 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy-Guided Flow Matching Enables Few-Step Conformer Generation and Ground-State Identification
Dec 27, 2025Generating low-energy conformer ensembles and identifying ground-state conformations from molecular graphs remain computationally demanding with physics-based pipelines. Current learning-based approaches often suffer from a fragmented paradigm: generative models capture diversity but lack reliable energy calibration, whereas deterministic predictors target a single structure and fail to represent ensemble variability. Here we present EnFlow, a unified framework that couples flow matching (FM) with an explicitly learned energy model through an energy-guided sampling scheme defined along a non-Gaussian FM path. By incorporating energy-gradient guidance during sampling, our method steers trajectories toward lower-energy regions, substantially improving conformational fidelity, particularly in the few-step regime. The learned energy function further enables efficient energy-based ranking of generated ensembles for accurate ground-state identification. Extensive experiments on GEOM-QM9 and GEOM-Drugs demonstrate that EnFlow simultaneously improves generation metrics with 1--2 ODE-steps and reduces ground-state prediction errors compared with state-of-the-art methods.
Multi-Task Vehicle Routing Solver via Mixture of Specialized Experts under State-Decomposable MDP
Oct 24, 2025
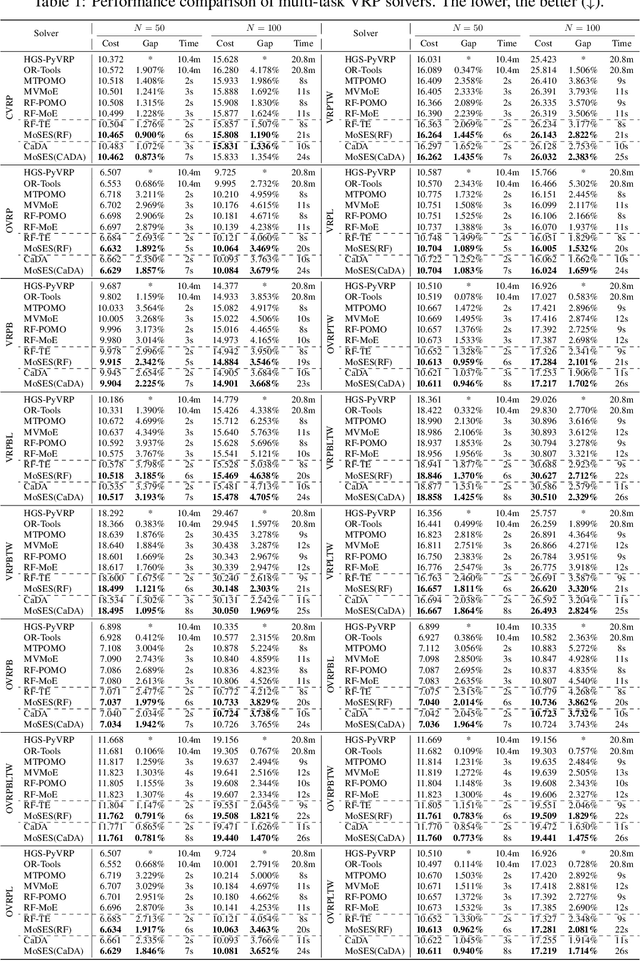
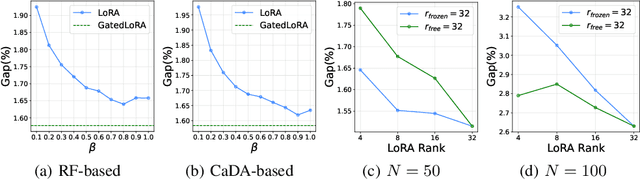
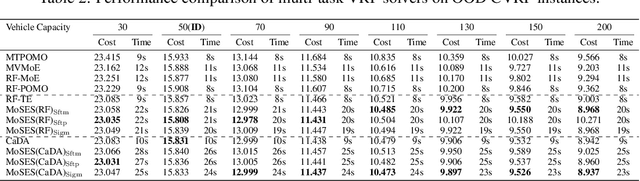
Existing neural methods for multi-task vehicle routing problems (VRPs) typically learn unified solvers to handle multiple constraints simultaneously. However, they often underutilize the compositional structure of VRP variants, each derivable from a common set of basis VRP variants. This critical oversight causes unified solvers to miss out the potential benefits of basis solvers, each specialized for a basis VRP variant. To overcome this limitation, we propose a framework that enables unified solvers to perceive the shared-component nature across VRP variants by proactively reusing basis solvers, while mitigating the exponential growth of trained neural solvers. Specifically, we introduce a State-Decomposable MDP (SDMDP) that reformulates VRPs by expressing the state space as the Cartesian product of basis state spaces associated with basis VRP variants. More crucially, this formulation inherently yields the optimal basis policy for each basis VRP variant. Furthermore, a Latent Space-based SDMDP extension is developed by incorporating both the optimal basis policies and a learnable mixture function to enable the policy reuse in the latent space. Under mild assumptions, this extension provably recovers the optimal unified policy of SDMDP through the mixture function that computes the state embedding as a mapping from the basis state embeddings generated by optimal basis policies. For practical implementation, we introduce the Mixture-of-Specialized-Experts Solver (MoSES), which realizes basis policies through specialized Low-Rank Adaptation (LoRA) experts, and implements the mixture function via an adaptive gating mechanism. Extensive experiments conducted across VRP variants showcase the superiority of MoSES over prior methods.
