 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere Do the Joules Go? Diagnosing Inference Energy Consumption
Jan 29, 2026Energy is now a critical ML computing resource. While measuring energy consumption and observing trends is a valuable first step, accurately understanding and diagnosing why those differences occur is crucial for optimization. To that end, we begin by presenting a large-scale measurement study of inference time and energy across the generative AI landscape with 46 models, 7 tasks, and 1,858 different configurations on NVIDIA H100 and B200 GPUs. Our empirical findings span order-of-magnitude variations: LLM task type can lead to 25$\times$ energy differences, video generation sometimes consumes more than 100$\times$ the energy of images, and GPU utilization differences can result in 3--5$\times$ energy differences. Based on our observations, we present a framework for reasoning about the underlying mechanisms that govern time and energy consumption. The essence is that time and energy are determined by latent metrics like memory and utilization, which are in turn affected by various factors across the algorithm, software, and hardware layers. Our framework also extends directly to throughput per watt, a critical metric for power-constrained datacenters.
Kareus: Joint Reduction of Dynamic and Static Energy in Large Model Training
Jan 25, 2026The computing demand of AI is growing at an unprecedented rate, but energy supply is not keeping pace. As a result, energy has become an expensive, contended resource that requires explicit management and optimization. Although recent works have made significant progress in large model training optimization, they focus only on a single aspect of energy consumption: dynamic or static energy. We find that fine-grained kernel scheduling and frequency scaling jointly and interdependently impact both dynamic and static energy consumption. Based on this finding, we design Kareus, a training system that pushes the time--energy tradeoff frontier by optimizing both aspects. Kareus decomposes the intractable joint optimization problem into local, partition-based subproblems. It then uses a multi-pass multi-objective optimization algorithm to find execution schedules that push the time--energy tradeoff frontier. Compared to the state of the art, Kareus reduces training energy by up to 28.3% at the same training time, or reduces training time by up to 27.5% at the same energy consumption.
TetriServe: Efficient DiT Serving for Heterogeneous Image Generation
Oct 02, 2025Diffusion Transformer (DiT) models excel at generating highquality images through iterative denoising steps, but serving them under strict Service Level Objectives (SLOs) is challenging due to their high computational cost, particularly at large resolutions. Existing serving systems use fixed degree sequence parallelism, which is inefficient for heterogeneous workloads with mixed resolutions and deadlines, leading to poor GPU utilization and low SLO attainment. In this paper, we propose step-level sequence parallelism to dynamically adjust the parallel degree of individual requests according to their deadlines. We present TetriServe, a DiT serving system that implements this strategy for highly efficient image generation. Specifically, TetriServe introduces a novel round-based scheduling mechanism that improves SLO attainment: (1) discretizing time into fixed rounds to make deadline-aware scheduling tractable, (2) adapting parallelism at the step level and minimize GPU hour consumption, and (3) jointly packing requests to minimize late completions. Extensive evaluation on state-of-the-art DiT models shows that TetriServe achieves up to 32% higher SLO attainment compared to existing solutions without degrading image quality.
