 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferable and Forecastable User Targeting Foundation Model
Dec 17, 2024



User targeting, the process of selecting targeted users from a pool of candidates for non-expert marketers, has garnered substantial attention with the advancements in digital marketing. However, existing user targeting methods encounter two significant challenges: (i) Poor cross-domain and cross-scenario transferability and generalization, and (ii) Insufficient forecastability in real-world applications. These limitations hinder their applicability across diverse industrial scenarios. In this work, we propose FIND, an industrial-grade, transferable, and forecastable user targeting foundation model. To enhance cross-domain transferability, our framework integrates heterogeneous multi-scenario user data, aligning them with one-sentence targeting demand inputs through contrastive pre-training. For improved forecastability, the text description of each user is derived based on anticipated future behaviors, while user representations are constructed from historical information. Experimental results demonstrate that our approach significantly outperforms existing baselines in cross-domain, real-world user targeting scenarios, showcasing the superior capabilities of FIND. Moreover, our method has been successfully deployed on the Alipay platform and is widely utilized across various scenarios.
Subgraph Retrieval Enhanced by Graph-Text Alignment for Commonsense Question Answering
Nov 11, 2024Commonsense question answering is a crucial task that requires machines to employ reasoning according to commonsense. Previous studies predominantly employ an extracting-and-modeling paradigm to harness the information in KG, which first extracts relevant subgraphs based on pre-defined rules and then proceeds to design various strategies aiming to improve the representations and fusion of the extracted structural knowledge. Despite their effectiveness, there are still two challenges. On one hand, subgraphs extracted by rule-based methods may have the potential to overlook critical nodes and result in uncontrollable subgraph size. On the other hand, the misalignment between graph and text modalities undermines the effectiveness of knowledge fusion, ultimately impacting the task performance. To deal with the problems above, we propose a novel framework: \textbf{S}ubgraph R\textbf{E}trieval Enhanced by Gra\textbf{P}h-\textbf{T}ext \textbf{A}lignment, named \textbf{SEPTA}. Firstly, we transform the knowledge graph into a database of subgraph vectors and propose a BFS-style subgraph sampling strategy to avoid information loss, leveraging the analogy between BFS and the message-passing mechanism. In addition, we propose a bidirectional contrastive learning approach for graph-text alignment, which effectively enhances both subgraph retrieval and knowledge fusion. Finally, all the retrieved information is combined for reasoning in the prediction module. Extensive experiments on five datasets demonstrate the effectiveness and robustness of our framework.
GraphRPM: Risk Pattern Mining on Industrial Large Attributed Graphs
Nov 11, 2024Graph-based patterns are extensively employed and favored by practitioners within industrial companies due to their capacity to represent the behavioral attributes and topological relationships among users, thereby offering enhanced interpretability in comparison to black-box models commonly utilized for classification and recognition tasks. For instance, within the scenario of transaction risk management, a graph pattern that is characteristic of a particular risk category can be readily employed to discern transactions fraught with risk, delineate networks of criminal activity, or investigate the methodologies employed by fraudsters. Nonetheless, graph data in industrial settings is often characterized by its massive scale, encompassing data sets with millions or even billions of nodes, making the manual extraction of graph patterns not only labor-intensive but also necessitating specialized knowledge in particular domains of risk. Moreover, existing methodologies for mining graph patterns encounter significant obstacles when tasked with analyzing large-scale attributed graphs. In this work, we introduce GraphRPM, an industry-purpose parallel and distributed risk pattern mining framework on large attributed graphs. The framework incorporates a novel edge-involved graph isomorphism network alongside optimized operations for parallel graph computation, which collectively contribute to a considerable reduction in computational complexity and resource expenditure. Moreover, the intelligent filtration of efficacious risky graph patterns is facilitated by the proposed evaluation metrics. Comprehensive experimental evaluations conducted on real-world datasets of varying sizes substantiate the capability of GraphRPM to adeptly address the challenges inherent in mining patterns from large-scale industrial attributed graphs, thereby underscoring its substantial value for industrial deployment.
