 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedSM: Robust Semantics-Guided Feature Mixup for Bias Reduction in Federated Learning with Long-Tail Data
Oct 31, 2025Federated Learning (FL) enables collaborative model training across decentralized clients without sharing private data. However, FL suffers from biased global models due to non-IID and long-tail data distributions. We propose \textbf{FedSM}, a novel client-centric framework that mitigates this bias through semantics-guided feature mixup and lightweight classifier retraining. FedSM uses a pretrained image-text-aligned model to compute category-level semantic relevance, guiding the category selection of local features to mix-up with global prototypes to generate class-consistent pseudo-features. These features correct classifier bias, especially when data are heavily skewed. To address the concern of potential domain shift between the pretrained model and the data, we propose probabilistic category selection, enhancing feature diversity to effectively mitigate biases. All computations are performed locally, requiring minimal server overhead. Extensive experiments on long-tail datasets with various imbalanced levels demonstrate that FedSM consistently outperforms state-of-the-art methods in accuracy, with high robustness to domain shift and computational efficiency.
Learning Speaker-Invariant Visual Features for Lipreading
Jun 09, 2025Lipreading is a challenging cross-modal task that aims to convert visual lip movements into spoken text. Existing lipreading methods often extract visual features that include speaker-specific lip attributes (e.g., shape, color, texture), which introduce spurious correlations between vision and text. These correlations lead to suboptimal lipreading accuracy and restrict model generalization. To address this challenge, we introduce SIFLip, a speaker-invariant visual feature learning framework that disentangles speaker-specific attributes using two complementary disentanglement modules (Implicit Disentanglement and Explicit Disentanglement) to improve generalization. Specifically, since different speakers exhibit semantic consistency between lip movements and phonetic text when pronouncing the same words, our implicit disentanglement module leverages stable text embeddings as supervisory signals to learn common visual representations across speakers, implicitly decoupling speaker-specific features. Additionally, we design a speaker recognition sub-task within the main lipreading pipeline to filter speaker-specific features, then further explicitly disentangle these personalized visual features from the backbone network via gradient reversal. Experimental results demonstrate that SIFLip significantly enhances generalization performance across multiple public datasets. Experimental results demonstrate that SIFLip significantly improves generalization performance across multiple public datasets, outperforming state-of-the-art methods.
Blend the Separated: Mixture of Synergistic Experts for Data-Scarcity Drug-Target Interaction Prediction
Mar 20, 2025Drug-target interaction prediction (DTI) is essential in various applications including drug discovery and clinical application. There are two perspectives of input data widely used in DTI prediction: Intrinsic data represents how drugs or targets are constructed, and extrinsic data represents how drugs or targets are related to other biological entities. However, any of the two perspectives of input data can be scarce for some drugs or targets, especially for those unpopular or newly discovered. Furthermore, ground-truth labels for specific interaction types can also be scarce. Therefore, we propose the first method to tackle DTI prediction under input data and/or label scarcity. To make our model functional when only one perspective of input data is available, we design two separate experts to process intrinsic and extrinsic data respectively and fuse them adaptively according to different samples. Furthermore, to make the two perspectives complement each other and remedy label scarcity, two experts synergize with each other in a mutually supervised way to exploit the enormous unlabeled data. Extensive experiments on 3 real-world datasets under different extents of input data scarcity and/or label scarcity demonstrate our model outperforms states of the art significantly and steadily, with a maximum improvement of 53.53%. We also test our model without any data scarcity and it still outperforms current methods.
HeTGB: A Comprehensive Benchmark for Heterophilic Text-Attributed Graphs
Mar 05, 2025Graph neural networks (GNNs) have demonstrated success in modeling relational data primarily under the assumption of homophily. However, many real-world graphs exhibit heterophily, where linked nodes belong to different categories or possess diverse attributes. Additionally, nodes in many domains are associated with textual descriptions, forming heterophilic text-attributed graphs (TAGs). Despite their significance, the study of heterophilic TAGs remains underexplored due to the lack of comprehensive benchmarks. To address this gap, we introduce the Heterophilic Text-attributed Graph Benchmark (HeTGB), a novel benchmark comprising five real-world heterophilic graph datasets from diverse domains, with nodes enriched by extensive textual descriptions. HeTGB enables systematic evaluation of GNNs, pre-trained language models (PLMs) and co-training methods on the node classification task. Through extensive benchmarking experiments, we showcase the utility of text attributes in heterophilic graphs, analyze the challenges posed by heterophilic TAGs and the limitations of existing models, and provide insights into the interplay between graph structures and textual attributes. We have publicly released HeTGB with baseline implementations to facilitate further research in this field.
