 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Motion Imitation: Is Human Motion Data Alone Sufficient to Explain Gait Control and Biomechanics?
Mar 12, 2026With the growing interest in motion imitation learning (IL) for human biomechanics and wearable robotics, this study investigates how additional foot-ground interaction measures, used as reward terms, affect human gait kinematics and kinetics estimation within a reinforcement learning-based IL framework. Results indicate that accurate reproduction of forward kinematics alone does not ensure biomechanically plausible joint kinetics. Adding foot-ground contacts and contact forces to the IL reward terms enables the prediction of joint moments in forward walking simulation, which are significantly closer to those computed by inverse dynamics. This finding highlights a fundamental limitation of motion-only IL approaches, which may prioritize kinematics matching over physical consistency. Incorporating kinetic constraints, particularly ground reaction force and center of pressure information, significantly enhances the realism of internal and external kinetics. These findings suggest that, when imitation learning is applied to human-related research domains such as biomechanics and wearable robot co-design, kinetics-based reward shaping is necessary to achieve physically consistent gait representations.
Fast, accurate measurement of the worker populations of honey bee colonies using deep learning
Dec 11, 2025Honey bees play a crucial role in pollination, contributing significantly to global agriculture and ecosystems. Accurately estimating hive populations is essential for understanding the effects of environmental factors on bee colonies, yet traditional methods of counting bees are time-consuming, labor-intensive, and prone to human error, particularly in large-scale studies. In this paper, we present a deep learning-based solution for automating bee population counting using CSRNet and introduce ASUBEE, the FIRST high-resolution dataset specifically designed for this task. Our method employs density map estimation to predict bee populations, effectively addressing challenges such as occlusion and overlapping bees that are common in hive monitoring. We demonstrate that CSRNet achieves superior performance in terms of time efficiency, with a computation time of just 1 second per image, while delivering accurate counts even in complex and densely populated hive scenarios. Our findings show that deep learning approaches like CSRNet can dramatically enhance the efficiency of hive population assessments, providing a valuable tool for researchers and beekeepers alike. This work marks a significant advancement in applying AI technologies to ecological research, offering scalable and precise monitoring solutions for honey bee populations.
Mitigating Estimation Errors by Twin TD-Regularized Actor and Critic for Deep Reinforcement Learning
Nov 07, 2023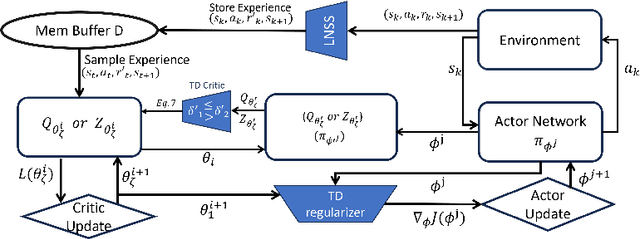

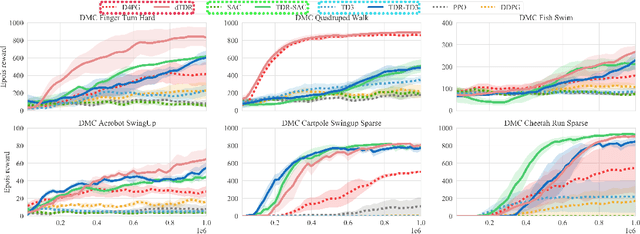
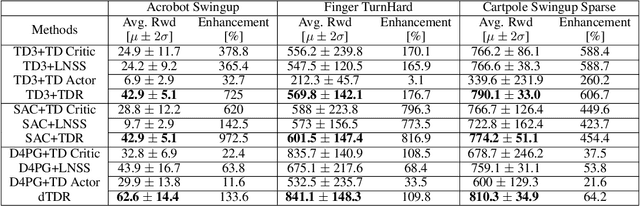
We address the issue of estimation bias in deep reinforcement learning (DRL) by introducing solution mechanisms that include a new, twin TD-regularized actor-critic (TDR) method. It aims at reducing both over and under-estimation errors. With TDR and by combining good DRL improvements, such as distributional learning and long N-step surrogate stage reward (LNSS) method, we show that our new TDR-based actor-critic learning has enabled DRL methods to outperform their respective baselines in challenging environments in DeepMind Control Suite. Furthermore, they elevate TD3 and SAC respectively to a level of performance comparable to that of D4PG (the current SOTA), and they also improve the performance of D4PG to a new SOTA level measured by mean reward, convergence speed, learning success rate, and learning variance.
