 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAGER: Self-Evolving User Policy Skills for Recommendation Agent
Apr 16, 2026Large language model (LLM) based recommendation agents personalize what they know through evolving per-user semantic memory, yet how they reason remains a universal, static system prompt shared identically across all users. This asymmetry is a fundamental bottleneck: when a recommendation fails, the agent updates its memory of user preferences but never interrogates the decision logic that produced the failure, leaving its reasoning process structurally unchanged regardless of how many mistakes it accumulates. To address this bottleneck, we propose SAGER (Self-Evolving Agent for Personalized Recommendation), the first recommendation agent framework in which each user is equipped with a dedicated policy skill, a structured natural-language document encoding personalized decision principles that evolves continuously through interaction. SAGER introduces a two-representation skill architecture that decouples a rich evolution substrate from a minimal inference-time injection, an incremental contrastive chain-of-thought engine that diagnoses reasoning flaws by contrasting accepted against unchosen items while preserving accumulated priors, and skill-augmented listwise reasoning that creates fine-grained decision boundaries where the evolved skill provides genuine discriminative value. Experiments on four public benchmarks demonstrate that SAGER achieves state-of-the-art performance, with gains orthogonal to memory accumulation, confirming that personalizing the reasoning process itself is a qualitatively distinct source of recommendation improvement.
HiGR: Efficient Generative Slate Recommendation via Hierarchical Planning and Multi-Objective Preference Alignment
Dec 31, 2025Slate recommendation, where users are presented with a ranked list of items simultaneously, is widely adopted in online platforms. Recent advances in generative models have shown promise in slate recommendation by modeling sequences of discrete semantic IDs autoregressively. However, existing autoregressive approaches suffer from semantically entangled item tokenization and inefficient sequential decoding that lacks holistic slate planning. To address these limitations, we propose HiGR, an efficient generative slate recommendation framework that integrates hierarchical planning with listwise preference alignment. First, we propose an auto-encoder utilizing residual quantization and contrastive constraints to tokenize items into semantically structured IDs for controllable generation. Second, HiGR decouples generation into a list-level planning stage for global slate intent, followed by an item-level decoding stage for specific item selection. Third, we introduce a listwise preference alignment objective to directly optimize slate quality using implicit user feedback. Experiments on our large-scale commercial media platform demonstrate that HiGR delivers consistent improvements in both offline evaluations and online deployment. Specifically, it outperforms state-of-the-art methods by over 10% in offline recommendation quality with a 5x inference speedup, while further achieving a 1.22% and 1.73% increase in Average Watch Time and Average Video Views in online A/B tests.
Topology-Driven Attribute Recovery for Attribute Missing Graph Learning in Social Internet of Things
Jan 17, 2025



With the advancement of information technology, the Social Internet of Things (SIoT) has fostered the integration of physical devices and social networks, deepening the study of complex interaction patterns. Text Attribute Graphs (TAGs) capture both topological structures and semantic attributes, enhancing the analysis of complex interactions within the SIoT. However, existing graph learning methods are typically designed for complete attributed graphs, and the common issue of missing attributes in Attribute Missing Graphs (AMGs) increases the difficulty of analysis tasks. To address this, we propose the Topology-Driven Attribute Recovery (TDAR) framework, which leverages topological data for AMG learning. TDAR introduces an improved pre-filling method for initial attribute recovery using native graph topology. Additionally, it dynamically adjusts propagation weights and incorporates homogeneity strategies within the embedding space to suit AMGs' unique topological structures, effectively reducing noise during information propagation. Extensive experiments on public datasets demonstrate that TDAR significantly outperforms state-of-the-art methods in attribute reconstruction and downstream tasks, offering a robust solution to the challenges posed by AMGs. The code is available at https://github.com/limengran98/TDAR.