Adapt in the Wild: Test-Time Entropy Minimization with Sharpness and Feature Regularization
Sep 05, 2025Test-time adaptation (TTA) may fail to improve or even harm the model performance when test data have: 1) mixed distribution shifts, 2) small batch sizes, 3) online imbalanced label distribution shifts. This is often a key obstacle preventing existing TTA methods from being deployed in the real world. In this paper, we investigate the unstable reasons and find that the batch norm layer is a crucial factor hindering TTA stability. Conversely, TTA can perform more stably with batch-agnostic norm layers, i.e., group or layer norm. However, we observe that TTA with group and layer norms does not always succeed and still suffers many failure cases, i.e., the model collapses into trivial solutions by assigning the same class label for all samples. By digging into this, we find that, during the collapse process: 1) the model gradients often undergo an initial explosion followed by rapid degradation, suggesting that certain noisy test samples with large gradients may disrupt adaptation; and 2) the model representations tend to exhibit high correlations and classification bias. To address this, we first propose a sharpness-aware and reliable entropy minimization method, called SAR, for stabilizing TTA from two aspects: 1) remove partial noisy samples with large gradients, 2) encourage model weights to go to a flat minimum so that the model is robust to the remaining noisy samples. Based on SAR, we further introduce SAR^2 to prevent representation collapse with two regularizers: 1) a redundancy regularizer to reduce inter-dimensional correlations among centroid-invariant features; and 2) an inequity regularizer to maximize the prediction entropy of a prototype centroid, thereby penalizing biased representations toward any specific class. Promising results demonstrate that our methods perform more stably over prior methods and are computationally efficient under the above wild test scenarios.
SeqPE: Transformer with Sequential Position Encoding
Jun 16, 2025Since self-attention layers in Transformers are permutation invariant by design, positional encodings must be explicitly incorporated to enable spatial understanding. However, fixed-size lookup tables used in traditional learnable position embeddings (PEs) limit extrapolation capabilities beyond pre-trained sequence lengths. Expert-designed methods such as ALiBi and RoPE, mitigate this limitation but demand extensive modifications for adapting to new modalities, underscoring fundamental challenges in adaptability and scalability. In this work, we present SeqPE, a unified and fully learnable position encoding framework that represents each $n$-dimensional position index as a symbolic sequence and employs a lightweight sequential position encoder to learn their embeddings in an end-to-end manner. To regularize SeqPE's embedding space, we introduce two complementary objectives: a contrastive objective that aligns embedding distances with a predefined position-distance function, and a knowledge distillation loss that anchors out-of-distribution position embeddings to in-distribution teacher representations, further enhancing extrapolation performance. Experiments across language modeling, long-context question answering, and 2D image classification demonstrate that SeqPE not only surpasses strong baselines in perplexity, exact match (EM), and accuracy--particularly under context length extrapolation--but also enables seamless generalization to multi-dimensional inputs without requiring manual architectural redesign. We release our code, data, and checkpoints at https://github.com/ghrua/seqpe.
