them as a prior during subsequent reasoning. Experiments across mathematical reasoning, scientific QA, and code generation demonstrate that PIR consistently shortens reasoning traces while maintaining or improving final accuracy across LLMs, yielding outstanding accuracy-efficiency trade-offs.
Beyond Model Scaling: Test-Time Intervention for Efficient Deep Reasoning
Jan 16, 2026Large Reasoning Models (LRMs) excel at multi-step reasoning but often suffer from inefficient reasoning processes like overthinking and overshoot, where excessive or misdirected reasoning increases computational cost and degrades performance. Existing efficient reasoning methods operate in a closed-loop manner, lacking mechanisms for external intervention to guide the reasoning process. To address this, we propose Think-with-Me, a novel test-time interactive reasoning paradigm that introduces external feedback intervention into the reasoning process. Our key insights are that transitional conjunctions serve as natural points for intervention, signaling phases of self-validation or exploration and using transitional words appropriately to prolong the reasoning enhances performance, while excessive use affects performance. Building on these insights, Think-with-Me pauses reasoning at these points for external feedback, adaptively extending or terminating reasoning to reduce redundancy while preserving accuracy. The feedback is generated via a multi-criteria evaluation (rationality and completeness) and comes from either human or LLM proxies. We train the target model using Group Relative Policy Optimization (GRPO) to adapt to this interactive mode. Experiments show that Think-with-Me achieves a superior balance between accuracy and reasoning length under limited context windows. On AIME24, Think-with-Me outperforms QwQ-32B by 7.19% in accuracy while reducing average reasoning length by 81% under an 8K window. The paradigm also benefits security and creative tasks.
ProCache: Constraint-Aware Feature Caching with Selective Computation for Diffusion Transformer Acceleration
Dec 19, 2025Diffusion Transformers (DiTs) have achieved state-of-the-art performance in generative modeling, yet their high computational cost hinders real-time deployment. While feature caching offers a promising training-free acceleration solution by exploiting temporal redundancy, existing methods suffer from two key limitations: (1) uniform caching intervals fail to align with the non-uniform temporal dynamics of DiT, and (2) naive feature reuse with excessively large caching intervals can lead to severe error accumulation. In this work, we analyze the evolution of DiT features during denoising and reveal that both feature changes and error propagation are highly time- and depth-varying. Motivated by this, we propose ProCache, a training-free dynamic feature caching framework that addresses these issues via two core components: (i) a constraint-aware caching pattern search module that generates non-uniform activation schedules through offline constrained sampling, tailored to the model's temporal characteristics; and (ii) a selective computation module that selectively computes within deep blocks and high-importance tokens for cached segments to mitigate error accumulation with minimal overhead. Extensive experiments on PixArt-alpha and DiT demonstrate that ProCache achieves up to 1.96x and 2.90x acceleration with negligible quality degradation, significantly outperforming prior caching-based methods.
Beyond Fast and Slow: Cognitive-Inspired Elastic Reasoning for Large Language Models
Dec 17, 2025Large language models (LLMs) have demonstrated impressive performance across various language tasks. However, existing LLM reasoning strategies mainly rely on the LLM itself with fast or slow mode (like o1 thinking) and thus struggle to balance reasoning efficiency and accuracy across queries of varying difficulties. In this paper, we propose Cognitive-Inspired Elastic Reasoning (CogER), a framework inspired by human hierarchical reasoning that dynamically selects the most suitable reasoning strategy for each query. Specifically, CogER first assesses the complexity of incoming queries and assigns them to one of several predefined levels, each corresponding to a tailored processing strategy, thereby addressing the challenge of unobservable query difficulty. To achieve automatic strategy selection, we model the process as a Markov Decision Process and train a CogER-Agent using reinforcement learning. The agent is guided by a reward function that balances solution quality and computational cost, ensuring resource-efficient reasoning. Moreover, for queries requiring external tools, we introduce Cognitive Tool-Assisted Reasoning, which enables the LLM to autonomously invoke external tools within its chain-of-thought. Extensive experiments demonstrate that CogER outperforms state-of-the-art Test-Time scaling methods, achieving at least a 13% relative improvement in average exact match on In-Domain tasks and an 8% relative gain on Out-of-Domain tasks.