L^2CL: Embarrassingly Simple Layer-to-Layer Contrastive Learning for Graph Collaborative Filtering
Jul 19, 2024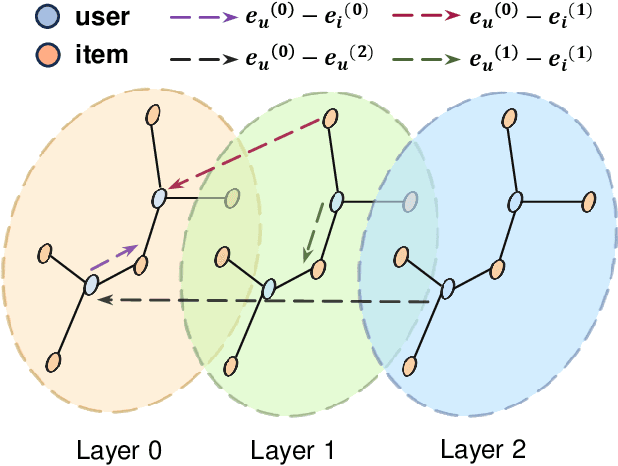
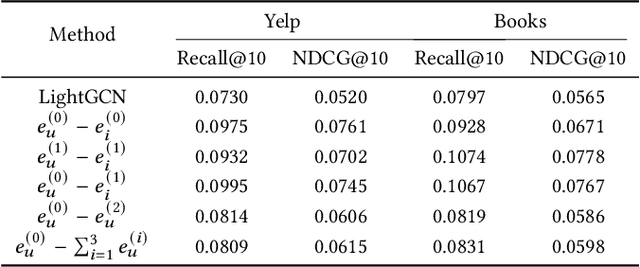
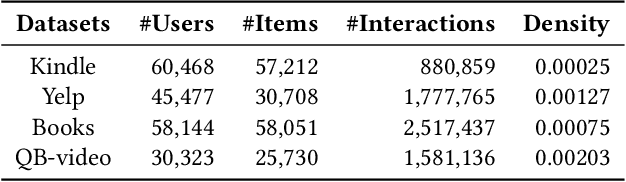
Graph neural networks (GNNs) have recently emerged as an effective approach to model neighborhood signals in collaborative filtering. Towards this research line, graph contrastive learning (GCL) demonstrates robust capabilities to address the supervision label shortage issue through generating massive self-supervised signals. Despite its effectiveness, GCL for recommendation suffers seriously from two main challenges: i) GCL relies on graph augmentation to generate semantically different views for contrasting, which could potentially disrupt key information and introduce unwanted noise; ii) current works for GCL primarily focus on contrasting representations using sophisticated networks architecture (usually deep) to capture high-order interactions, which leads to increased computational complexity and suboptimal training efficiency. To this end, we propose L2CL, a principled Layer-to-Layer Contrastive Learning framework that contrasts representations from different layers. By aligning the semantic similarities between different layers, L2CL enables the learning of complex structural relationships and gets rid of the noise perturbation in stochastic data augmentation. Surprisingly, we find that L2CL, using only one-hop contrastive learning paradigm, is able to capture intrinsic semantic structures and improve the quality of node representation, leading to a simple yet effective architecture. We also provide theoretical guarantees for L2CL in minimizing task-irrelevant information. Extensive experiments on five real-world datasets demonstrate the superiority of our model over various state-of-the-art collaborative filtering methods. Our code is available at https://github.com/downeykking/L2CL.
