 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGT-SVQ: A Linear-Time Graph Transformer for Node Classification Using Spiking Vector Quantization
Apr 16, 2025Graph Transformers (GTs), which simultaneously integrate message-passing and self-attention mechanisms, have achieved promising empirical results in some graph prediction tasks. Although these approaches show the potential of Transformers in capturing long-range graph topology information, issues concerning the quadratic complexity and high computing energy consumption severely limit the scalability of GTs on large-scale graphs. Recently, as brain-inspired neural networks, Spiking Neural Networks (SNNs), facilitate the development of graph representation learning methods with lower computational and storage overhead through the unique event-driven spiking neurons. Inspired by these characteristics, we propose a linear-time Graph Transformer using Spiking Vector Quantization (GT-SVQ) for node classification. GT-SVQ reconstructs codebooks based on rate coding outputs from spiking neurons, and injects the codebooks into self-attention blocks to aggregate global information in linear complexity. Besides, spiking vector quantization effectively alleviates codebook collapse and the reliance on complex machinery (distance measure, auxiliary loss, etc.) present in previous vector quantization-based graph learning methods. In experiments, we compare GT-SVQ with other state-of-the-art baselines on node classification datasets ranging from small to large. Experimental results show that GT-SVQ has achieved competitive performances on most datasets while maintaining up to 130x faster inference speed compared to other GTs.
Are Large Language Models In-Context Graph Learners?
Feb 19, 2025
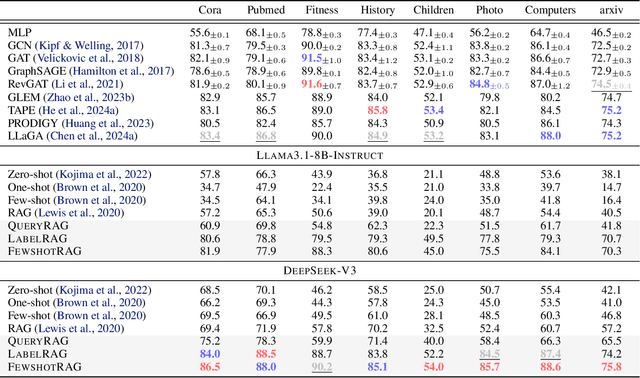


Large language models (LLMs) have demonstrated remarkable in-context reasoning capabilities across a wide range of tasks, particularly with unstructured inputs such as language or images. However, LLMs struggle to handle structured data, such as graphs, due to their lack of understanding of non-Euclidean structures. As a result, without additional fine-tuning, their performance significantly lags behind that of graph neural networks (GNNs) in graph learning tasks. In this paper, we show that learning on graph data can be conceptualized as a retrieval-augmented generation (RAG) process, where specific instances (e.g., nodes or edges) act as queries, and the graph itself serves as the retrieved context. Building on this insight, we propose a series of RAG frameworks to enhance the in-context learning capabilities of LLMs for graph learning tasks. Comprehensive evaluations demonstrate that our proposed RAG frameworks significantly improve LLM performance on graph-based tasks, particularly in scenarios where a pretrained LLM must be used without modification or accessed via an API.
Measuring Diversity in Synthetic Datasets
Feb 12, 2025Large language models (LLMs) are widely adopted to generate synthetic datasets for various natural language processing (NLP) tasks, such as text classification and summarization. However, accurately measuring the diversity of these synthetic datasets-an aspect crucial for robust model performance-remains a significant challenge. In this paper, we introduce DCScore, a novel method for measuring synthetic dataset diversity from a classification perspective. Specifically, DCScore formulates diversity evaluation as a sample classification task, leveraging mutual relationships among samples. We further provide theoretical verification of the diversity-related axioms satisfied by DCScore, highlighting its role as a principled diversity evaluation method. Experimental results on synthetic datasets reveal that DCScore enjoys a stronger correlation with multiple diversity pseudo-truths of evaluated datasets, underscoring its effectiveness. Moreover, both empirical and theoretical evidence demonstrate that DCScore substantially reduces computational costs compared to existing approaches. Code is available at: https://github.com/BlueWhaleLab/DCScore.