Training-free Context-adaptive Attention for Efficient Long Context Modeling
Dec 10, 2025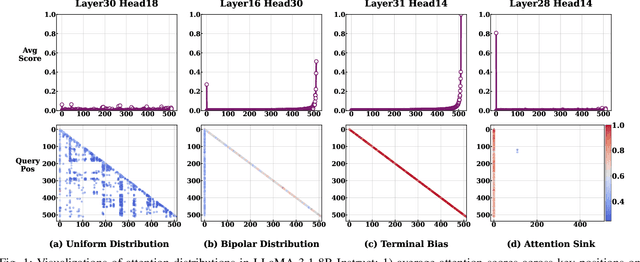
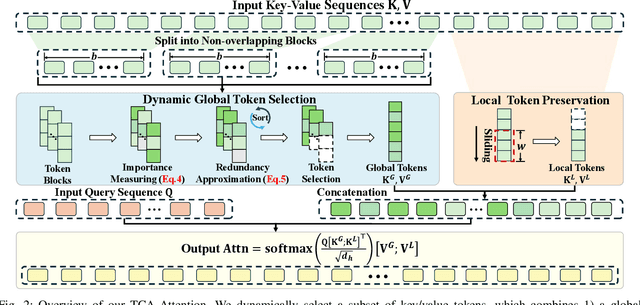
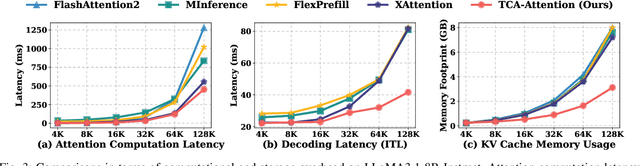
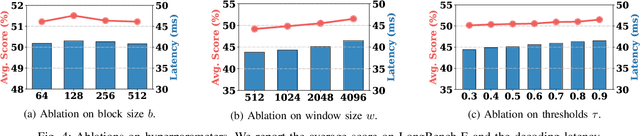
Large Language Models (LLMs) have demonstrated remarkable capabilities across a wide range of natural language processing tasks. These capabilities stem primarily from the self-attention mechanism, which enables modeling of long-range dependencies. However, the quadratic complexity of self-attention with respect to sequence length poses significant computational and memory challenges, especially as sequence length extends to extremes. While various sparse attention and KV cache compression methods have been proposed to improve efficiency, they often suffer from limitations such as reliance on fixed patterns, inability to handle both prefilling and decoding stages, or the requirement for additional training. In this paper, we propose Training-free Context-adaptive Attention (TCA-Attention), a training-free sparse attention mechanism that selectively attends to only the informative tokens for efficient long-context inference. Our method consists of two lightweight phases: i) an offline calibration phase that determines head-specific sparsity budgets via a single forward pass, and ii) an online token selection phase that adaptively retains core context tokens using a lightweight redundancy metric. TCA-Attention provides a unified solution that accelerates both prefilling and decoding while reducing KV cache memory footprint, without requiring parameter updates or architectural changes. Theoretical analysis shows that our approach maintains bounded approximation error. Extensive experiments demonstrate that TCA-Attention achieves a 2.8$\times$ speedup and reduces KV cache by 61% at 128K context length while maintaining performance comparable to full attention across various benchmarks, offering a practical plug-and-play solution for efficient long-context inference.
