 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGT-SVQ: A Linear-Time Graph Transformer for Node Classification Using Spiking Vector Quantization
Apr 16, 2025Graph Transformers (GTs), which simultaneously integrate message-passing and self-attention mechanisms, have achieved promising empirical results in some graph prediction tasks. Although these approaches show the potential of Transformers in capturing long-range graph topology information, issues concerning the quadratic complexity and high computing energy consumption severely limit the scalability of GTs on large-scale graphs. Recently, as brain-inspired neural networks, Spiking Neural Networks (SNNs), facilitate the development of graph representation learning methods with lower computational and storage overhead through the unique event-driven spiking neurons. Inspired by these characteristics, we propose a linear-time Graph Transformer using Spiking Vector Quantization (GT-SVQ) for node classification. GT-SVQ reconstructs codebooks based on rate coding outputs from spiking neurons, and injects the codebooks into self-attention blocks to aggregate global information in linear complexity. Besides, spiking vector quantization effectively alleviates codebook collapse and the reliance on complex machinery (distance measure, auxiliary loss, etc.) present in previous vector quantization-based graph learning methods. In experiments, we compare GT-SVQ with other state-of-the-art baselines on node classification datasets ranging from small to large. Experimental results show that GT-SVQ has achieved competitive performances on most datasets while maintaining up to 130x faster inference speed compared to other GTs.
Are Large Language Models In-Context Graph Learners?
Feb 19, 2025
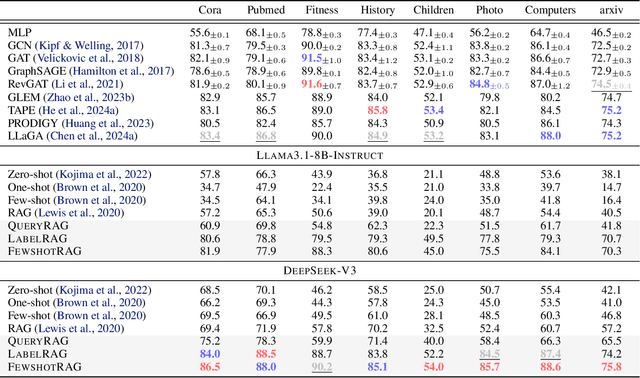


Large language models (LLMs) have demonstrated remarkable in-context reasoning capabilities across a wide range of tasks, particularly with unstructured inputs such as language or images. However, LLMs struggle to handle structured data, such as graphs, due to their lack of understanding of non-Euclidean structures. As a result, without additional fine-tuning, their performance significantly lags behind that of graph neural networks (GNNs) in graph learning tasks. In this paper, we show that learning on graph data can be conceptualized as a retrieval-augmented generation (RAG) process, where specific instances (e.g., nodes or edges) act as queries, and the graph itself serves as the retrieved context. Building on this insight, we propose a series of RAG frameworks to enhance the in-context learning capabilities of LLMs for graph learning tasks. Comprehensive evaluations demonstrate that our proposed RAG frameworks significantly improve LLM performance on graph-based tasks, particularly in scenarios where a pretrained LLM must be used without modification or accessed via an API.
Measuring Diversity in Synthetic Datasets
Feb 12, 2025Large language models (LLMs) are widely adopted to generate synthetic datasets for various natural language processing (NLP) tasks, such as text classification and summarization. However, accurately measuring the diversity of these synthetic datasets-an aspect crucial for robust model performance-remains a significant challenge. In this paper, we introduce DCScore, a novel method for measuring synthetic dataset diversity from a classification perspective. Specifically, DCScore formulates diversity evaluation as a sample classification task, leveraging mutual relationships among samples. We further provide theoretical verification of the diversity-related axioms satisfied by DCScore, highlighting its role as a principled diversity evaluation method. Experimental results on synthetic datasets reveal that DCScore enjoys a stronger correlation with multiple diversity pseudo-truths of evaluated datasets, underscoring its effectiveness. Moreover, both empirical and theoretical evidence demonstrate that DCScore substantially reduces computational costs compared to existing approaches. Code is available at: https://github.com/BlueWhaleLab/DCScore.
Revisiting and Benchmarking Graph Autoencoders: A Contrastive Learning Perspective
Oct 14, 2024