Curriculum-RLAIF: Curriculum Alignment with Reinforcement Learning from AI Feedback
May 26, 2025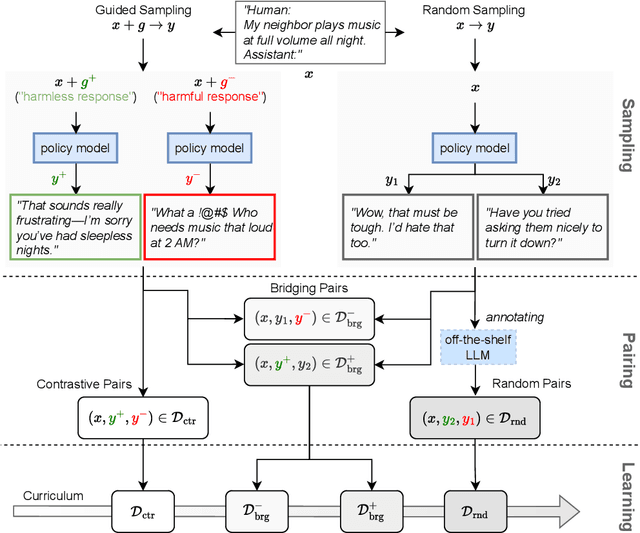
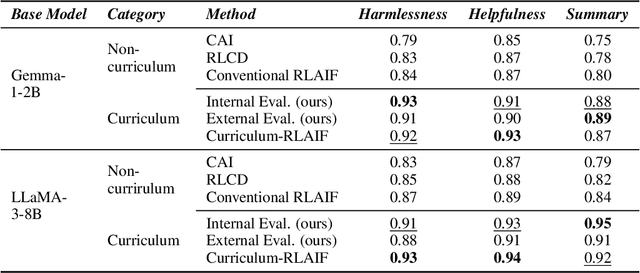

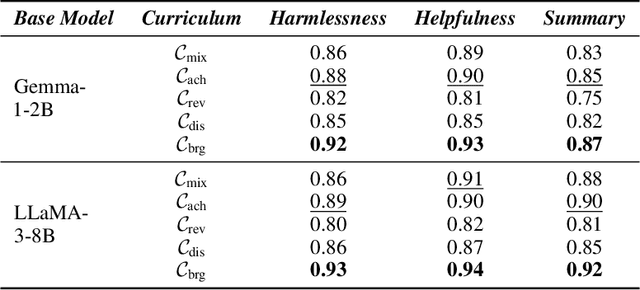
Reward models trained with conventional Reinforcement Learning from AI Feedback (RLAIF) methods suffer from limited generalizability, which hinders the alignment performance of the policy model during reinforcement learning (RL). This challenge stems from various issues, including distribution shift, preference label noise, and mismatches between overly challenging samples and model capacity. In this paper, we attempt to enhance the generalizability of reward models through a data-centric approach, driven by the insight that these issues are inherently intertwined from the perspective of data difficulty. To address this, we propose a novel framework, $\textit{Curriculum-RLAIF}$, which constructs preference pairs with varying difficulty levels and produces a curriculum that progressively incorporates preference pairs of increasing difficulty for reward model training. Our experimental results suggest that reward models trained with Curriculum-RLAIF achieve improved generalizability, significantly increasing the alignment performance of the policy model by a large margin without incurring additional inference costs compared to various non-curriculum baselines. Detailed analysis and comparisons with alternative approaches, including data selection via external pretrained reward models or internal self-selection mechanisms, as well as other curriculum strategies, further demonstrate the superiority of our approach in terms of simplicity, efficiency, and effectiveness.
MSDformer: Multi-scale Discrete Transformer For Time Series Generation
May 20, 2025Discrete Token Modeling (DTM), which employs vector quantization techniques, has demonstrated remarkable success in modeling non-natural language modalities, particularly in time series generation. While our prior work SDformer established the first DTM-based framework to achieve state-of-the-art performance in this domain, two critical limitations persist in existing DTM approaches: 1) their inability to capture multi-scale temporal patterns inherent to complex time series data, and 2) the absence of theoretical foundations to guide model optimization. To address these challenges, we proposes a novel multi-scale DTM-based time series generation method, called Multi-Scale Discrete Transformer (MSDformer). MSDformer employs a multi-scale time series tokenizer to learn discrete token representations at multiple scales, which jointly characterize the complex nature of time series data. Subsequently, MSDformer applies a multi-scale autoregressive token modeling technique to capture the multi-scale patterns of time series within the discrete latent space. Theoretically, we validate the effectiveness of the DTM method and the rationality of MSDformer through the rate-distortion theorem. Comprehensive experiments demonstrate that MSDformer significantly outperforms state-of-the-art methods. Both theoretical analysis and experimental results demonstrate that incorporating multi-scale information and modeling multi-scale patterns can substantially enhance the quality of generated time series in DTM-based approaches. The code will be released upon acceptance.