Adapt in the Wild: Test-Time Entropy Minimization with Sharpness and Feature Regularization
Sep 05, 2025Test-time adaptation (TTA) may fail to improve or even harm the model performance when test data have: 1) mixed distribution shifts, 2) small batch sizes, 3) online imbalanced label distribution shifts. This is often a key obstacle preventing existing TTA methods from being deployed in the real world. In this paper, we investigate the unstable reasons and find that the batch norm layer is a crucial factor hindering TTA stability. Conversely, TTA can perform more stably with batch-agnostic norm layers, i.e., group or layer norm. However, we observe that TTA with group and layer norms does not always succeed and still suffers many failure cases, i.e., the model collapses into trivial solutions by assigning the same class label for all samples. By digging into this, we find that, during the collapse process: 1) the model gradients often undergo an initial explosion followed by rapid degradation, suggesting that certain noisy test samples with large gradients may disrupt adaptation; and 2) the model representations tend to exhibit high correlations and classification bias. To address this, we first propose a sharpness-aware and reliable entropy minimization method, called SAR, for stabilizing TTA from two aspects: 1) remove partial noisy samples with large gradients, 2) encourage model weights to go to a flat minimum so that the model is robust to the remaining noisy samples. Based on SAR, we further introduce SAR^2 to prevent representation collapse with two regularizers: 1) a redundancy regularizer to reduce inter-dimensional correlations among centroid-invariant features; and 2) an inequity regularizer to maximize the prediction entropy of a prototype centroid, thereby penalizing biased representations toward any specific class. Promising results demonstrate that our methods perform more stably over prior methods and are computationally efficient under the above wild test scenarios.
Curse of High Dimensionality Issue in Transformer for Long-context Modeling
May 28, 2025Transformer-based large language models (LLMs) excel in natural language processing tasks by capturing long-range dependencies through self-attention mechanisms. However, long-context modeling faces significant computational inefficiencies due to \textit{redundant} attention computations: while attention weights are often \textit{sparse}, all tokens consume \textit{equal} computational resources. In this paper, we reformulate traditional probabilistic sequence modeling as a \textit{supervised learning task}, enabling the separation of relevant and irrelevant tokens and providing a clearer understanding of redundancy. Based on this reformulation, we theoretically analyze attention sparsity, revealing that only a few tokens significantly contribute to predictions. Building on this, we formulate attention optimization as a linear coding problem and propose a \textit{group coding strategy}, theoretically showing its ability to improve robustness against random noise and enhance learning efficiency. Motivated by this, we propose \textit{Dynamic Group Attention} (DGA), which leverages the group coding to explicitly reduce redundancy by aggregating less important tokens during attention computation. Empirical results show that our DGA significantly reduces computational costs while maintaining competitive performance.Code is available at https://github.com/bolixinyu/DynamicGroupAttention.
Learning to Generate Gradients for Test-Time Adaptation via Test-Time Training Layers
Dec 22, 2024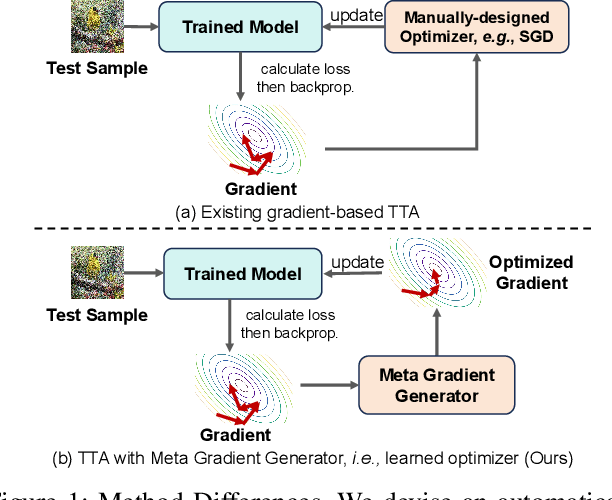
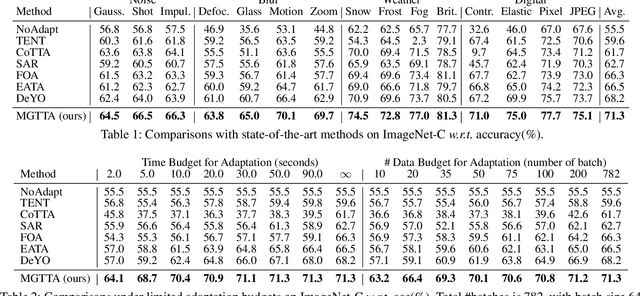
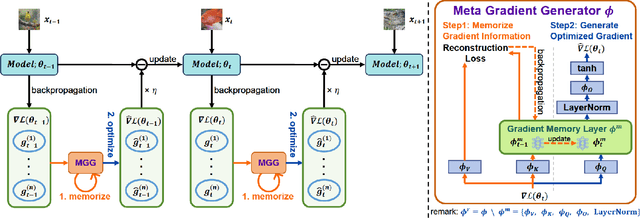
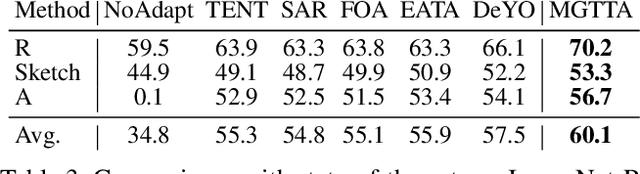
