 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadio-Based Passive Target Tracking by a Mobile Receiver with Unknown Transmitter Position
Nov 07, 2024



In this paper, we propose a radio-based passive target tracking algorithm using multipath measurements, including the angle of arrival and relative distance. We focus on a scenario in which a mobile receiver continuously receives radio signals from a transmitter located at an unknown position. The receiver utilizes multipath measurements extracted from the received signal to jointly localize the transmitter and the scatterers over time, with scatterers comprising a moving target and stationary objects that can reflect signals within the environment. We develop a comprehensive probabilistic model for the target tracking problem, incorporating the localization of the transmitter and scatterers, the identification of false alarms and missed detections in the measurements, and the association between scatterers and measurements. We employ a belief propagation approach to compute the posterior distributions of the positions of the scatterers and the transmitter. Additionally, we introduce a particle implementation for the belief propagation method. Simulation results demonstrate that our proposed algorithm outperforms existing benchmark methods in terms of target tracking accuracy.
Age of Information-Oriented Probabilistic Link Scheduling for Device-to-Device Networks
Oct 26, 2024



This paper focuses on optimizing the long-term average age of information (AoI) in device-to-device (D2D) networks through age-aware link scheduling. The problem is naturally formulated as a Markov decision process (MDP). However, finding the optimal policy for the formulated MDP in its original form is challenging due to the intertwined AoI dynamics of all D2D links. To address this, we propose an age-aware stationary randomized policy that determines the probability of scheduling each link in each time slot based on the AoI of all links and the statistical channel state information among all transceivers. By employing the Lyapunov optimization framework, our policy aims to minimize the Lyapunov drift in every