LasTGL: An Industrial Framework for Large-Scale Temporal Graph Learning
Nov 30, 2023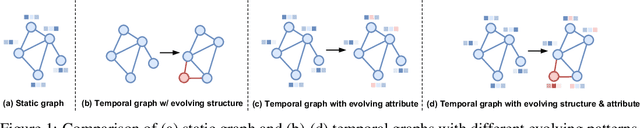


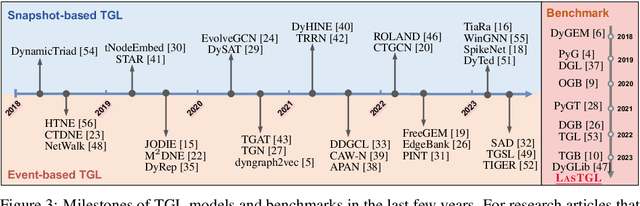
Over the past few years, graph neural networks (GNNs) have become powerful and practical tools for learning on (static) graph-structure data. However, many real-world applications, such as social networks and e-commerce, involve temporal graphs where nodes and edges are dynamically evolving. Temporal graph neural networks (TGNNs) have progressively emerged as an extension of GNNs to address time-evolving graphs and have gradually become a trending research topic in both academics and industry. Advancing research and application in such an emerging field necessitates the development of new tools to compose TGNN models and unify their different schemes for dealing with temporal graphs. In this work, we introduce LasTGL, an industrial framework that integrates unified and extensible implementations of common temporal graph learning algorithms for various advanced tasks. The purpose of LasTGL is to provide the essential building blocks for solving temporal graph learning tasks, focusing on the guiding principles of user-friendliness and quick prototyping on which PyTorch is based. In particular, LasTGL provides comprehensive temporal graph datasets, TGNN models and utilities along with well-documented tutorials, making it suitable for both absolute beginners and expert deep learning practitioners alike.
Hetero$^2$Net: Heterophily-aware Representation Learning on Heterogenerous Graphs
Oct 18, 2023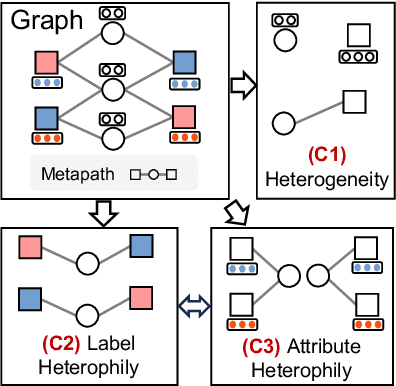
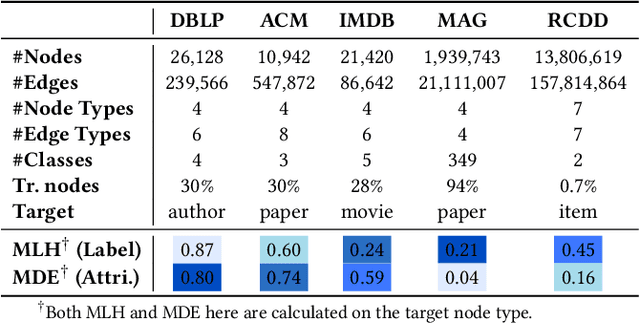
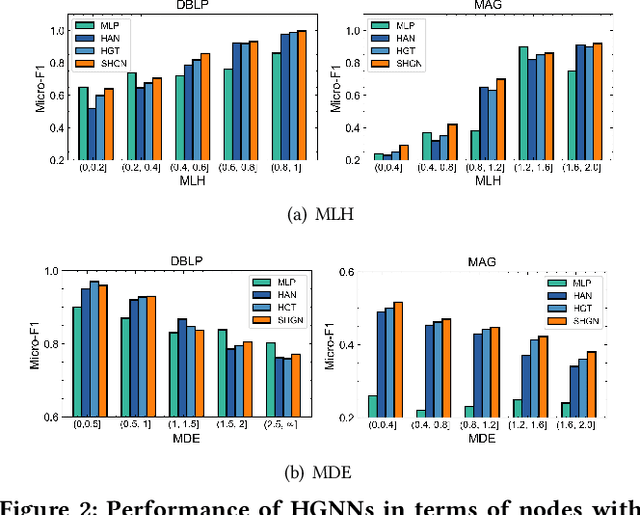
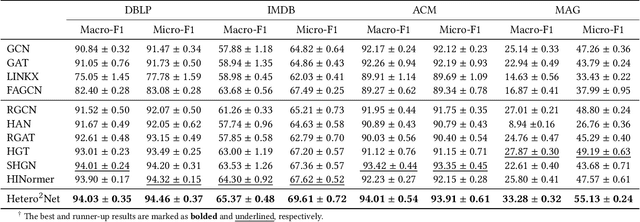
Real-world graphs are typically complex, exhibiting heterogeneity in the global structure, as well as strong heterophily within local neighborhoods. While a growing body of literature has revealed the limitations of common graph neural networks (GNNs) in handling homogeneous graphs with heterophily, little work has been conducted on investigating the heterophily properties in the context of heterogeneous graphs. To bridge this research gap, we identify the heterophily in heterogeneous graphs using metapaths and propose two practical metrics to quantitatively describe the levels of heterophily. Through in-depth investigations on several real-world heterogeneous graphs exhibiting varying levels of heterophily, we have observed that heterogeneous graph neural networks (HGNNs), which inherit many mechanisms from GNNs designed for homogeneous graphs, fail to generalize to heterogeneous graphs