Proto-EVFL: Enhanced Vertical Federated Learning via Dual Prototype with Extremely Unaligned Data
Jul 30, 2025In vertical federated learning (VFL), multiple enterprises address aligned sample scarcity by leveraging massive locally unaligned samples to facilitate collaborative learning. However, unaligned samples across different parties in VFL can be extremely class-imbalanced, leading to insufficient feature representation and limited model prediction space. Specifically, class-imbalanced problems consist of intra-party class imbalance and inter-party class imbalance, which can further cause local model bias and feature contribution inconsistency issues, respectively. To address the above challenges, we propose Proto-EVFL, an enhanced VFL framework via dual prototypes. We first introduce class prototypes for each party to learn relationships between classes in the latent space, allowing the active party to predict unseen classes. We further design a probabilistic dual prototype learning scheme to dynamically select unaligned samples by conditional optimal transport cost with class prior probability. Moreover, a mixed prior guided module guides this selection process by combining local and global class prior probabilities. Finally, we adopt an \textit{adaptive gated feature aggregation strategy} to mitigate feature contribution inconsistency by dynamically weighting and aggregating local features across different parties. We proved that Proto-EVFL, as the first bi-level optimization framework in VFL, has a convergence rate of 1/\sqrt T. Extensive experiments on various datasets validate the superiority of our Proto-EVFL. Even in a zero-shot scenario with one unseen class, it outperforms baselines by at least 6.97%
Transformers as Unsupervised Learning Algorithms: A study on Gaussian Mixtures
May 17, 2025The transformer architecture has demonstrated remarkable capabilities in modern artificial intelligence, among which the capability of implicitly learning an internal model during inference time is widely believed to play a key role in the under standing of pre-trained large language models. However, most recent works have been focusing on studying supervised learning topics such as in-context learning, leaving the field of unsupervised learning largely unexplored. This paper investigates the capabilities of transformers in solving Gaussian Mixture Models (GMMs), a fundamental unsupervised learning problem through the lens of statistical estimation. We propose a transformer-based learning framework called TGMM that simultaneously learns to solve multiple GMM tasks using a shared transformer backbone. The learned models are empirically demonstrated to effectively mitigate the limitations of classical methods such as Expectation-Maximization (EM) or spectral algorithms, at the same time exhibit reasonable robustness to distribution shifts. Theoretically, we prove that transformers can approximate both the EM algorithm and a core component of spectral methods (cubic tensor power iterations). These results bridge the gap between practical success and theoretical understanding, positioning transformers as versatile tools for unsupervised learning.
The ML.ENERGY Benchmark: Toward Automated Inference Energy Measurement and Optimization
May 09, 2025As the adoption of Generative AI in real-world services grow explosively, energy has emerged as a critical bottleneck resource. However, energy remains a metric that is often overlooked, under-explored, or poorly understood in the context of building ML systems. We present the ML.ENERGY Benchmark, a benchmark suite and tool for measuring inference energy consumption under realistic service environments, and the corresponding ML.ENERGY Leaderboard, which have served as a valuable resource for those hoping to understand and optimize the energy consumption of their generative AI services. In this paper, we explain four key design principles for benchmarking ML energy we have acquired over time, and then describe how they are implemented in the ML.ENERGY Benchmark. We then highlight results from the latest iteration of the benchmark, including energy measurements of 40 widely used model architectures across 6 different tasks, case studies of how ML design choices impact energy consumption, and how automated optimization recommendations can lead to significant (sometimes more than 40%) energy savings without changing what is being computed by the model. The ML.ENERGY Benchmark is open-source and can be easily extended to various customized models and application scenarios.
Are Large Language Models In-Context Graph Learners?
Feb 19, 2025
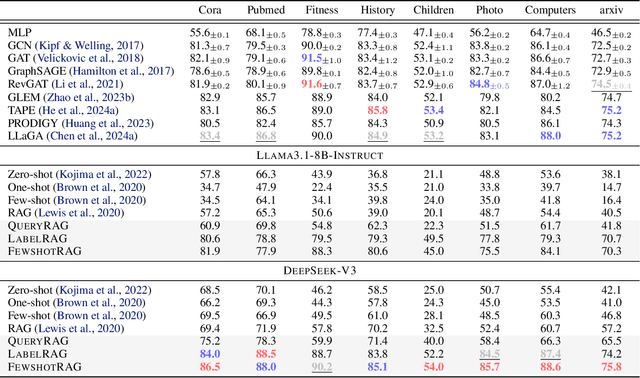


Large language models (LLMs) have demonstrated remarkable in-context reasoning capabilities across a wide range of tasks, particularly with unstructured inputs such as language or images. However, LLMs struggle to handle structured data, such as graphs, due to their lack of understanding of non-Euclidean structures. As a result, without additional fine-tuning, their performance significantly lags behind that of graph neural networks (GNNs) in graph learning tasks. In this paper, we show that learning on graph data can be conceptualized as a retrieval-augmented generation (RAG) process, where specific instances (e.g., nodes or edges) act as queries, and the graph itself serves as the retrieved context. Building on this insight, we propose a series of RAG frameworks to enhance the in-context learning capabilities of LLMs for graph learning tasks. Comprehensive evaluations demonstrate that our proposed RAG frameworks significantly improve LLM performance on graph-based tasks, particularly in scenarios where a pretrained LLM must be used without modification or accessed via an API.