CTRL: Continuous-Time Representation Learning on Temporal Heterogeneous Information Network
May 11, 2024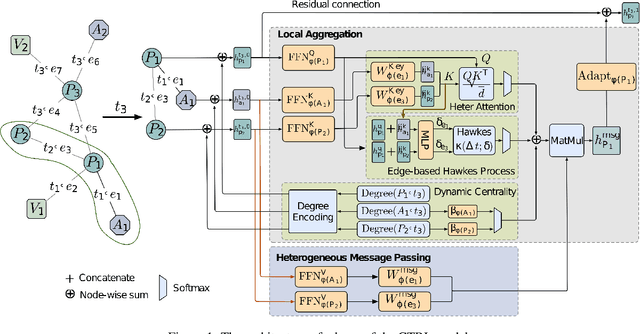
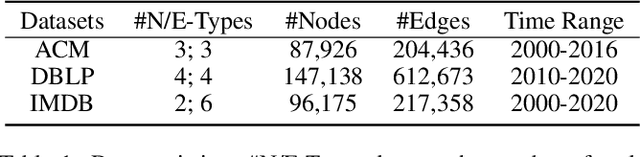
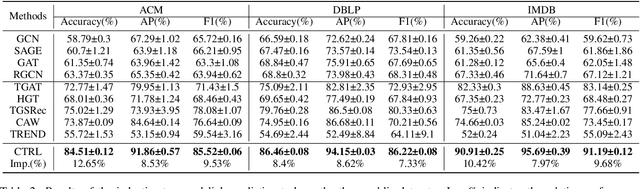
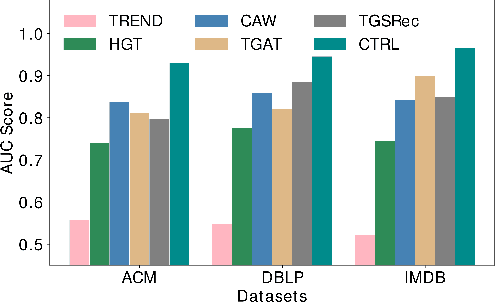
Inductive representation learning on temporal heterogeneous graphs is crucial for scalable deep learning on heterogeneous information networks (HINs) which are time-varying, such as citation networks. However, most existing approaches are not inductive and thus cannot handle new nodes or edges. Moreover, previous temporal graph embedding methods are often trained with the temporal link prediction task to simulate the link formation process of temporal graphs, while ignoring the evolution of high-order topological structures on temporal graphs. To fill these gaps, we propose a Continuous-Time Representation Learning (CTRL) model on temporal HINs. To preserve heterogeneous node features and temporal structures, CTRL integrates three parts in a single layer, they are 1) a \emph{heterogeneous attention} unit that measures the semantic correlation between nodes, 2) a \emph{edge-based Hawkes process} to capture temporal influence between heterogeneous nodes, and 3) \emph{dynamic centrality} that indicates the dynamic importance of a node. We train the CTRL model with a future event (a subgraph) prediction task to capture the evolution of the high-order network structure. Extensive experiments have been conducted on three benchmark datasets. The results demonstrate that our model significantly boosts performance and outperforms various state-of-the-art approaches. Ablation studies are conducted to demonstrate the effectiveness of the model design.
Decomposition for Enhancing Attention: Improving LLM-based Text-to-SQL through Workflow Paradigm
Feb 16, 2024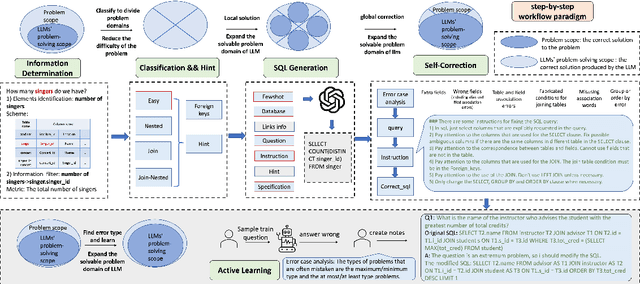



In-context learning of large-language models (LLMs) has achieved remarkable success in the field of natural language processing, while extensive case studies reveal that the single-step chain-of-thought prompting approach faces challenges such as attention diffusion and inadequate performance in complex tasks like text-to-SQL. To improve the contextual learning capabilities of LLMs in text-to-SQL, a workflow paradigm method is proposed, aiming to enhance the attention and problem-solving scope of LLMs through decomposition. Specifically, the information determination module for eliminating redundant information and the brand-new prompt structure based on problem classification greatly enhance the model's attention. Additionally, the inclusion of self-correcting and active learning modules greatly expands the problem-solving scope of LLMs, hence improving the upper limit of LLM-based approaches. Extensive experiments conducted on three datasets demonstrate that our approach outperforms other methods by a significant margin. About 2-3 percentage point improvements compared to the existing baseline on the Spider Dev and Spider-Realistic datasets and new SOTA results on the Spider Test dataset are achieved. Our code is available on GitHub: \url{https://github.com/FlyingFeather/DEA-SQL}.
