 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOlaGPT: Empowering LLMs With Human-like Problem-Solving Abilities
May 23, 2023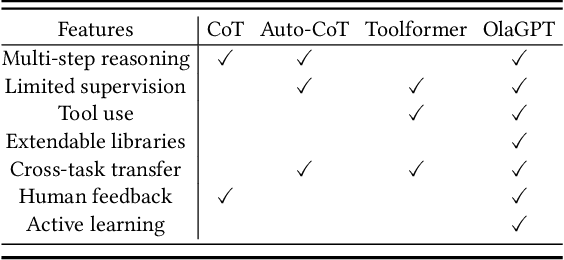
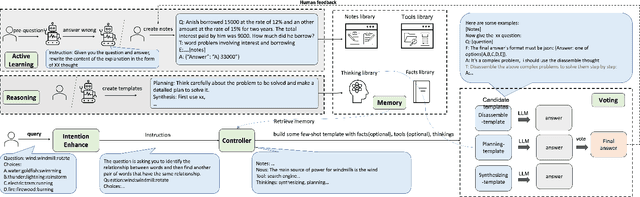
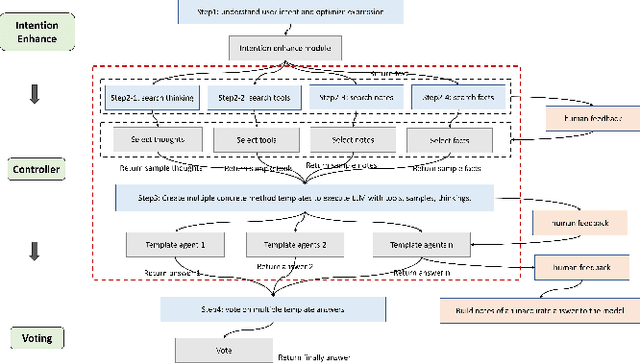

In most current research, large language models (LLMs) are able to perform reasoning tasks by generating chains of thought through the guidance of specific prompts. However, there still exists a significant discrepancy between their capability in solving complex reasoning problems and that of humans. At present, most approaches focus on chains of thought (COT) and tool use, without considering the adoption and application of human cognitive frameworks. It is well-known that when confronting complex reasoning challenges, humans typically employ various cognitive abilities, and necessitate interaction with all aspects of tools, knowledge, and the external environment information to accomplish intricate tasks. This paper introduces a novel intelligent framework, referred to as OlaGPT. OlaGPT carefully studied a cognitive architecture framework, and propose to simulate certain aspects of human cognition. The framework involves approximating different cognitive modules, including attention, memory, reasoning, learning, and corresponding scheduling and decision-making mechanisms. Inspired by the active learning mechanism of human beings, it proposes a learning unit to record previous mistakes and expert opinions, and dynamically refer to them to strengthen their ability to solve similar problems. The paper also outlines common effective reasoning frameworks for human problem-solving and designs Chain-of-Thought (COT) templates accordingly. A comprehensive decision-making mechanism is also proposed to maximize model accuracy. The efficacy of OlaGPT has been stringently evaluated on multiple reasoning datasets, and the experimental outcomes reveal that OlaGPT surpasses state-of-the-art benchmarks, demonstrating its superior performance. Our implementation of OlaGPT is available on GitHub: \url{https://github.com/oladata-team/OlaGPT}.