Revisiting and Benchmarking Graph Autoencoders: A Contrastive Learning Perspective
Oct 14, 2024



Graph autoencoders (GAEs) are self-supervised learning models that can learn meaningful representations of graph-structured data by reconstructing the input graph from a low-dimensional latent space. Over the past few years, GAEs have gained significant attention in academia and industry. In particular, the recent advent of GAEs with masked autoencoding schemes marks a significant advancement in graph self-supervised learning research. While numerous GAEs have been proposed, the underlying mechanisms of GAEs are not well understood, and a comprehensive benchmark for GAEs is still lacking. In this work, we bridge the gap between GAEs and contrastive learning by establishing conceptual and methodological connections. We revisit the GAEs studied in previous works and demonstrate how contrastive learning principles can be applied to GAEs. Motivated by these insights, we introduce lrGAE (left-right GAE), a general and powerful GAE framework that leverages contrastive learning principles to learn meaningful representations. Our proposed lrGAE not only facilitates a deeper understanding of GAEs but also sets a new benchmark for GAEs across diverse graph-based learning tasks. The source code for lrGAE, including the baselines and all the code for reproducing the results, is publicly available at https://github.com/EdisonLeeeee/lrGAE.
Ultra-imbalanced classification guided by statistical information
Sep 06, 2024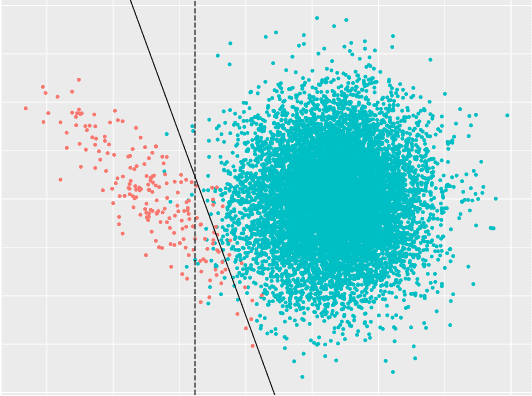
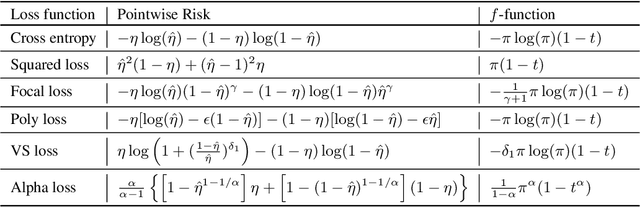
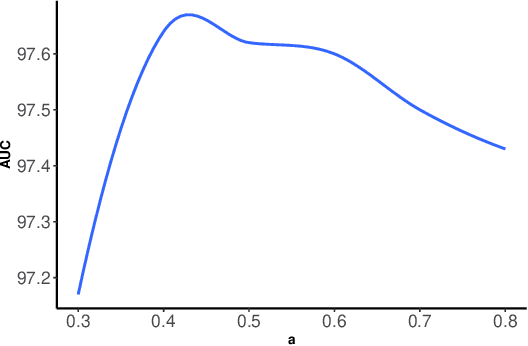
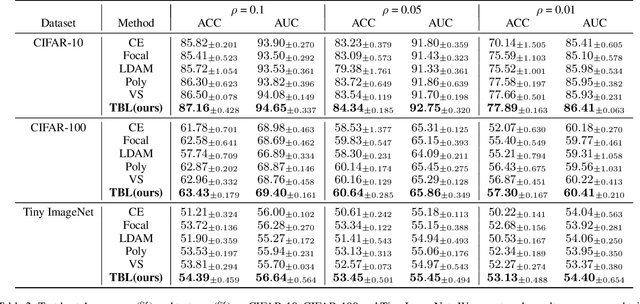
Imbalanced data are frequently encountered in real-world classification tasks. Previous works on imbalanced learning mostly focused on learning with a minority class of few samples. However, the notion of imbalance also applies to cases where the minority class contains abundant samples, which is usually the case for industrial applications like fraud detection in the area of financial risk management. In this paper, we take a population-level approach to imbalanced learning by proposing a new formulation called \emph{ultra-imbalanced classification} (UIC). Under UIC, loss functions behave differently even if infinite amount of training samples are available. To understand the intrinsic difficulty of UIC problems, we borrow ideas from information theory and establish a framework to compare different loss functions through the lens of statistical information. A novel learning objective termed Tunable Boosting Loss is developed which is provably resistant against data imbalance under UIC, as well as being empirically efficient verified by extensive experimental studies on both public and industrial datasets.