One for All, All for One: Learning and Transferring User Embeddings for Cross-Domain Recommendation
Nov 22, 2022Cross-domain recommendation is an important method to improve recommender system performance, especially when observations in target domains are sparse. However, most existing techniques focus on single-target or dual-target cross-domain recommendation (CDR) and are hard to be generalized to CDR with multiple target domains. In addition, the negative transfer problem is prevalent in CDR, where the recommendation performance in a target domain may not always be enhanced by knowledge learned from a source domain, especially when the source domain has sparse data. In this study, we propose CAT-ART, a multi-target CDR method that learns to improve recommendations in all participating domains through representation learning and embedding transfer. Our method consists of two parts: a self-supervised Contrastive AuToencoder (CAT) framework to generate global user embeddings based on information from all participating domains, and an Attention-based Representation Transfer (ART) framework which transfers domain-specific user embeddings from other domains to assist with target domain recommendation. CAT-ART boosts the recommendation performance in any target domain through the combined use of the learned global user representation and knowledge transferred from other domains, in addition to the original user embedding in the target domain. We conducted extensive experiments on a collected real-world CDR dataset spanning 5 domains and involving a million users. Experimental results demonstrate the superiority of the proposed method over a range of prior arts. We further conducted ablation studies to verify the effectiveness of the proposed components. Our collected dataset will be open-sourced to facilitate future research in the field of multi-domain recommender systems and user modeling.
TransRec: Learning Transferable Recommendation from Mixture-of-Modality Feedback
Jun 13, 2022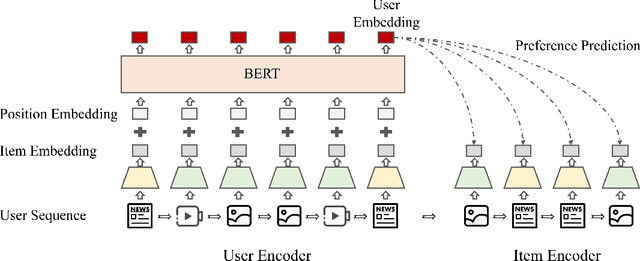
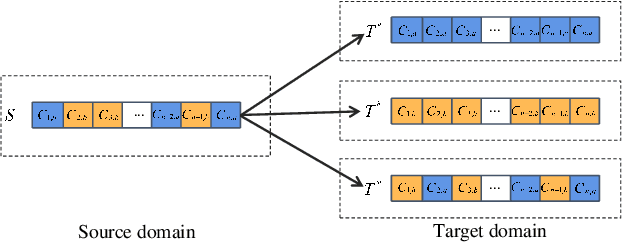
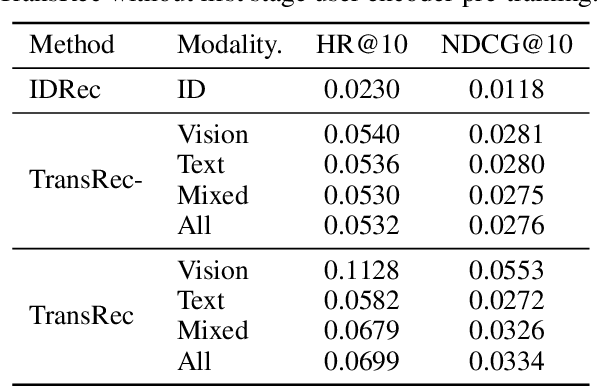
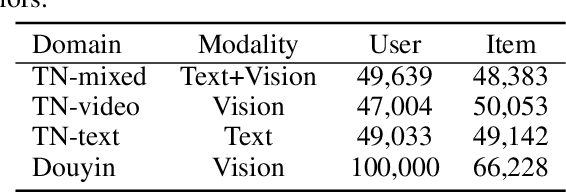
Learning big models and then transfer has become the de facto practice in computer vision (CV) and natural language processing (NLP). However, such unified paradigm is uncommon for recommender systems (RS). A critical issue that hampers this is that standard recommendation models are built on unshareable identity data, where both users and their interacted items are represented by unique IDs. In this paper, we study a novel scenario where user's interaction feedback involves mixture-of-modality (MoM) items. We present TransRec, a straightforward modification done on the popular ID-based RS framework. TransRec directly learns from MoM feedback in an end-to-end manner, and thus enables effective transfer learning under various scenarios without relying on overlapped users or items. We empirically study the transferring ability of TransRec across four different real-world recommendation settings. Besides, we study its effects by scaling the size of source and target data. Our results suggest that learning recommenders from MoM feedback provides a promising way to realize universal recommender systems. Our code and datasets will be made available.