Continuous-Time Reinforcement Learning: New Design Algorithms with Theoretical Insights and Performance Guarantees
Jul 18, 2023Continuous-time nonlinear optimal control problems hold great promise in real-world applications. After decades of development, reinforcement learning (RL) has achieved some of the greatest successes as a general nonlinear control design method. However, a recent comprehensive analysis of state-of-the-art continuous-time RL (CT-RL) methods, namely, adaptive dynamic programming (ADP)-based CT-RL algorithms, reveals they face significant design challenges due to their complexity, numerical conditioning, and dimensional scaling issues. Despite advanced theoretical results, existing ADP CT-RL synthesis methods are inadequate in solving even small, academic problems. The goal of this work is thus to introduce a suite of new CT-RL algorithms for control of affine nonlinear systems. Our design approach relies on two important factors. First, our methods are applicable to physical systems that can be partitioned into smaller subproblems. This constructive consideration results in reduced dimensionality and greatly improved intuitiveness of design. Second, we introduce a new excitation framework to improve persistence of excitation (PE) and numerical conditioning performance via classical input/output insights. Such a design-centric approach is the first of its kind in the ADP CT-RL community. In this paper, we progressively introduce a suite of (decentralized) excitable integral reinforcement learning (EIRL) algorithms. We provide convergence and closed-loop stability guarantees, and we demonstrate these guarantees on a significant application problem of controlling an unstable, nonminimum phase hypersonic vehicle (HSV).
Long N-step Surrogate Stage Reward to Reduce Variances of Deep Reinforcement Learning in Complex Problems
Oct 10, 2022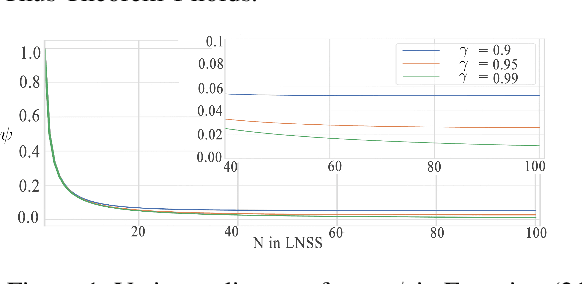
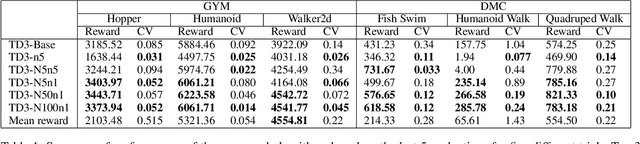
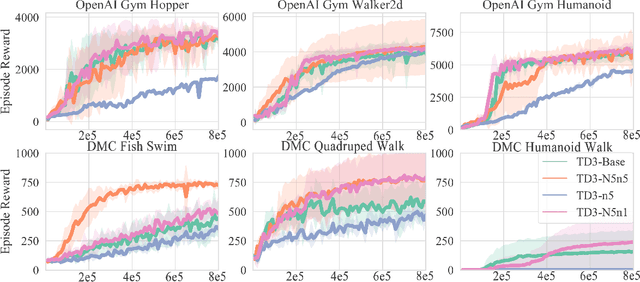

High variances in reinforcement learning have shown impeding successful convergence and hurting task performance. As reward signal plays an important role in learning behavior, multi-step methods have been considered to mitigate the problem, and are believed to be more effective than single step methods. However, there is a lack of comprehensive and systematic study on this important aspect to demonstrate the effectiveness of multi-step methods in solving highly complex continuous control