Revisiting and Benchmarking Graph Autoencoders: A Contrastive Learning Perspective
Oct 14, 2024



Graph autoencoders (GAEs) are self-supervised learning models that can learn meaningful representations of graph-structured data by reconstructing the input graph from a low-dimensional latent space. Over the past few years, GAEs have gained significant attention in academia and industry. In particular, the recent advent of GAEs with masked autoencoding schemes marks a significant advancement in graph self-supervised learning research. While numerous GAEs have been proposed, the underlying mechanisms of GAEs are not well understood, and a comprehensive benchmark for GAEs is still lacking. In this work, we bridge the gap between GAEs and contrastive learning by establishing conceptual and methodological connections. We revisit the GAEs studied in previous works and demonstrate how contrastive learning principles can be applied to GAEs. Motivated by these insights, we introduce lrGAE (left-right GAE), a general and powerful GAE framework that leverages contrastive learning principles to learn meaningful representations. Our proposed lrGAE not only facilitates a deeper understanding of GAEs but also sets a new benchmark for GAEs across diverse graph-based learning tasks. The source code for lrGAE, including the baselines and all the code for reproducing the results, is publicly available at https://github.com/EdisonLeeeee/lrGAE.
L^2CL: Embarrassingly Simple Layer-to-Layer Contrastive Learning for Graph Collaborative Filtering
Jul 19, 2024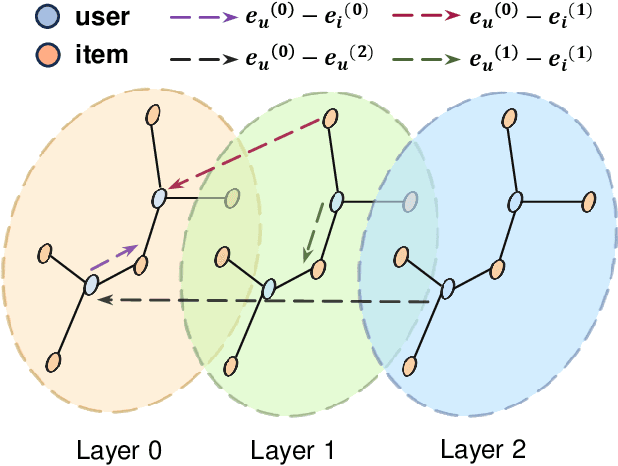
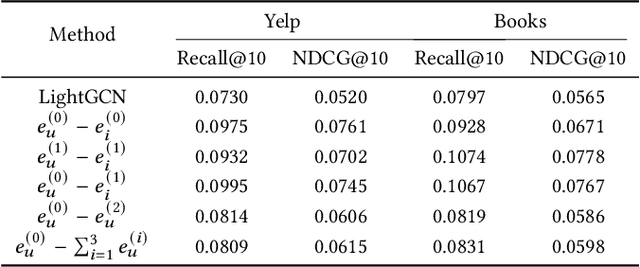
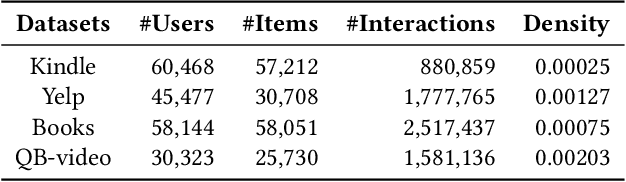
Graph neural networks (GNNs) have recently emerged as an effective approach to model neighborhood signals in collaborative filtering. Towards this research line, graph contrastive learning (GCL) demonstrates robust capabilities to address the supervision label shortage issue through generating massive self-supervised signals. Despite its effectiveness, GCL for recommendation suffers seriously from two main challenges: i) GCL relies on graph augmentation to generate semantically different views for contrasting, which could potentially disrupt key information and introduce unwanted noise; ii) current works for GCL primarily focus on contrasting representations using sophisticated networks architecture (usually deep) to capture high-order interactions, which leads to increased computational complexity and suboptimal training efficiency. To this end, we propose L2CL, a principled Layer-to-Layer Contrastive Learning framework that contrasts representations from different layers. By aligning the semantic similarities between different layers, L2CL enables the learning of complex structural relationships and gets rid of the noise perturbation in stochastic data augmentation. Surprisingly, we find that L2CL, using only one-hop contrastive learning paradigm, is able to capture intrinsic semantic structures and improve the quality of node representation, leading to a simple yet effective architecture. We also provide theoretical guarantees for L2CL in minimizing task-irrelevant information. Extensive experiments on five real-world datasets demonstrate the superiority of our model over various state-of-the-art collaborative filtering methods. Our code is available at https://github.com/downeykking/L2CL.
