 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Electromagnetic Structure Design Under Limited Evaluation Budgets
Jun 24, 2025Electromagnetic structure (EMS) design plays a critical role in developing advanced antennas and materials, but remains challenging due to high-dimensional design spaces and expensive evaluations. While existing methods commonly employ high-quality predictors or generators to alleviate evaluations, they are often data-intensive and struggle with real-world scale and budget constraints. To address this, we propose a novel method called Progressive Quadtree-based Search (PQS). Rather than exhaustively exploring the high-dimensional space, PQS converts the conventional image-like layout into a quadtree-based hierarchical representation, enabling a progressive search from global patterns to local details. Furthermore, to lessen reliance on highly accurate predictors, we introduce a consistency-driven sample selection mechanism. This mechanism quantifies the reliability of predictions, balancing exploitation and exploration when selecting candidate designs. We evaluate PQS on two real-world engineering tasks, i.e., Dual-layer Frequency Selective Surface and High-gain Antenna. Experimental results show that our method can achieve satisfactory designs under limited computational budgets, outperforming baseline methods. In particular, compared to generative approaches, it cuts evaluation costs by 75-85%, effectively saving 20.27-38.80 days of product designing cycle.
Efficient Test-Time Model Adaptation without Forgetting
Apr 06, 2022
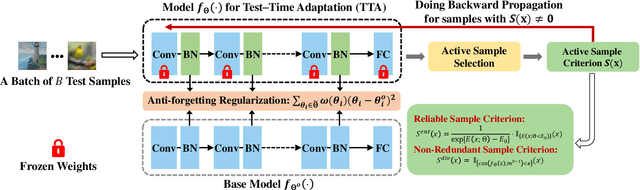
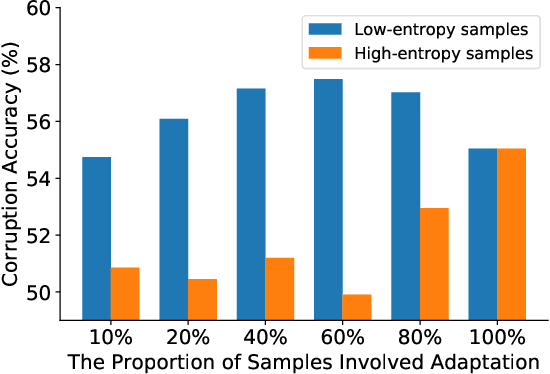

Test-time adaptation (TTA) seeks to tackle potential distribution shifts between training and testing data by adapting a given model w.r.t. any testing sample. This task is particularly important for deep models when the test environment changes frequently. Although some recent attempts have been made to handle this task, we still face two practical challenges: 1) existing methods have to perform backward computation for each test sample, resulting in unbearable prediction cost to many applications; 2) while existing TTA solutions can significantly improve the test performance on out-of-distribution data, they often suffer from severe performance degradation on in-distribution data after TTA (known as catastrophic forgetting). In this paper, we point out that not all the test samples contribute equally to model adaptation, and high-entropy ones may lead to noisy gradients that could disrupt the model. Motivated by this, we propose an active sample selection criterion to identify reliable and non-redundant samples, on which the model is updated to minimize the entropy loss for test-time adaptation. Furthermore, to alleviate the forgetting issue, we introduce a Fisher regularizer to constrain important model parameters from drastic changes, where the Fisher importance is estimated from test samples with generated pseudo labels. Extensive experiments on CIFAR-10-C, ImageNet-C, and ImageNet-R verify the effectiveness of our proposed method.