time slot. Nonetheless, this per-slot minimization problem is nonconvex due to cross-link interference in D2D networks, posing significant challenges for real-time decision-making. After analyzing the permutation equivariance property of the optimal solutions to the per-slot problem, we apply a message passing neural network (MPNN), a type of graph neural network that also exhibits permutation equivariance, to optimize the per-slot problem in an unsupervised learning manner. Simulation results demonstrate the superior performance of the proposed age-aware stationary randomized policy over baselines and validate the scalability of our method.
Design of EMG-driven Musculoskeletal Model for Volitional Control of a Robotic Ankle Prosthesis
Feb 17, 2022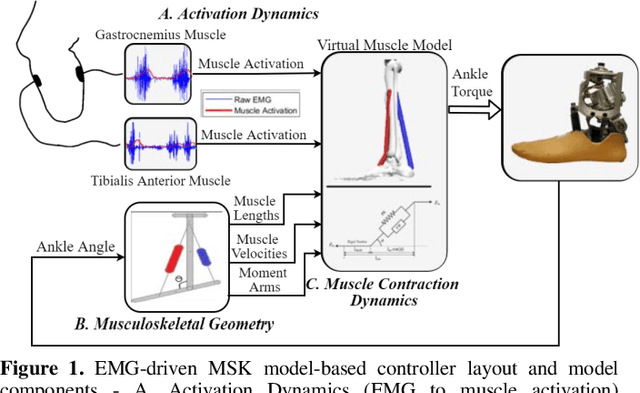
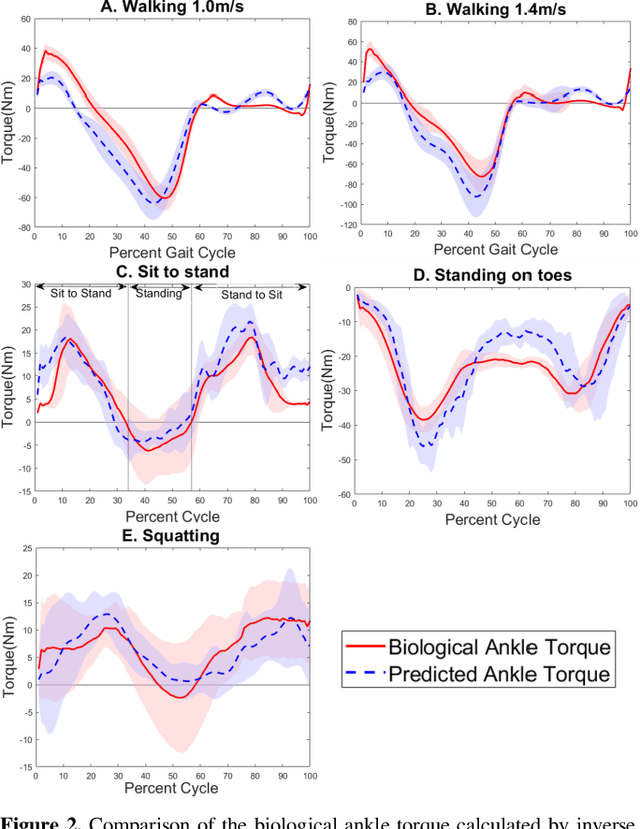
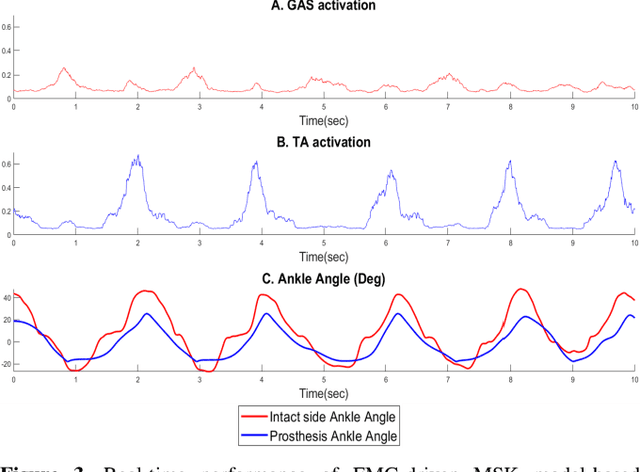
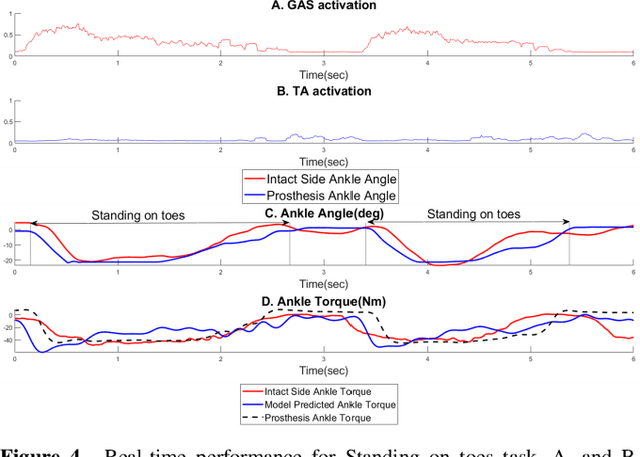
Existing robotic lower-limb prostheses use autonomous control to address cyclic, locomotive tasks, but they are inadequate to operate the prosthesis for daily activities that are non-cyclic and unpredictable. To address this challenge, this study aims to design a novel electromyography (EMG)-driven musculoskeletal model for volitional control of a robotic ankle-foot prosthesis. This controller places the user in continuous control of the device, allowing them to freely manipulate the prosthesis behavior at will. The Hill-type muscle model was used to model a dorsiflexor and a plantarflexor, which functioned around a virtual ankle joint. The model parameters were determined by fitting the model prediction to the experimental data collected from an able-bodied subject. EMG signals recorded from ankle agonist and antagonist muscle pair were used to activate the virtual muscle models. This model was validated via offline simulations and real-time prosthesis control. Additionally, the feasibility of the proposed prosthesis control on assisting the user's functional tasks was demonstrated. The present control may further improve the function of robotic prosthesis for supporting versatile activities in individuals with lower-limb amputations.