Revisiting Modularity Maximization for Graph Clustering: A Contrastive Learning Perspective
Jun 20, 2024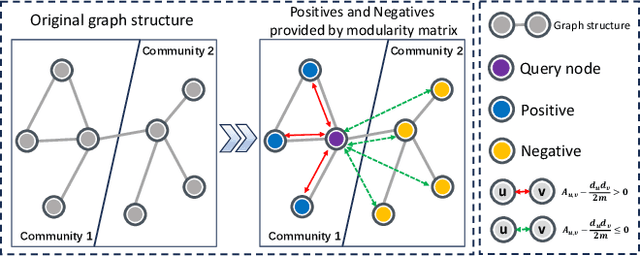
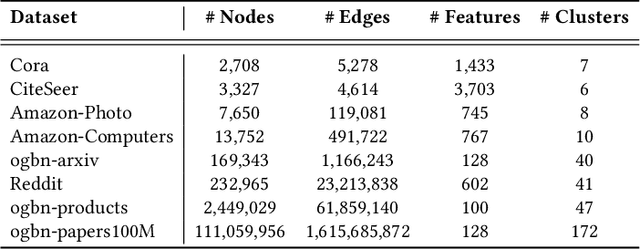
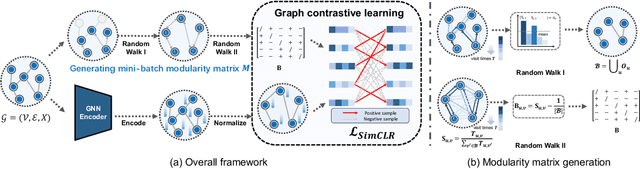
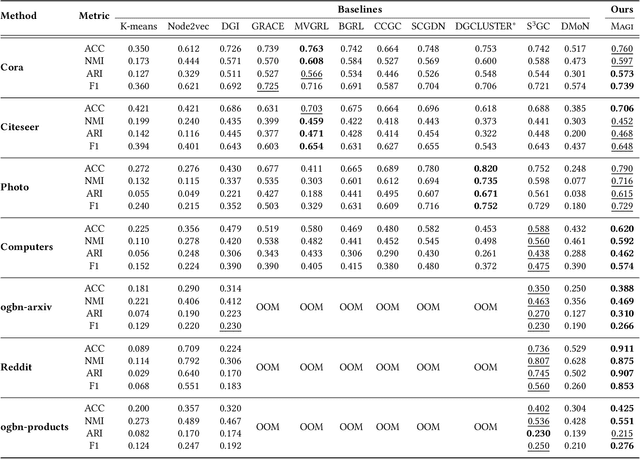
Graph clustering, a fundamental and challenging task in graph mining, aims to classify nodes in a graph into several disjoint clusters. In recent years, graph contrastive learning (GCL) has emerged as a dominant line of research in graph clustering and advances the new state-of-the-art. However, GCL-based methods heavily rely on graph augmentations and contrastive schemes, which may potentially introduce challenges such as semantic drift and scalability issues. Another promising line of research involves the adoption of modularity maximization, a popular and effective measure for community detection, as the guiding principle for clustering tasks. Despite the recent progress, the underlying mechanism of modularity maximization is still not well understood. In this work, we dig into the hidden success of modularity maximization for graph clustering. Our analysis reveals the strong connections between modularity maximization and graph contrastive learning, where positive and negative examples are naturally defined by modularity. In light of our results, we propose a community-aware graph clustering framework, coined MAGI, which leverages modularity maximization as a contrastive pretext task to effectively uncover the underlying information of communities in graphs, while avoiding the problem of semantic drift. Extensive experiments on multiple graph datasets verify the effectiveness of MAGI in terms of scalability and clustering performance compared to state-of-the-art graph clustering methods. Notably, MAGI easily scales a sufficiently large graph with 100M nodes while outperforming strong baselines.