with heterophily or low level of homophily. To address the challenge, we present Hetero$^2$Net, a heterophily-aware HGNN that incorporates both masked metapath prediction and masked label prediction tasks to effectively and flexibly handle both homophilic and heterophilic heterogeneous graphs. We evaluate the performance of Hetero$^2$Net on five real-world heterogeneous graph benchmarks with varying levels of heterophily. The results demonstrate that Hetero$^2$Net outperforms strong baselines in the semi-supervised node classification task, providing valuable insights into effectively handling more complex heterogeneous graphs.
Self-supervision meets kernel graph neural models: From architecture to augmentations
Oct 17, 2023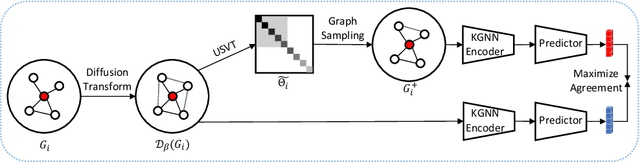
Graph representation learning has now become the de facto standard when handling graph-structured data, with the framework of message-passing graph neural networks (MPNN) being the most prevailing algorithmic tool. Despite its popularity, the family of MPNNs suffers from several drawbacks such as transparency and expressivity. Recently, the idea of designing neural models on graphs using the theory of graph kernels has emerged as a more transparent as well as sometimes more expressive alternative to MPNNs known as kernel graph neural networks (KGNNs). Developments on KGNNs are currently a nascent field of research, leaving several challenges from algorithmic design and adaptation to other learning paradigms such as self-supervised learning. In this paper, we improve the design and learning of KGNNs. Firstly, we extend the algorithmic formulation of KGNNs by allowing a more flexible graph-level similarity definition that encompasses former proposals like random walk graph kernel, as well as providing a smoother optimization objective that alleviates the need of introducing combinatorial learning procedures. Secondly, we enhance KGNNs through the lens of self-supervision via developing a novel structure-preserving graph data augmentation method called latent graph augmentation (LGA). Finally, we perform extensive empirical evaluations to demonstrate the efficacy of our proposed mechanisms. Experimental results over benchmark datasets suggest that our proposed model achieves competitive performance that is comparable to or sometimes outperforming state-of-the-art graph representation learning frameworks with or without self-supervision on graph classification tasks. Comparisons against other previously established graph data augmentation methods verify that the proposed LGA augmentation scheme captures better semantics of graph-level invariance.