Robotic Knee Tracking Control to Mimic the Intact Human Knee Profile Based on Actor-critic Reinforcement Learning
Jan 22, 2021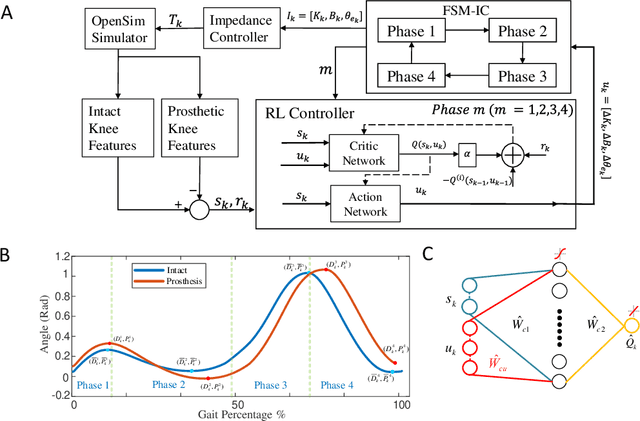
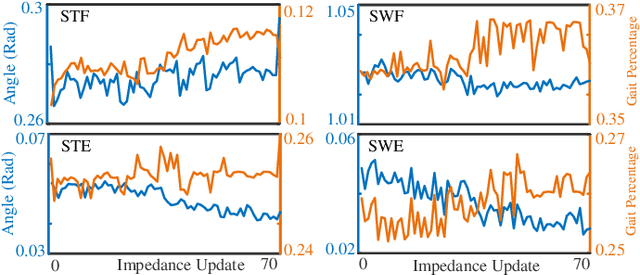
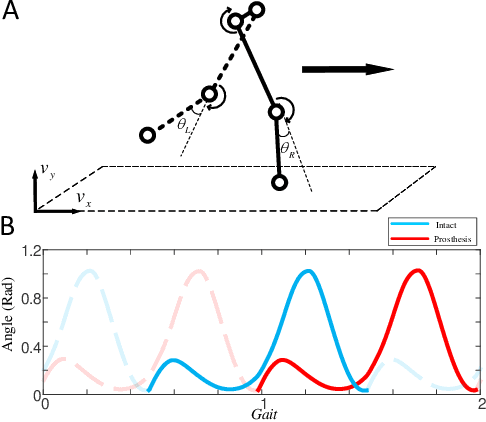
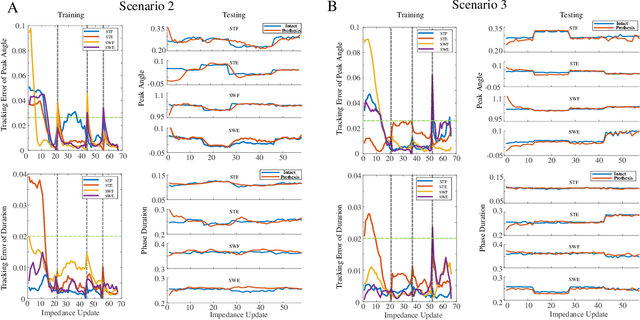
We address a state-of-the-art reinforcement learning (RL) control approach to automatically configure robotic prosthesis impedance parameters to enable end-to-end, continuous locomotion intended for transfemoral amputee subjects. Specifically, our actor-critic based RL provides tracking control of a robotic knee prosthesis to mimic the intact knee profile. This is a significant advance from our previous RL based automatic tuning of prosthesis control parameters which have centered on regulation control with a designer prescribed robotic knee profile as the target. In addition to presenting the complete tracking control algorithm based on direct heuristic dynamic programming (dHDP), we provide an analytical framework for the tracking controller with constrained inputs. We show that our proposed tracking control possesses several important properties, such as weight convergence of the learning networks, Bellman (sub)optimality of the cost-to-go value function and control input, and practical stability of the human-robot system under input constraint. We further provide a systematic simulation of the proposed tracking control using a realistic human-robot system simulator, the OpenSim, to emulate how the dHDP enables level ground walking, walking on different terrains and at different paces. These results show that our proposed dHDP based tracking control is not only theoretically suitable, but also practically useful.