Tenrec: A Large-scale Multipurpose Benchmark Dataset for Recommender Systems
Oct 20, 2022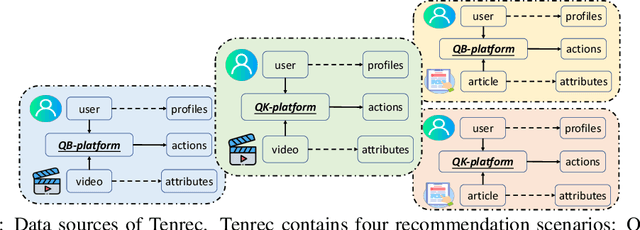
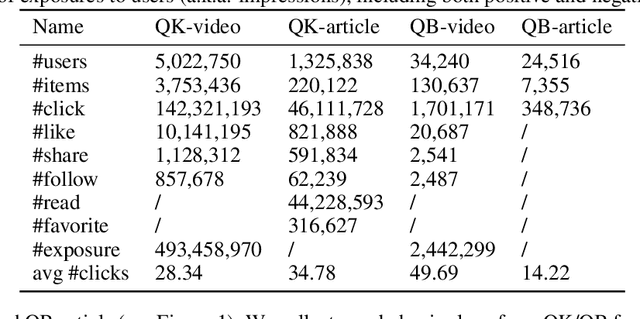
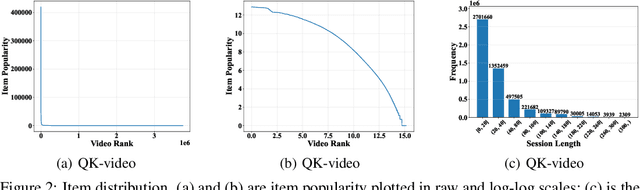

Existing benchmark datasets for recommender systems (RS) either are created at a small scale or involve very limited forms of user feedback. RS models evaluated on such datasets often lack practical values for large-scale real-world applications. In this paper, we describe Tenrec, a novel and publicly available data collection for RS that records various user feedback from four different recommendation scenarios. To be specific, Tenrec has the following five characteristics: (1) it is large-scale, containing around 5 million users and 140 million interactions; (2) it has not only positive user feedback, but also true negative feedback (vs. one-class recommendation); (3) it contains overlapped users and items across four different scenarios; (4) it contains various types of user positive feedback, in forms of clicks, likes, shares, and follows, etc; (5) it contains additional features beyond the user IDs and item IDs. We verify Tenrec on ten diverse recommendation tasks by running several classical baseline models per task. Tenrec has the potential to become a useful benchmark dataset for a majority of popular recommendation tasks.
TransRec: Learning Transferable Recommendation from Mixture-of-Modality Feedback
Jun 13, 2022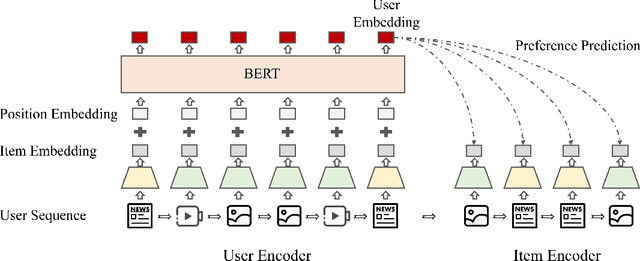
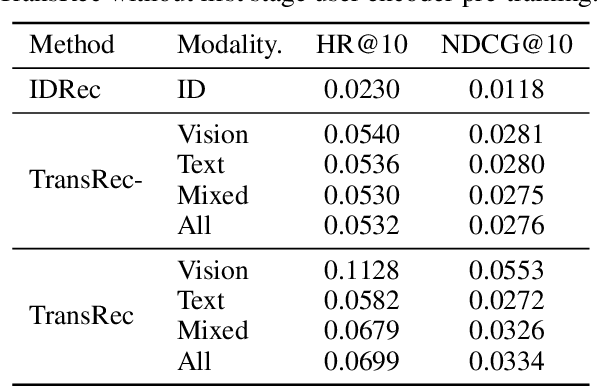
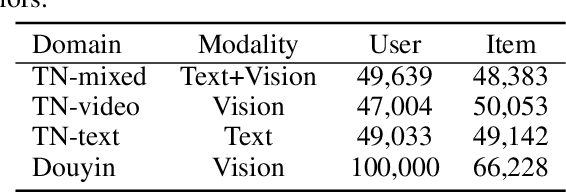
Learning big models and then transfer has become the de facto practice in computer vision (CV) and natural language processing (NLP). However, such unified paradigm is uncommon for recommender systems (RS). A critical issue that hampers this is that standard recommendation models are built on unshareable identity data, where both users and their interacted items are represented by unique IDs. In this paper, we study a novel scenario where user's interaction feedback involves mixture-of-modality (MoM) items. We present TransRec, a straightforward modification done on the popular ID-based RS framework. TransRec directly learns from MoM feedback in an end-to-end manner, and thus enables effective transfer learning under various scenarios without relying on overlapped users or items. We empirically study the transferring ability of TransRec across four different real-world recommendation settings. Besides, we study its effects by scaling the size of source and target data. Our results suggest that learning recommenders from MoM feedback provides a promising way to realize universal recommender systems. Our code and datasets will be made available.