problems. In this study, we introduce a new long $N$-step surrogate stage (LNSS) reward approach to effectively account for complex environment dynamics while previous methods are usually feasible for limited number of steps. The LNSS method is simple, low computational cost, and applicable to value based or policy gradient reinforcement learning. We systematically evaluate LNSS in OpenAI Gym and DeepMind Control Suite to address some complex benchmark environments that have been challenging to obtain good results by DRL in general. We demonstrate performance improvement in terms of total reward, convergence speed, and coefficient of variation (CV) by LNSS. We also provide analytical insights on how LNSS exponentially reduces the upper bound on the variances of Q value from a respective single step method
Robotic Knee Tracking Control to Mimic the Intact Human Knee Profile Based on Actor-critic Reinforcement Learning
Jan 22, 2021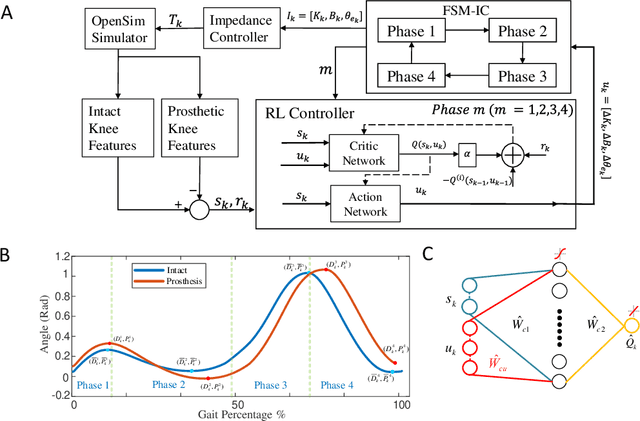
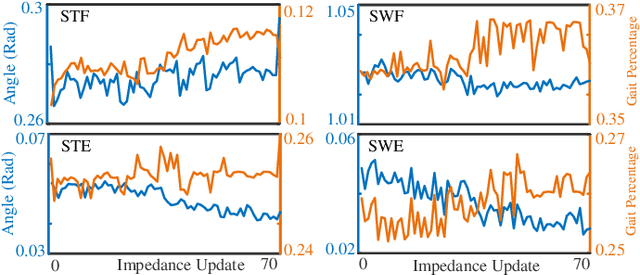
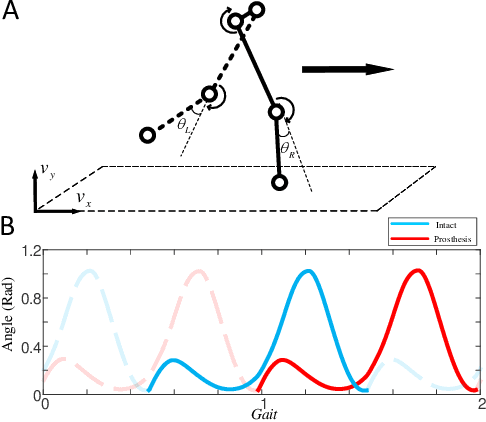
We address a state-of-the-art reinforcement learning (RL) control approach to automatically configure robotic prosthesis impedance parameters to enable end-to-end, continuous locomotion intended for transfemoral amputee subjects. Specifically, our actor-critic based RL provides tracking control of a robotic knee prosthesis to mimic the intact knee profile. This is a significant advance from our previous RL based automatic tuning of prosthesis control parameters which have centered on regulation control with a designer prescribed robotic knee profile as the target. In addition to presenting the complete tracking control algorithm based on direct heuristic dynamic programming (dHDP), we provide an analytical framework for the tracking controller with constrained inputs. We show that our proposed tracking control possesses several important properties, such as weight convergence of the learning networks, Bellman (sub)optimality of the cost-to-go value function and control input, and practical stability of the human-robot system under input constraint. We further provide a systematic simulation of the proposed tracking control using a realistic human-robot system simulator, the OpenSim, to emulate how the dHDP enables level ground walking, walking on different terrains and at different paces. These results show that our proposed dHDP based tracking control is not only theoretically suitable, but also practically useful.