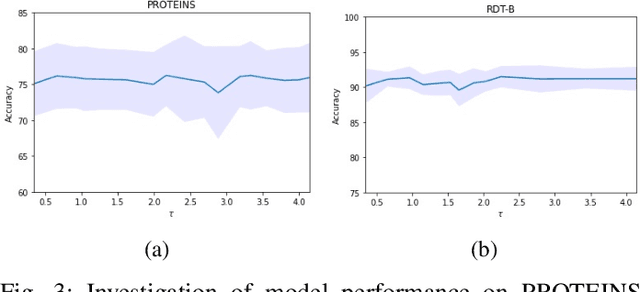
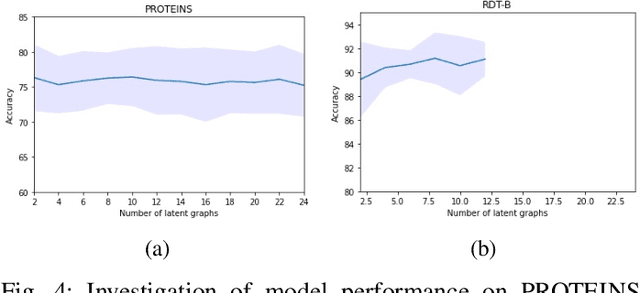
A Graph is Worth 1-bit Spikes: When Graph Contrastive Learning Meets Spiking Neural Networks
May 30, 2023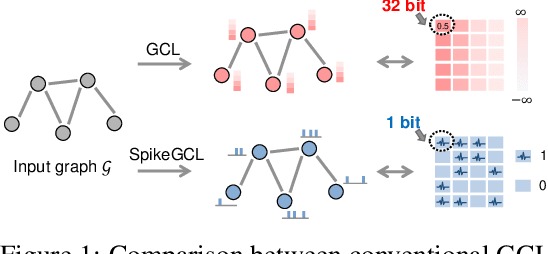

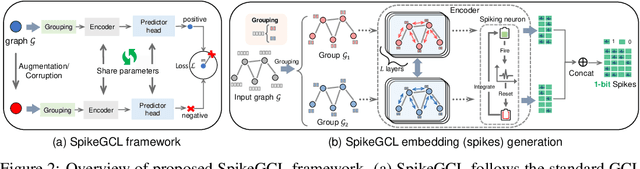
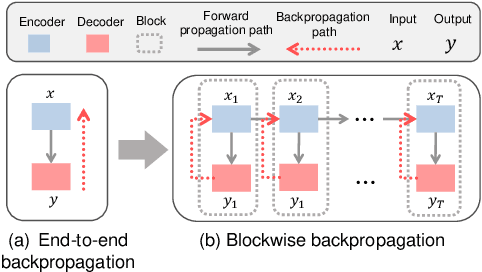
While contrastive self-supervised learning has become the de-facto learning paradigm for graph neural networks, the pursuit of high task accuracy requires a large hidden dimensionality to learn informative and discriminative full-precision representations, raising concerns about computation, memory footprint, and energy consumption burden (largely overlooked) for real-world applications. This paper explores a promising direction for graph contrastive learning (GCL) with spiking neural networks (SNNs), which leverage sparse and binary characteristics to learn more biologically plausible and compact representations. We propose SpikeGCL, a novel GCL framework to learn binarized 1-bit representations for graphs, making balanced trade-offs between efficiency and performance. We provide theoretical guarantees to demonstrate that SpikeGCL has comparable expressiveness with its full-precision counterparts. Experimental results demonstrate that, with nearly 32x representation storage compression, SpikeGCL is either comparable to or outperforms many fancy state-of-the-art supervised and self-supervised methods across several graph benchmarks.