Graph Neural Networks with Feature and Structure Aware Random Walk
Nov 19, 2021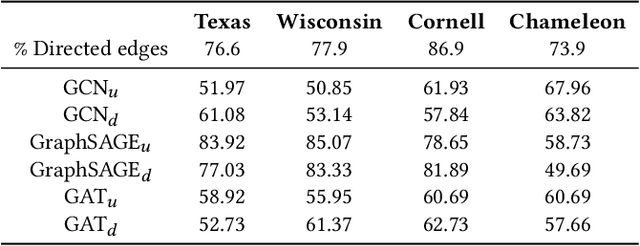
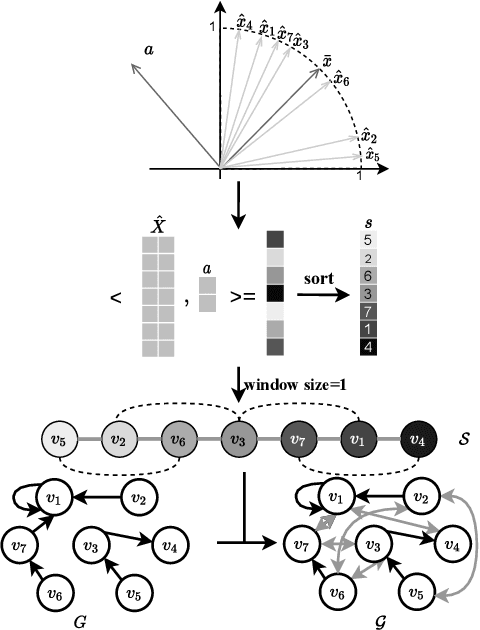
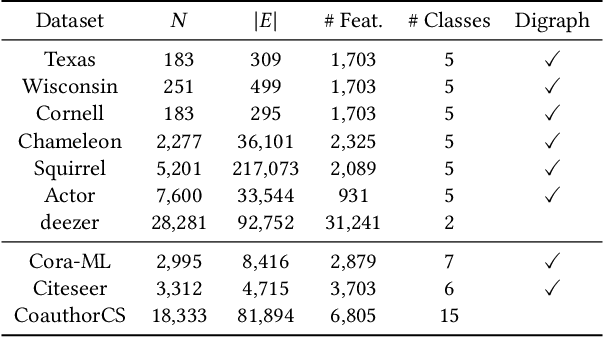
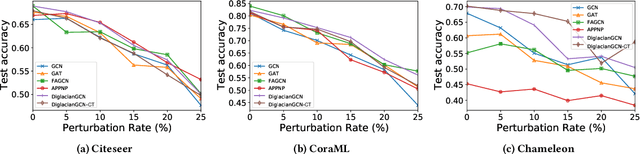
Graph Neural Networks (GNNs) have received increasing attention for representation learning in various machine learning tasks. However, most existing GNNs applying neighborhood aggregation usually perform poorly on the graph with heterophily where adjacent nodes belong to different classes. In this paper, we show that in typical heterphilous graphs, the edges may be directed, and whether to treat the edges as is or simply make them undirected greatly affects the performance of the GNN models. Furthermore, due to the limitation of heterophily, it is highly beneficial for the nodes to aggregate messages from similar nodes beyond local neighborhood.These motivate us to develop a model that adaptively learns the directionality of the graph, and exploits the underlying long-distance correlations between nodes. We first generalize the graph Laplacian to digraph based on the proposed Feature-Aware PageRank algorithm, which simultaneously considers the graph directionality and long-distance feature similarity between nodes. Then digraph Laplacian defines a graph propagation matrix that leads to a model called {\em DiglacianGCN}. Based on this, we further leverage the node proximity measured by commute times between nodes, in order to preserve the nodes' long-distance correlation on the topology level. Extensive experiments on ten datasets with different levels of homophily demonstrate the effectiveness of our method over existing solutions in the task of node classification.