Revisiting Modularity Maximization for Graph Clustering: A Contrastive Learning Perspective
Jun 20, 2024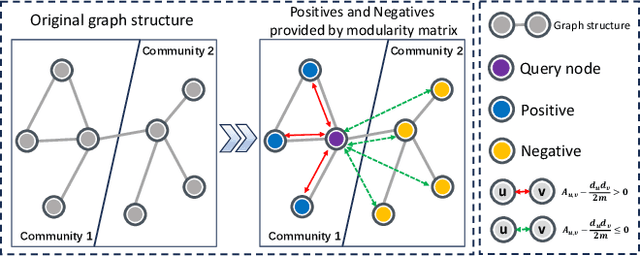
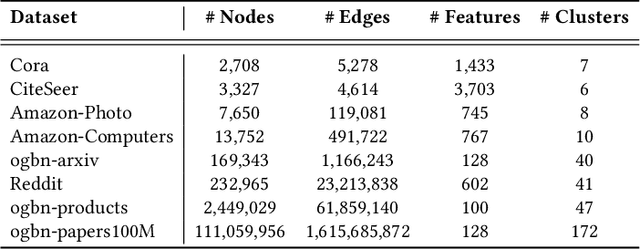
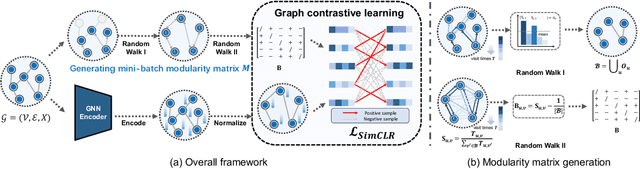
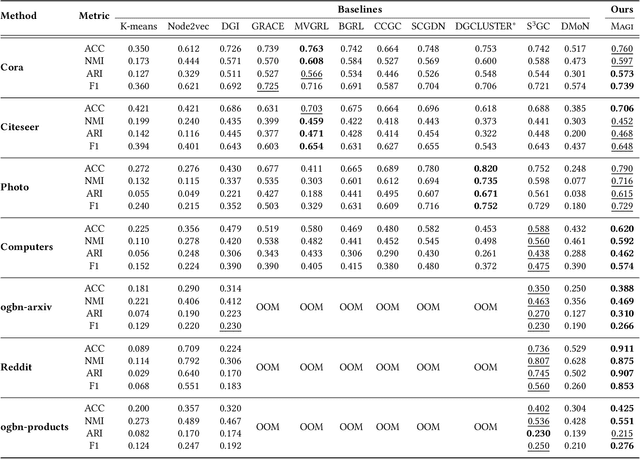
Graph clustering, a fundamental and challenging task in graph mining, aims to classify nodes in a graph into several disjoint clusters. In recent years, graph contrastive learning (GCL) has emerged as a dominant line of research in graph clustering and advances the new state-of-the-art. However, GCL-based methods heavily rely on graph augmentations and contrastive schemes, which may potentially introduce challenges such as semantic drift and scalability issues. Another promising line of research involves the adoption of modularity maximization, a popular and effective measure for community detection, as the guiding principle for clustering tasks. Despite the recent progress, the underlying mechanism of modularity maximization is still not well understood. In this work, we dig into the hidden success of modularity maximization for graph clustering. Our analysis reveals the strong connections between modularity maximization and graph contrastive learning, where positive and negative examples are naturally defined by modularity. In light of our results, we propose a community-aware graph clustering framework, coined MAGI, which leverages modularity maximization as a contrastive pretext task to effectively uncover the underlying information of communities in graphs, while avoiding the problem of semantic drift. Extensive experiments on multiple graph datasets verify the effectiveness of MAGI in terms of scalability and clustering performance compared to state-of-the-art graph clustering methods. Notably, MAGI easily scales a sufficiently large graph with 100M nodes while outperforming strong baselines.