Reinforcement Learning Enabled Automatic Impedance Control of a Robotic Knee Prosthesis to Mimic the Intact Knee Motion in a Co-Adapting Environment
Jan 10, 2021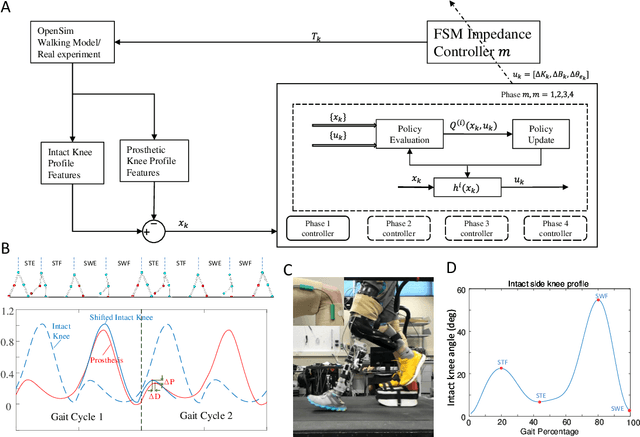
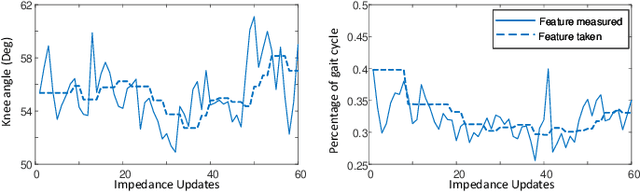
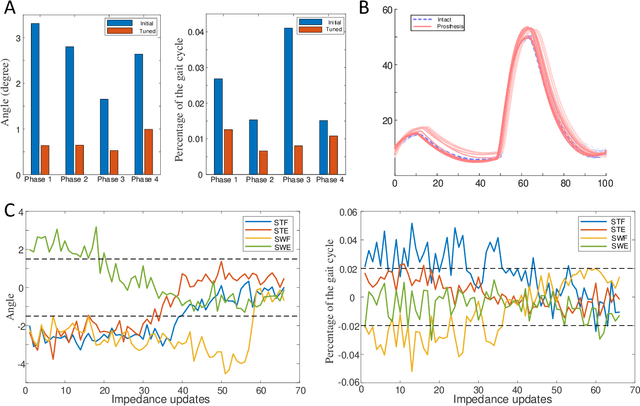
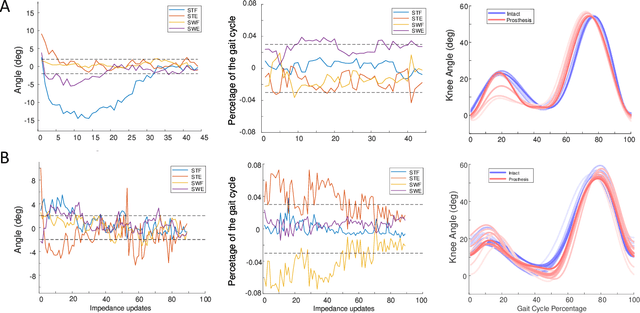
Automatically configuring a robotic prosthesis to fit its user's needs and physical conditions is a great technical challenge and a roadblock to the adoption of the technology. Previously, we have successfully developed reinforcement learning (RL) solutions toward addressing this issue. Yet, our designs were based on using a subjectively prescribed target motion profile for the robotic knee during level ground walking. This is not realistic for different users and for different locomotion tasks. In this study for the first time, we investigated the feasibility of RL enabled automatic configuration of impedance parameter settings for a robotic knee to mimic the intact knee motion in a co-adapting environment. We successfully achieved such tracking control by an online policy iteration. We demonstrated our results in both OpenSim simulations and two able-bodied (AB) subjects.
A Data-Driven Reinforcement Learning Solution Framework for Optimal and Adaptive Personalization of a Hip Exoskeleton