Reinforcement Learning Enabled Automatic Impedance Control of a Robotic Knee Prosthesis to Mimic the Intact Knee Motion in a Co-Adapting Environment
Jan 10, 2021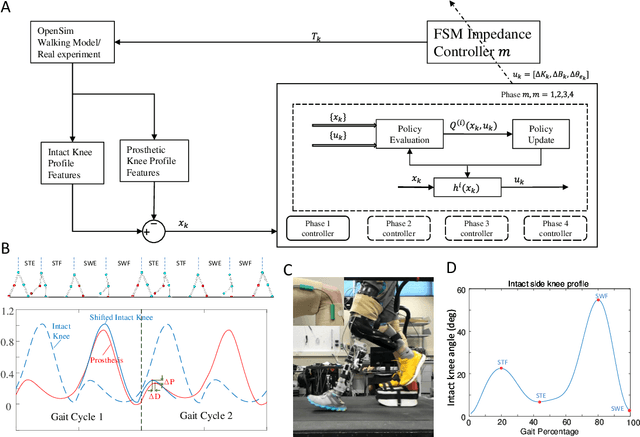
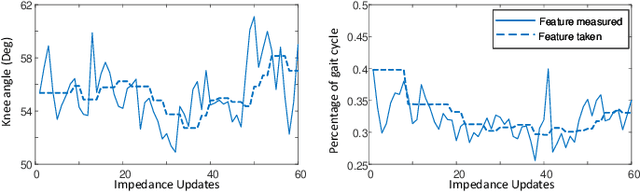
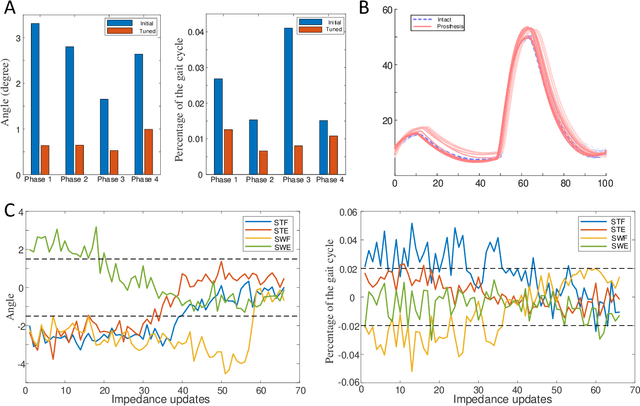
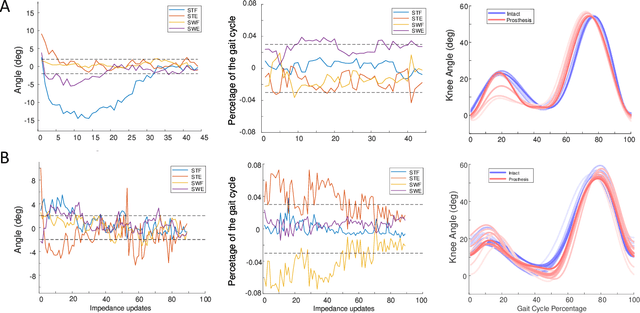
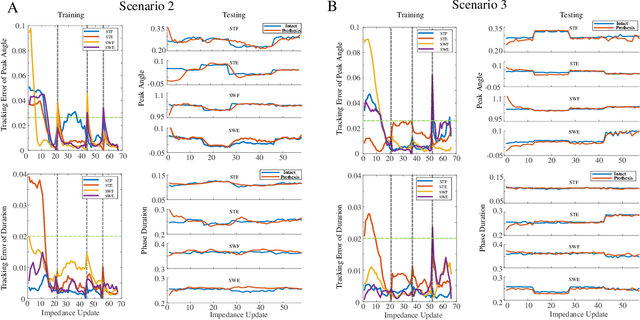
Automatically configuring a robotic prosthesis to fit its user's needs and physical conditions is a great technical challenge and a roadblock to the adoption of the technology. Previously, we have successfully developed reinforcement learning (RL) solutions toward addressing this issue. Yet, our designs were based on using a subjectively prescribed target motion profile for the robotic knee during level ground walking. This is not realistic for different users and for different locomotion tasks. In this study for the first time, we investigated the feasibility of RL enabled automatic configuration of impedance parameter settings for a robotic knee to mimic the intact knee motion in a co-adapting environment. We successfully achieved such tracking control by an online policy iteration. We demonstrated our results in both OpenSim simulations and two able-bodied (AB) subjects.