DEDGAT: Dual Embedding of Directed Graph Attention Networks for Detecting Financial Risk
Mar 06, 2023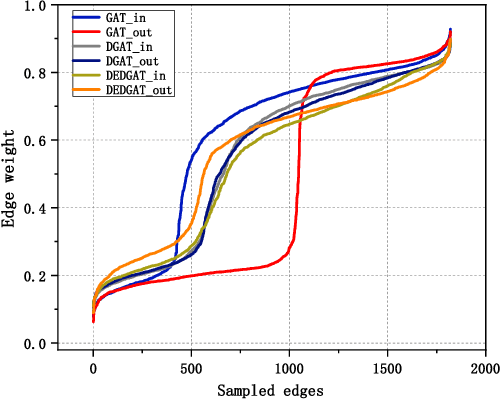
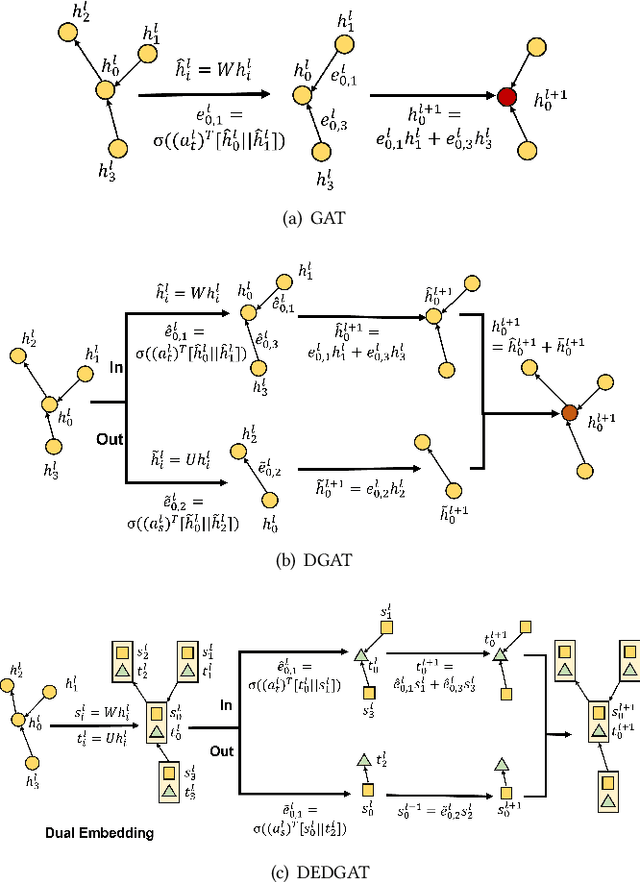
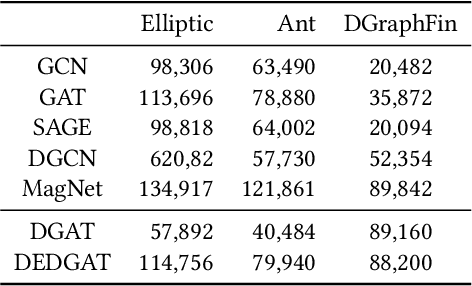
Graph representation plays an important role in the field of financial risk control, where the relationship among users can be constructed in a graph manner. In practical scenarios, the relationships between nodes in risk control tasks are bidirectional, e.g., merchants having both revenue and expense behaviors. Graph neural networks designed for undirected graphs usually aggregate discriminative node or edge representations with an attention strategy, but cannot fully exploit the out-degree information when used for the tasks built on directed graph, which leads to the problem of a directional bias. To tackle this problem, we propose a Directed Graph ATtention network called DGAT, which explicitly takes out-degree into attention calculation. In addition to having directional requirements, the same node might have different representations of its input and output, and thus we further propose a dual embedding of DGAT, referred to as DEDGAT. Specifically, DEDGAT assigns in-degree and out-degree representations to each node and uses these two embeddings to calculate the attention weights of in-degree and out-degree nodes, respectively. Experiments performed on the benchmark datasets show that DGAT and DEDGAT obtain better classification performance compared to undirected GAT. Also,the visualization results demonstrate that our methods can fully use both in-degree and out-degree information.