Nov 11, 2020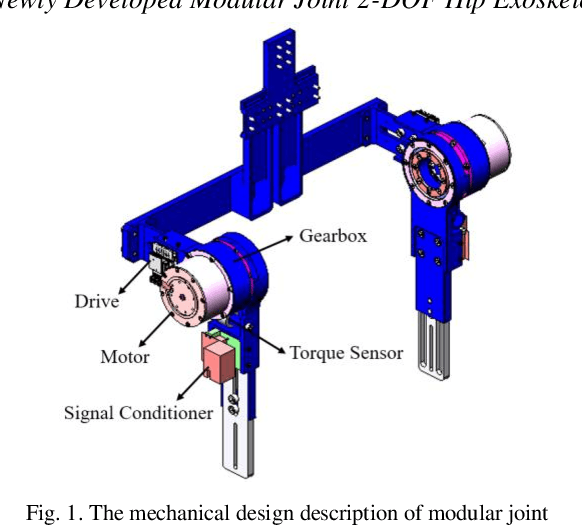
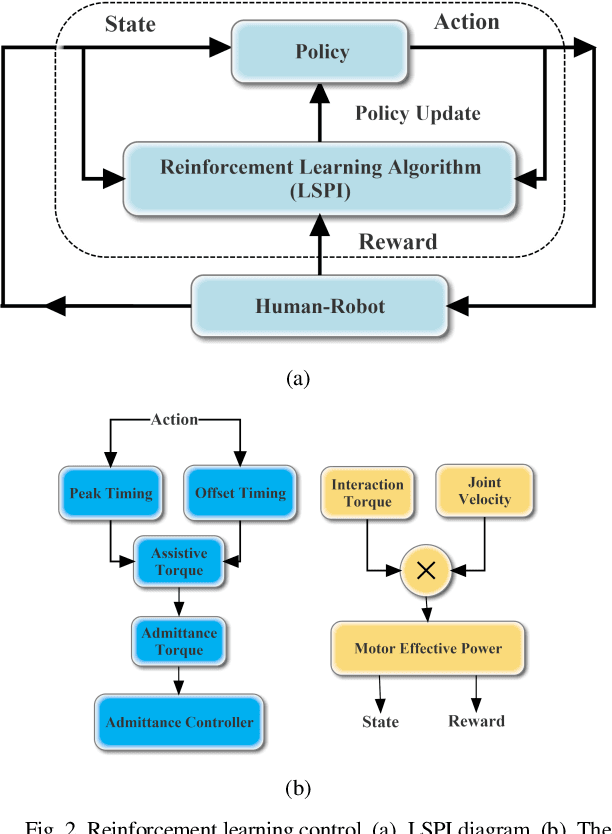
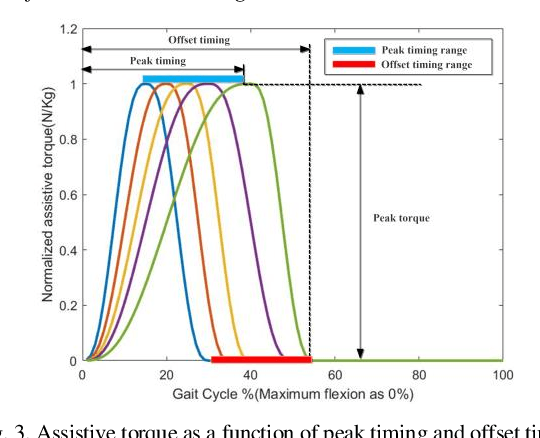
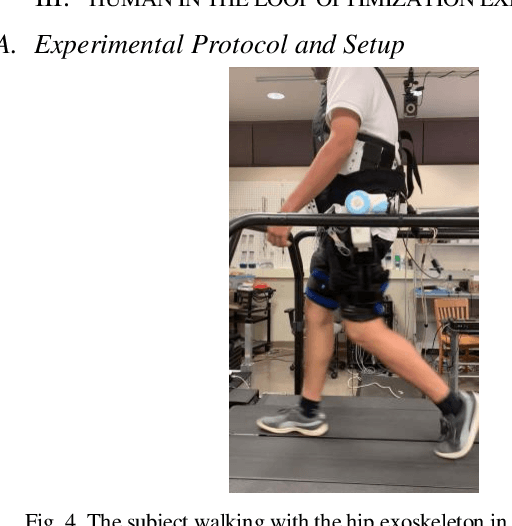
Robotic exoskeletons are exciting technologies for augmenting human mobility. However, designing such a device for seamless integration with the human user and to assist human movement still is a major challenge. This paper aims at developing a novel data-driven solution framework based on reinforcement learning (RL), without first modeling the human-robot dynamics, to provide optimal and adaptive personalized torque assistance for reducing human efforts during walking. Our automatic personalization solution framework includes the assistive torque profile with two control timing parameters (peak and offset timings), the least square policy iteration (LSPI) for learning the parameter tuning policy, and a cost function based on transferred work ratio. The proposed controller was successfully validated on a healthy human subject to assist unilateral hip extension in walking. The results showed that the optimal and adaptive RL controller as a new approach was feasible for tuning assistive torque profile of the hip exoskeleton that coordinated with human actions and reduced activation level of hip extensor muscle in human.