A Data-Driven Reinforcement Learning Solution Framework for Optimal and Adaptive Personalization of a Hip Exoskeleton
Nov 11, 2020
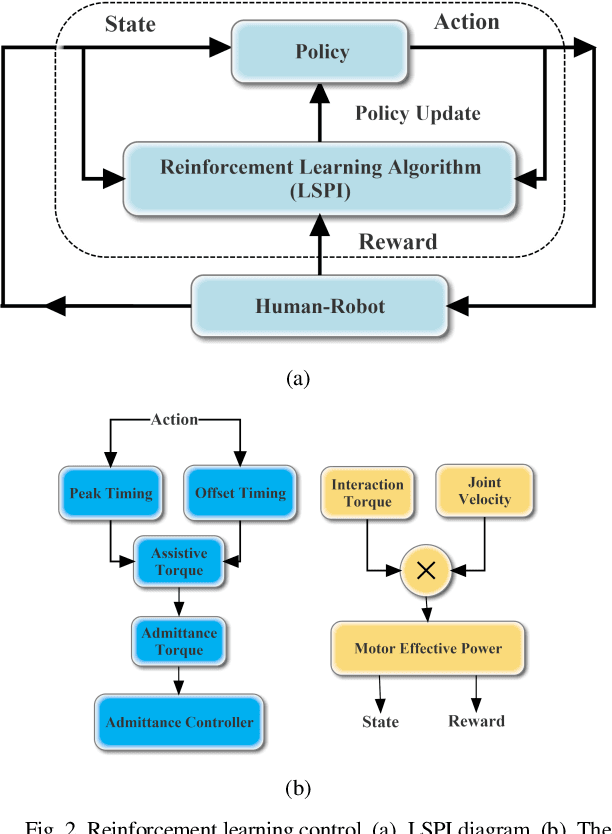
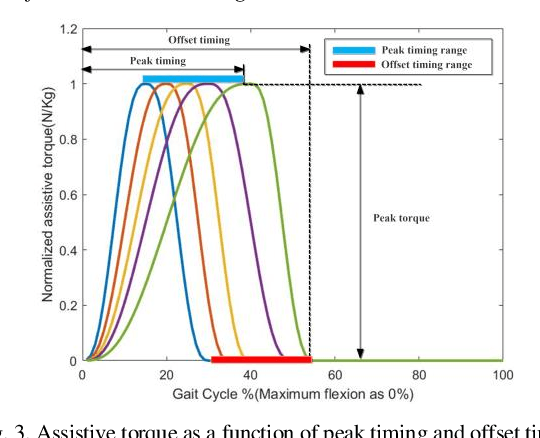
Robotic exoskeletons are exciting technologies for augmenting human mobility. However, designing such a device for seamless integration with the human user and to assist human movement still is a major challenge. This paper aims at developing a novel data-driven solution framework based on reinforcement learning (RL), without first modeling the human-robot dynamics, to provide optimal and adaptive personalized torque assistance for reducing human efforts during walking. Our automatic personalization solution framework includes the assistive torque profile with two control timing parameters (peak and offset timings), the least square policy iteration (LSPI) for learning the parameter tuning policy, and a cost function based on transferred work ratio. The proposed controller was successfully validated on a healthy human subject to assist unilateral hip extension in walking. The results showed that the optimal and adaptive RL controller as a new approach was feasible for tuning assistive torque profile of the hip exoskeleton that coordinated with human actions and reduced activation level of hip extensor muscle in human.