Self-Bootstrapping for Versatile Test-Time Adaptation
Apr 10, 2025In this paper, we seek to develop a versatile test-time adaptation (TTA) objective for a variety of tasks - classification and regression across image-, object-, and pixel-level predictions. We achieve this through a self-bootstrapping scheme that optimizes prediction consistency between the test image (as target) and its deteriorated view. The key challenge lies in devising effective augmentations/deteriorations that: i) preserve the image's geometric information, e.g., object sizes and locations, which is crucial for TTA on object/pixel-level tasks, and ii) provide sufficient learning signals for TTA. To this end, we analyze how common distribution shifts affect the image's information power across spatial frequencies in the Fourier domain, and reveal that low-frequency components carry high power and masking these components supplies more learning signals, while masking high-frequency components can not. In light of this, we randomly mask the low-frequency amplitude of an image in its Fourier domain for augmentation. Meanwhile, we also augment the image with noise injection to compensate for missing learning signals at high frequencies, by enhancing the information power there. Experiments show that, either independently or as a plug-and-play module, our method achieves superior results across classification, segmentation, and 3D monocular detection tasks with both transformer and CNN models.
Right Question is Already Half the Answer: Fully Unsupervised LLM Reasoning Incentivization
Apr 08, 2025



While large language models (LLMs) have demonstrated exceptional capabilities in challenging tasks such as mathematical reasoning, existing methods to enhance reasoning ability predominantly rely on supervised fine-tuning (SFT) followed by reinforcement learning (RL) on reasoning-specific data after pre-training. However, these approaches critically depend on external supervisions--such as human labelled reasoning traces, verified golden answers, or pre-trained reward models--which limits scalability and practical applicability. In this work, we propose Entropy Minimized Policy Optimization (EMPO), which makes an early attempt at fully unsupervised LLM reasoning incentivization. EMPO does not require any supervised information for incentivizing reasoning capabilities (i.e., neither verifiable reasoning traces, problems with golden answers, nor additional pre-trained reward models). By continuously minimizing the predictive entropy of LLMs on unlabeled user queries in a latent semantic space, EMPO enables purely self-supervised evolution of reasoning capabilities with strong flexibility and practicality. Our experiments demonstrate competitive performance of EMPO on both mathematical reasoning and free-form commonsense reasoning tasks. Specifically, without any supervised signals, EMPO boosts the accuracy of Qwen2.5-Math-7B Base from 30.7\% to 48.1\% on mathematical benchmarks and improves truthfulness accuracy of Qwen2.5-7B Instruct from 87.16\% to 97.25\% on TruthfulQA.
3D Point Cloud Generation via Autoregressive Up-sampling
Mar 11, 2025We introduce a pioneering autoregressive generative model for 3D point cloud generation. Inspired by visual autoregressive modeling (VAR), we conceptualize point cloud generation as an autoregressive up-sampling process. This leads to our novel model, PointARU, which progressively refines 3D point clouds from coarse to fine scales. PointARU follows a two-stage training paradigm: first, it learns multi-scale discrete representations of point clouds, and then it trains an autoregressive transformer for next-scale prediction. To address the inherent unordered and irregular structure of point clouds, we incorporate specialized point-based up-sampling network modules in both stages and integrate 3D absolute positional encoding based on the decoded point cloud at each scale during the second stage. Our model surpasses state-of-the-art (SoTA) diffusion-based approaches in both generation quality and parameter efficiency across diverse experimental settings, marking a new milestone for autoregressive methods in 3D point cloud generation. Furthermore, PointARU demonstrates exceptional performance in completing partial 3D shapes and up-sampling sparse point clouds, outperforming existing generative models in these tasks.
Injecting Imbalance Sensitivity for Multi-Task Learning
Mar 11, 2025Multi-task learning (MTL) has emerged as a promising approach for deploying deep learning models in real-life applications. Recent studies have proposed optimization-based learning paradigms to establish task-shared representations in MTL. However, our paper empirically argues that these studies, specifically gradient-based ones, primarily emphasize the conflict issue while neglecting the potentially more significant impact of imbalance/dominance in MTL. In line with this perspective, we enhance the existing baseline method by injecting imbalance-sensitivity through the imposition of constraints on the projected norms. To demonstrate the effectiveness of our proposed IMbalance-sensitive Gradient (IMGrad) descent method, we evaluate it on multiple mainstream MTL benchmarks, encompassing supervised learning tasks as well as reinforcement learning. The experimental results consistently demonstrate competitive performance.