Reinforcement Learning Control of Robotic Knee with Human in the Loop by Flexible Policy Iteration
Jun 16, 2020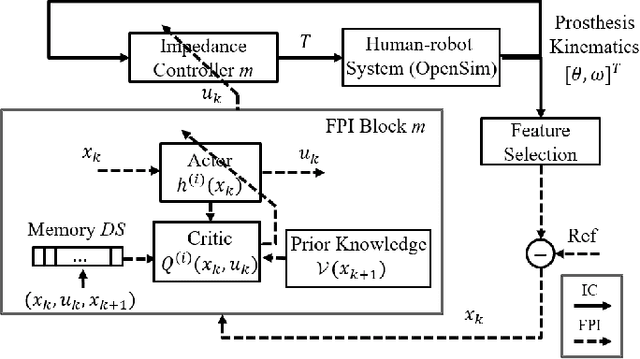
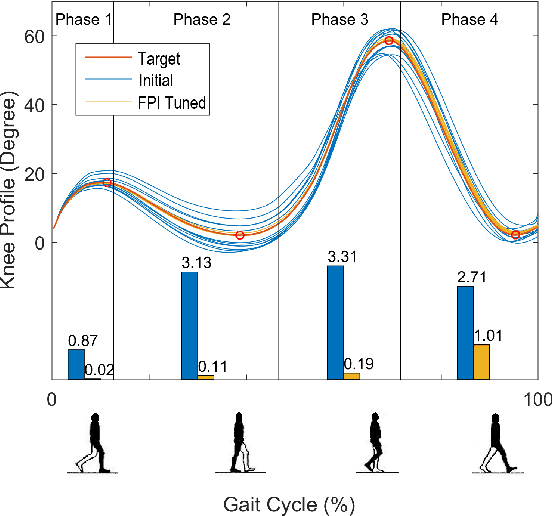
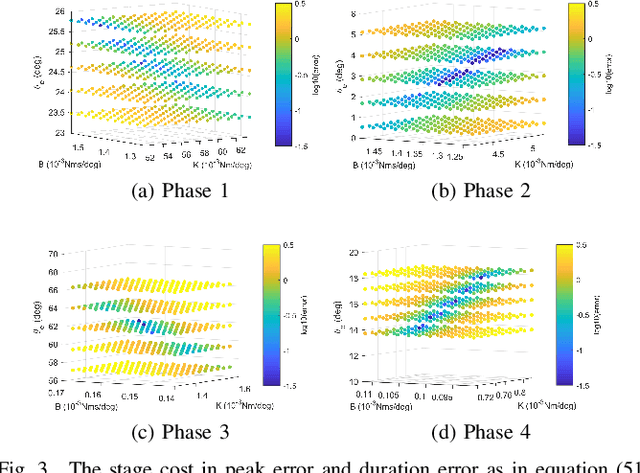
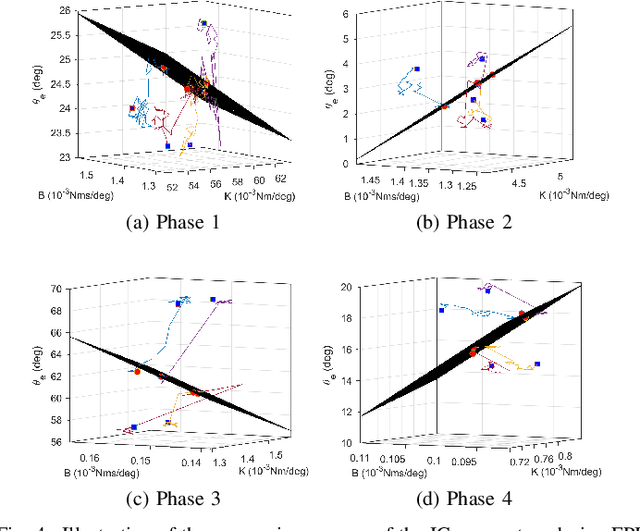
This study is motivated by a new class of challenging control problems described by automatic tuning of robotic knee control parameters with human in the loop. In addition to inter-person and intra-person variances inherent in such human-robot systems, human user safety and stability, as well as data and time efficiency should also be taken into design consideration. Here by data and time efficiency we mean learning and adaptation of device configurations takes place within countable gait cycles or within minutes of time. As solutions to this problem is not readily available, we therefore propose a new policy iteration based adaptive dynamic programming algorithm, namely the flexible policy iteration (FPI). We show that the FPI solves the control parameters via (weighted) least-squares while it incorporates data flexibly and utilizes prior knowledge. We provide analyses on stable control policies, non-increasing and converging value functions to Bellman optimality, and error bounds on the iterative value functions subject to approximation errors. We extensively evaluated the performance of FPI in a well-established locomotion simulator, the OpenSim under realistic conditions. By inspecting FPI with three other comparable algorithms, we demonstrate the FPI as a feasible data and time efficient design approach for adapting the control parameters of the prosthetic knee to co-adapt with the human user who also places control on the prosthesis. As the proposed FPI algorithm does not require stringent constraints or peculiar assumptions, we expect this reinforcement learning controller can potentially be applied to other challenging adaptive optimal control problems.