Reinforcement Learning Control of Robotic Knee with Human in the Loop by Flexible Policy Iteration
Jun 16, 2020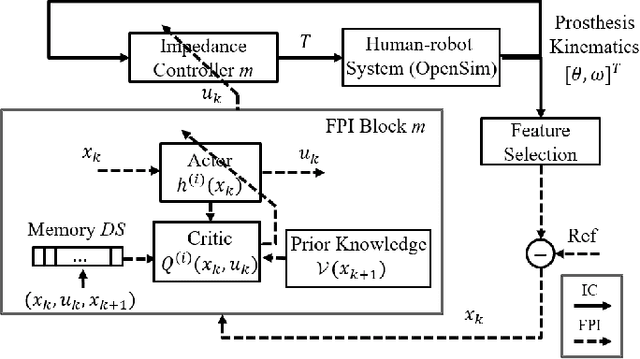
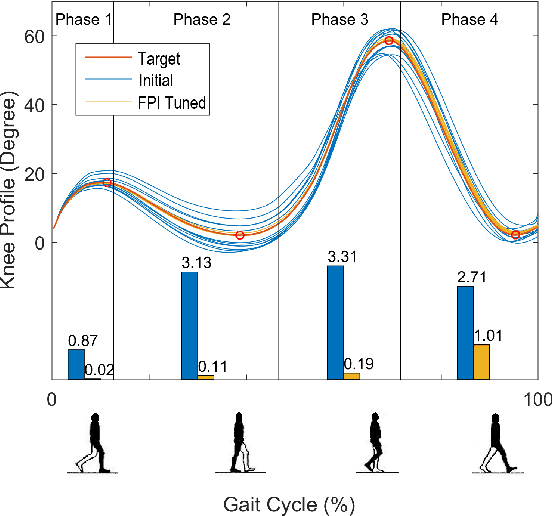
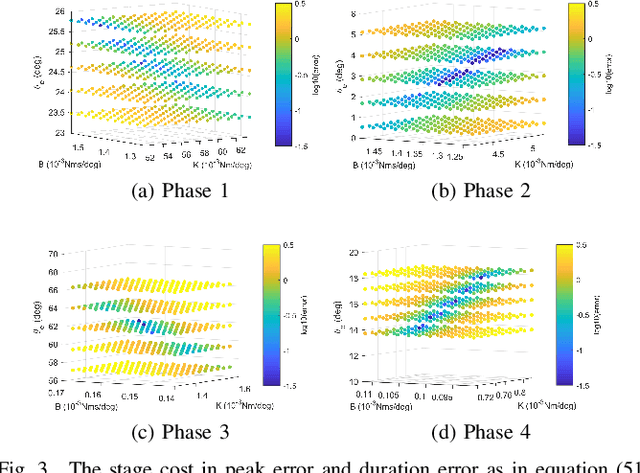
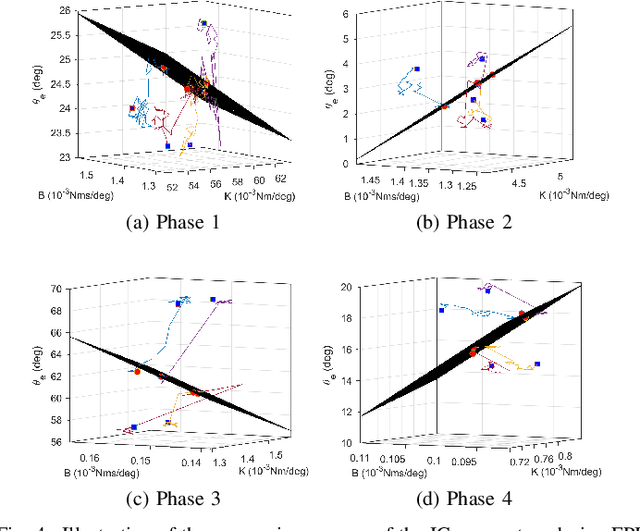
This study is motivated by a new class of challenging control problems described by automatic tuning of robotic knee control parameters with human in the loop. In addition to inter-person and intra-person variances inherent in such human-robot systems, human user safety and stability, as well as data and time efficiency should also be taken into design consideration. Here by data and time efficiency we mean learning and adaptation of device configurations takes place within countable gait cycles or within minutes of time. As solutions to this problem is not readily available, we therefore propose a new policy iteration based adaptive dynamic programming algorithm, namely the flexible policy iteration (FPI). We show that the FPI solves the control parameters via (weighted) least-squares while it incorporates data flexibly and utilizes prior knowledge. We provide analyses on stable control policies, non-increasing and converging value functions to Bellman optimality, and error bounds on the iterative value functions subject to approximation errors. We extensively evaluated the performance of FPI in a well-established locomotion simulator, the OpenSim under realistic conditions. By inspecting FPI with three other comparable algorithms, we demonstrate the FPI as a feasible data and time efficient design approach for adapting the control parameters of the prosthetic knee to co-adapt with the human user who also places control on the prosthesis. As the proposed FPI algorithm does not require stringent constraints or peculiar assumptions, we expect this reinforcement learning controller can potentially be applied to other challenging adaptive optimal control problems.