RecGURU: Adversarial Learning of Generalized User Representations for Cross-Domain Recommendation
Nov 19, 2021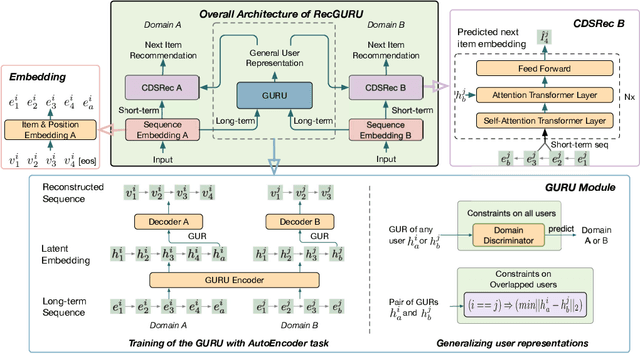
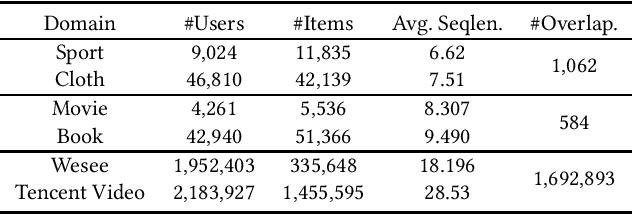
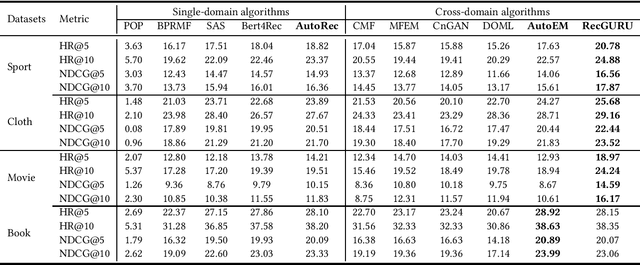
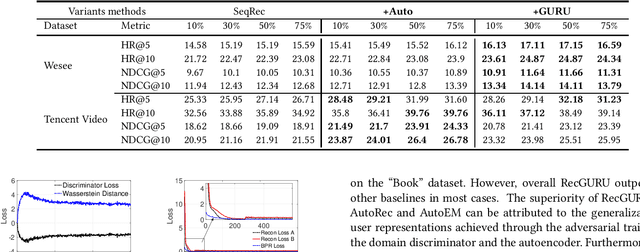
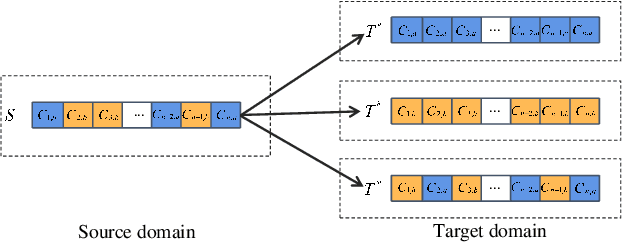
Cross-domain recommendation can help alleviate the data sparsity issue in traditional sequential recommender systems. In this paper, we propose the RecGURU algorithm framework to generate a Generalized User Representation (GUR) incorporating user information across domains in sequential recommendation, even when there is minimum or no common users in the two domains. We propose a self-attentive autoencoder to derive latent user representations, and a domain discriminator, which aims to predict the origin domain of a generated latent representation. We propose a novel adversarial learning method to train the two modules to unify user embeddings generated from different domains into a single global GUR for each user. The learned GUR captures the overall preferences and characteristics of a user and thus can be used to augment the behavior data and improve recommendations in any single domain in which the user is involved. Extensive experiments have been conducted on two public cross-domain recommendation datasets as well as a large dataset collected from real-world applications. The results demonstrate that RecGURU boosts performance and outperforms various state-of-the-art sequential recommendation and cross-domain recommendation methods. The collected data will be released to facilitate future research.