One Fits All: Learning Fair Graph Neural Networks for Various Sensitive Attributes
Jun 19, 2024



Recent studies have highlighted fairness issues in Graph Neural Networks (GNNs), where they produce discriminatory predictions against specific protected groups categorized by sensitive attributes such as race and age. While various efforts to enhance GNN fairness have made significant progress, these approaches are often tailored to specific sensitive attributes. Consequently, they necessitate retraining the model from scratch to accommodate changes in the sensitive attribute requirement, resulting in high computational costs. To gain deeper insights into this issue, we approach the graph fairness problem from a causal modeling perspective, where we identify the confounding effect induced by the sensitive attribute as the underlying reason. Motivated by this observation, we formulate the fairness problem in graphs from an invariant learning perspective, which aims to learn invariant representations across environments. Accordingly, we propose a graph fairness framework based on invariant learning, namely FairINV, which enables the training of fair GNNs to accommodate various sensitive attributes within a single training session. Specifically, FairINV incorporates sensitive attribute partition and trains fair GNNs by eliminating spurious correlations between the label and various sensitive attributes. Experimental results on several real-world datasets demonstrate that FairINV significantly outperforms state-of-the-art fairness approaches, underscoring its effectiveness. Our code is available via: https://github.com/ZzoomD/FairINV/.
State Space Models on Temporal Graphs: A First-Principles Study
Jun 03, 2024Over the past few years, research on deep graph learning has shifted from static graphs to temporal graphs in response to real-world complex systems that exhibit dynamic behaviors. In practice, temporal graphs are formalized as an ordered sequence of static graph snapshots observed at discrete time points. Sequence models such as RNNs or Transformers have long been the predominant backbone networks for modeling such temporal graphs. Yet, despite the promising results, RNNs struggle with long-range dependencies, while transformers are burdened by quadratic computational complexity. Recently, state space models (SSMs), which are framed as discretized representations of an underlying continuous-time linear dynamical system, have garnered substantial attention and achieved breakthrough advancements in independent sequence modeling. In this work, we undertake a principled investigation that extends SSM theory to temporal graphs by integrating structural information into the online approximation objective via the adoption of a Laplacian regularization term. The emergent continuous-time system introduces novel algorithmic challenges, thereby necessitating our development of GraphSSM, a graph state space model for modeling the dynamics of temporal graphs. Extensive experimental results demonstrate the effectiveness of our GraphSSM framework across various temporal graph benchmarks.