Online Reinforcement Learning Control by Direct Heuristic Dynamic Programming: from Time-Driven to Event-Driven
Jun 16, 2020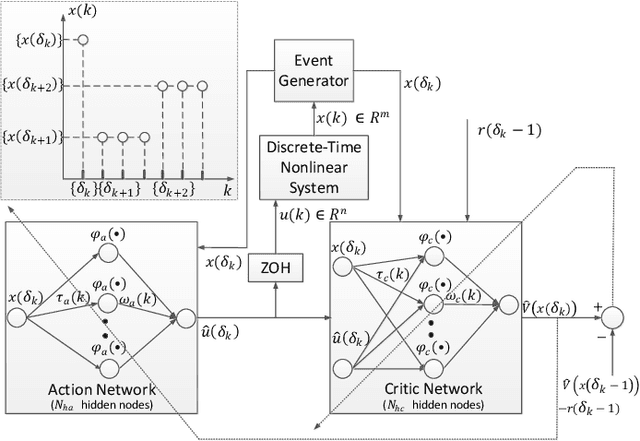
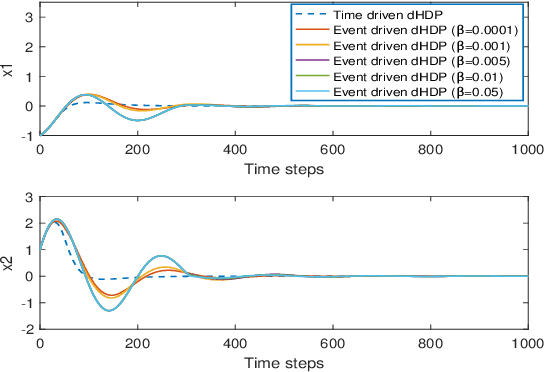
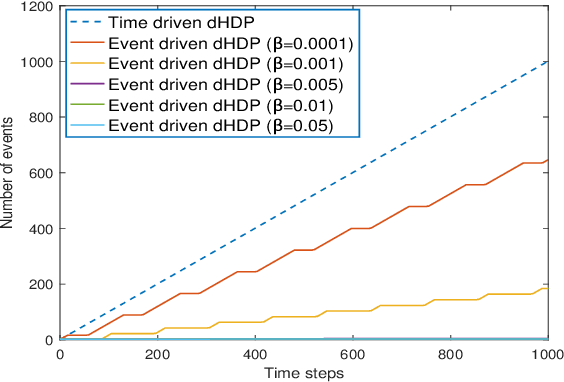
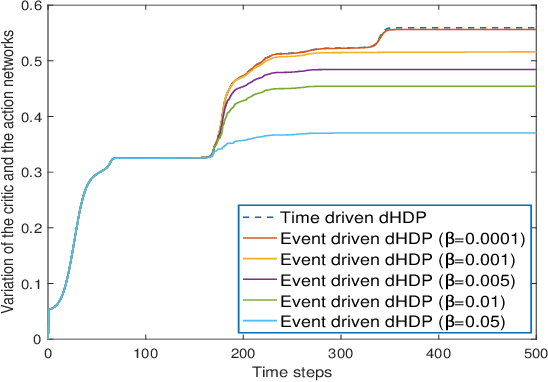
In this paper time-driven learning refers to the machine learning method that updates parameters in a prediction model continuously as new data arrives. Among existing approximate dynamic programming (ADP) and reinforcement learning (RL) algorithms, the direct heuristic dynamic programming (dHDP) has been shown an effective tool as demonstrated in solving several complex learning control problems. It continuously updates the control policy and the critic as system states continuously evolve. It is therefore desirable to prevent the time-driven dHDP from updating due to insignificant system event such as noise. Toward this goal, we propose a new event-driven dHDP. By constructing a Lyapunov function candidate, we prove the uniformly ultimately boundedness (UUB) of the system states and the weights in the critic and the control policy networks. Consequently we show the approximate control and cost-to-go function approaching Bellman optimality within a finite bound. We also illustrate how the event-driven dHDP algorithm works in comparison to the original time-driven dHDP.