RecGURU: Adversarial Learning of Generalized User Representations for Cross-Domain Recommendation
Nov 19, 2021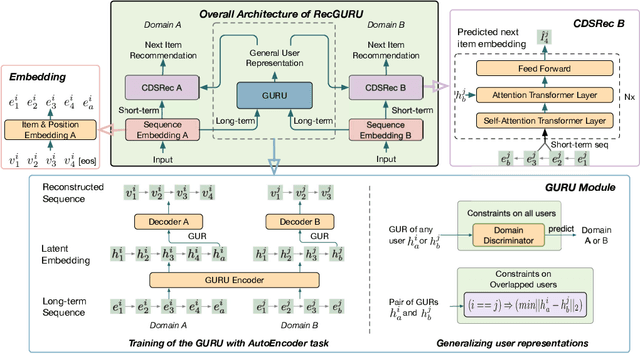
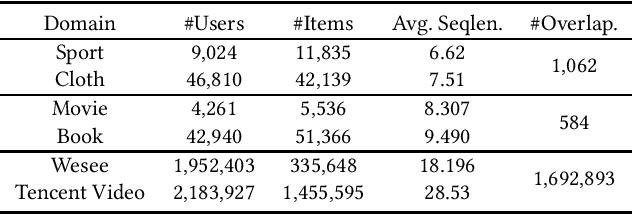
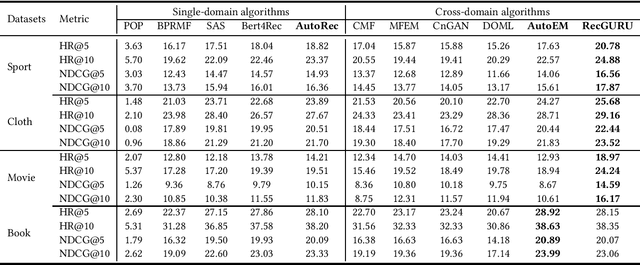
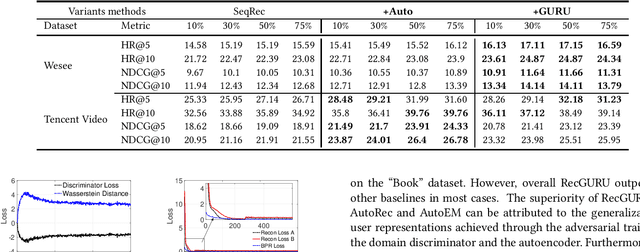
Cross-domain recommendation can help alleviate the data sparsity issue in traditional sequential recommender systems. In this paper, we propose the RecGURU algorithm framework to generate a Generalized User Representation (GUR) incorporating user information across domains in sequential recommendation, even when there is minimum or no common users in the two domains. We propose a self-attentive autoencoder to derive latent user representations, and a domain discriminator, which aims to predict the origin domain of a generated latent representation. We propose a novel adversarial learning method to train the two modules to unify user embeddings generated from different domains into a single global GUR for each user. The learned GUR captures the overall preferences and characteristics of a user and thus can be used to augment the behavior data and improve recommendations in any single domain in which the user is involved. Extensive experiments have been conducted on two public cross-domain recommendation datasets as well as a large dataset collected from real-world applications. The results demonstrate that RecGURU boosts performance and outperforms various state-of-the-art sequential recommendation and cross-domain recommendation methods. The collected data will be released to facilitate future research.