Fair Graph Representation Learning via Sensitive Attribute Disentanglement
May 11, 2024


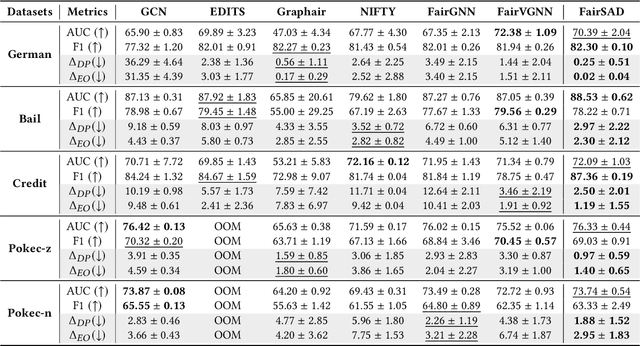
Group fairness for Graph Neural Networks (GNNs), which emphasizes algorithmic decisions neither favoring nor harming certain groups defined by sensitive attributes (e.g., race and gender), has gained considerable attention. In particular, the objective of group fairness is to ensure that the decisions made by GNNs are independent of the sensitive attribute. To achieve this objective, most existing approaches involve eliminating sensitive attribute information in node representations or algorithmic decisions. However, such ways may also eliminate task-related information due to its inherent correlation with the sensitive attribute, leading to a sacrifice in utility. In this work, we focus on improving the fairness of GNNs while preserving task-related information and propose a fair GNN framework named FairSAD. Instead of eliminating sensitive attribute information, FairSAD enhances the fairness of GNNs via Sensitive Attribute Disentanglement (SAD), which separates the sensitive attribute-related information into an independent component to mitigate its impact. Additionally, FairSAD utilizes a channel masking mechanism to adaptively identify the sensitive attribute-related component and subsequently decorrelates it. Overall, FairSAD minimizes the impact of the sensitive attribute on GNN outcomes rather than eliminating sensitive attributes, thereby preserving task-related information associated with the sensitive attribute. Furthermore, experiments conducted on several real-world datasets demonstrate that FairSAD outperforms other state-of-the-art methods by a significant margin in terms of both fairness and utility performance. Our source code is available at https://github.com/ZzoomD/FairSAD.
SGHormer: An Energy-Saving Graph Transformer Driven by Spikes
Mar 26, 2024


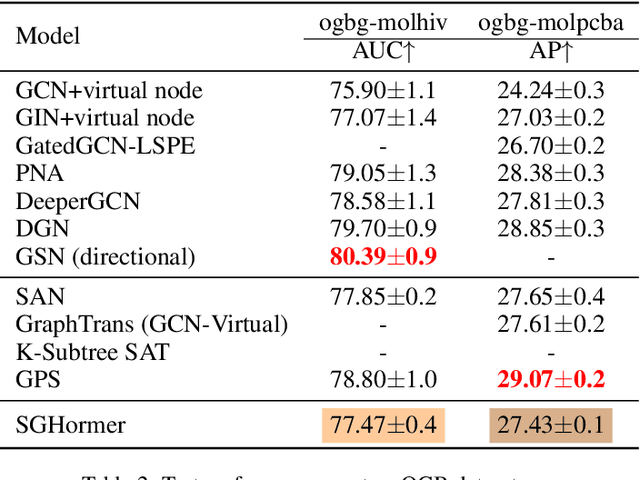
Graph Transformers (GTs) with powerful representation learning ability make a huge success in wide range of graph tasks. However, the costs behind outstanding performances of GTs are higher energy consumption and computational overhead. The complex structure and quadratic complexity during attention calculation in vanilla transformer seriously hinder its scalability on the large-scale graph data. Though existing methods have made strides in simplifying combinations among blocks or attention-learning paradigm to improve GTs' efficiency, a series of energy-saving solutions originated from biologically plausible structures are rarely taken into consideration when constructing GT framework. To this end, we propose a new spiking-based graph transformer (SGHormer). It turns full-precision embeddings into sparse and binarized spikes to reduce memory and computational costs. The spiking graph self-attention and spiking rectify blocks in SGHormer explicitly capture global structure information and recover the expressive power of spiking embeddings, respectively. In experiments, SGHormer achieves comparable performances to other full-precision GTs with extremely low computational energy consumption. The results show that SGHomer makes a remarkable progress in the field of low-energy GTs.