Test-time adaptation (TTA) aims to fine-tune a trained model online using unlabeled testing data to adapt to new environments or out-of-distribution data, demonstrating broad application potential in real-world scenarios. However, in this optimization process, unsupervised learning objectives like entropy minimization frequently encounter noisy learning signals. These signals produce unreliable gradients, which hinder the model ability to converge to an optimal solution quickly and introduce significant instability into the optimization process. In this paper, we seek to resolve these issues from the perspective of optimizer design. Unlike prior TTA using manually designed optimizers like SGD, we employ a learning-to-optimize approach to automatically learn an optimizer, called Meta Gradient Generator (MGG). Specifically, we aim for MGG to effectively utilize historical gradient information during the online optimization process to optimize the current model. To this end, in MGG, we design a lightweight and efficient sequence modeling layer -- gradient memory layer. It exploits a self-supervised reconstruction loss to compress historical gradient information into network parameters, thereby enabling better memorization ability over a long-term adaptation process. We only need a small number of unlabeled samples to pre-train MGG, and then the trained MGG can be deployed to process unseen samples. Promising results on ImageNet-C, R, Sketch, and A indicate that our method surpasses current state-of-the-art methods with fewer updates, less data, and significantly shorter adaptation iterations. Compared with a previous SOTA method SAR, we achieve 7.4% accuracy improvement and 4.2 times faster adaptation speed on ImageNet-C.
* 3 figures, 11 tables
Core Context Aware Attention for Long Context Language Modeling
Dec 17, 2024



Transformer-based Large Language Models (LLMs) have exhibited remarkable success in various natural language processing tasks primarily attributed to self-attention mechanism, which requires a token to consider all preceding tokens as its context to compute the attention score. However, when the context length L becomes very large (e.g., 32K), more redundant context information will be included w.r.t. any tokens, making the self-attention suffer from two main limitations: 1) The computational and memory complexity scales quadratically w.r.t. L; 2) The presence of redundant context information may hamper the model to capture dependencies among crucial tokens, which may degrade the representation performance. In this paper, we propose a plug-and-play Core Context Aware (CCA) Attention for efficient long-range context modeling, which consists of two components: 1) Globality-pooling attention that divides input tokens into groups and then dynamically merges tokens within each group into one core token based on their significance; 2) Locality-preserved attention that incorporates neighboring tokens into the attention calculation. The two complementary attentions will then be fused to the final attention, maintaining comprehensive modeling ability as the full self-attention. In this way, the core context information w.r.t. a given token will be automatically focused and strengthened, while the context information in redundant groups will be diminished during the learning process. As a result, the computational and memory complexity will be significantly reduced. More importantly, the CCA-Attention can improve the long-context modeling ability by diminishing the redundant context information. Extensive experimental results demonstrate that our CCA-Attention significantly outperforms state-of-the-art models in terms of computational efficiency and long-context modeling ability.