Graph autoencoders (GAEs) are self-supervised learning models that can learn meaningful representations of graph-structured data by reconstructing the input graph from a low-dimensional latent space. Over the past few years, GAEs have gained significant attention in academia and industry. In particular, the recent advent of GAEs with masked autoencoding schemes marks a significant advancement in graph self-supervised learning research. While numerous GAEs have been proposed, the underlying mechanisms of GAEs are not well understood, and a comprehensive benchmark for GAEs is still lacking. In this work, we bridge the gap between GAEs and contrastive learning by establishing conceptual and methodological connections. We revisit the GAEs studied in previous works and demonstrate how contrastive learning principles can be applied to GAEs. Motivated by these insights, we introduce lrGAE (left-right GAE), a general and powerful GAE framework that leverages contrastive learning principles to learn meaningful representations. Our proposed lrGAE not only facilitates a deeper understanding of GAEs but also sets a new benchmark for GAEs across diverse graph-based learning tasks. The source code for lrGAE, including the baselines and all the code for reproducing the results, is publicly available at https://github.com/EdisonLeeeee/lrGAE.
SGHormer: An Energy-Saving Graph Transformer Driven by Spikes
Mar 26, 2024


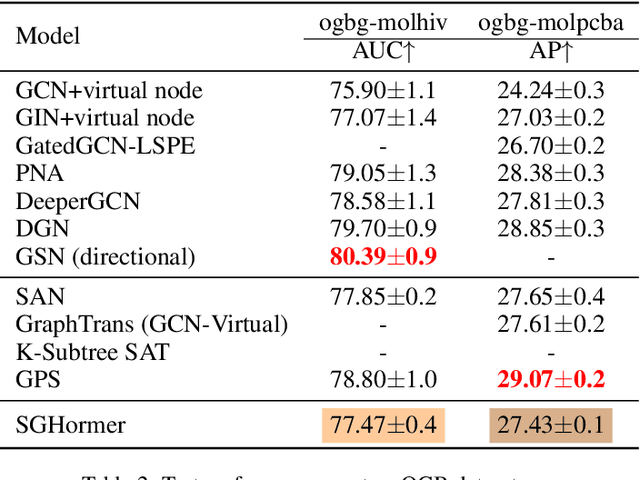
Graph Transformers (GTs) with powerful representation learning ability make a huge success in wide range of graph tasks. However, the costs behind outstanding performances of GTs are higher energy consumption and computational overhead. The complex structure and quadratic complexity during attention calculation in vanilla transformer seriously hinder its scalability on the large-scale graph data. Though existing methods have made strides in simplifying combinations among blocks or attention-learning paradigm to improve GTs' efficiency, a series of energy-saving solutions originated from biologically plausible structures are rarely taken into consideration when constructing GT framework. To this end, we propose a new spiking-based graph transformer (SGHormer). It turns full-precision embeddings into sparse and binarized spikes to reduce memory and computational costs. The spiking graph self-attention and spiking rectify blocks in SGHormer explicitly capture global structure information and recover the expressive power of spiking embeddings, respectively. In experiments, SGHormer achieves comparable performances to other full-precision GTs with extremely low computational energy consumption. The results show that SGHomer makes a remarkable progress in the field of low-energy GTs.
A Graph is Worth 1-bit Spikes: When Graph Contrastive Learning Meets Spiking Neural Networks
May 30, 2023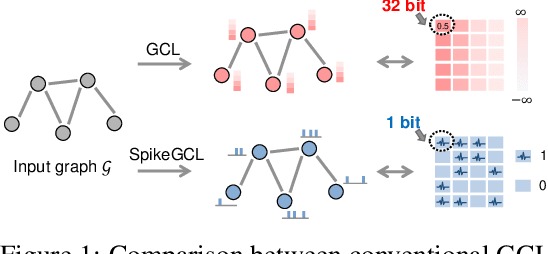

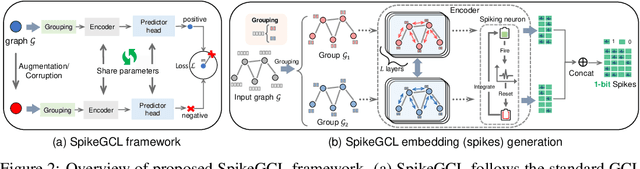
While contrastive self-supervised learning has become the de-facto learning paradigm for graph neural networks, the pursuit of high task accuracy requires a large hidden dimensionality to learn informative and discriminative full-precision representations, raising concerns about computation, memory footprint, and energy consumption burden (largely overlooked) for real-world applications. This paper explores a promising direction for graph contrastive learning (GCL) with spiking neural networks (SNNs), which leverage sparse and binary characteristics to learn more biologically plausible and compact representations. We propose SpikeGCL, a novel GCL framework to learn binarized 1-bit representations for graphs, making balanced trade-offs between efficiency and performance. We provide theoretical guarantees to demonstrate that SpikeGCL has comparable expressiveness with its full-precision counterparts. Experimental results demonstrate that, with nearly 32x representation storage compression, SpikeGCL is either comparable to or outperforms many fancy state-of-the-art supervised and self-supervised methods across several graph benchmarks.