 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Estimation Errors by Twin TD-Regularized Actor and Critic for Deep Reinforcement Learning
Paper and Code
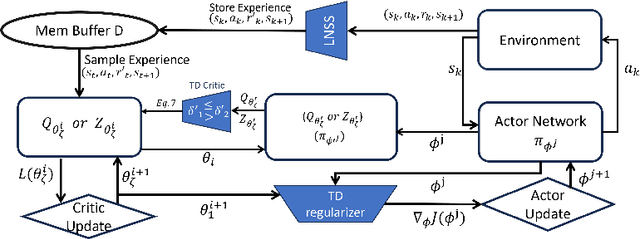

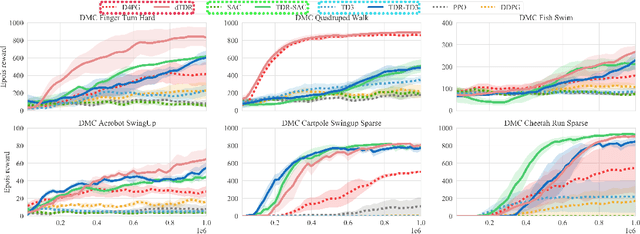
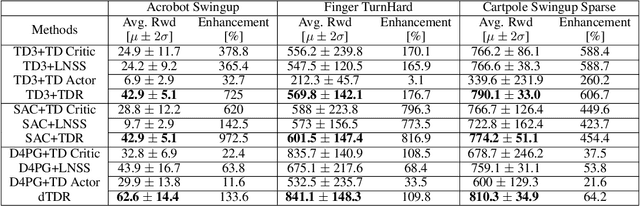
We address the issue of estimation bias in deep reinforcement learning (DRL) by introducing solution mechanisms that include a new, twin TD-regularized actor-critic (TDR) method. It aims at reducing both over and under-estimation errors. With TDR and by combining good DRL improvements, such as distributional learning and long N-step surrogate stage reward (LNSS) method, we show that our new TDR-based actor-critic learning has enabled DRL methods to outperform their respective baselines in challenging environments in DeepMind Control Suite. Furthermore, they elevate TD3 and SAC respectively to a level of performance comparable to that of D4PG (the current SOTA), and they also improve the performance of D4PG to a new SOTA level measured by mean reward, convergence speed, learning success rate, and learning variance.