Unifying Structured Data as Graph for Data-to-Text Pre-Training
Jan 02, 2024Data-to-text (D2T) generation aims to transform structured data into natural language text. Data-to-text pre-training has proved to be powerful in enhancing D2T generation and yields impressive performances. However, previous pre-training methods either oversimplified structured data into a sequence without considering input structures or designed training objectives tailored for a specific data structure (e.g., table or knowledge graph). In this paper, we unify different types of structured data (i.e., table, key-value data, knowledge graph) into the graph format and cast different data-to-text generation tasks as graph-to-text generation. To effectively exploit the structural information of the input graph, we propose a structure-enhanced pre-training method for D2T generation by designing a structure-enhanced Transformer. Concretely, we devise a position matrix for the Transformer, encoding relative positional information of connected nodes in the input graph. In addition, we propose a new attention matrix to incorporate graph structures into the original Transformer by taking the available explicit connectivity structure into account. Extensive experiments on six benchmark datasets show the effectiveness of our model. Our source codes are available at https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/unid2t.
Tenrec: A Large-scale Multipurpose Benchmark Dataset for Recommender Systems
Oct 20, 2022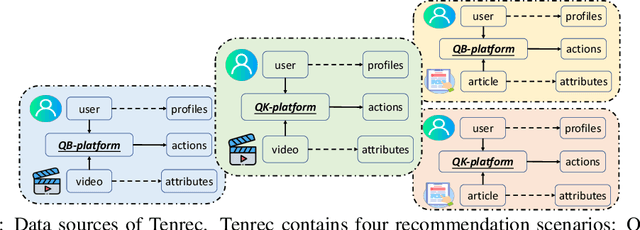
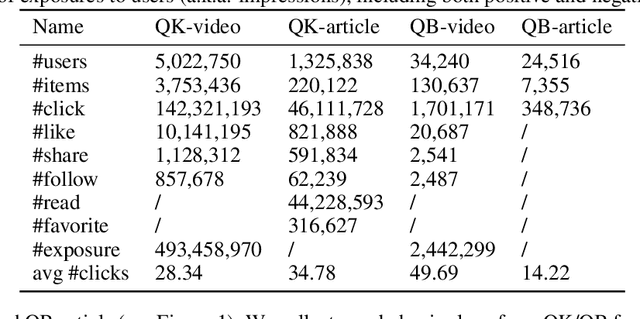
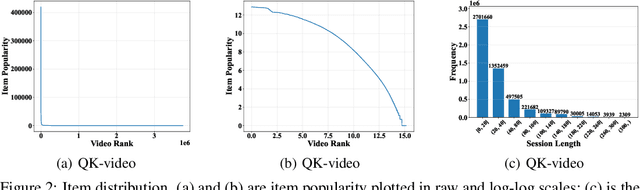

Existing benchmark datasets for recommender systems (RS) either are created at a small scale or involve very limited forms of user feedback. RS models evaluated on such datasets often lack practical values for large-scale real-world applications. In this paper, we describe Tenrec, a novel and publicly available data collection for RS that records various user feedback from four different recommendation scenarios. To be specific, Tenrec has the following five characteristics: (1) it is large-scale, containing around 5 million users and 140 million interactions; (2) it has not only positive user feedback, but also true negative feedback (vs. one-class recommendation); (3) it contains overlapped users and items across four different scenarios; (4) it contains various types of user positive feedback, in forms of clicks, likes, shares, and follows, etc; (5) it contains additional features beyond the user IDs and item IDs. We verify Tenrec on ten diverse recommendation tasks by running several classical baseline models per task. Tenrec has the potential to become a useful benchmark dataset for a majority of popular recommendation tasks.
MEGCF: Multimodal Entity Graph Collaborative Filtering for Personalized Recommendation
Oct 14, 2022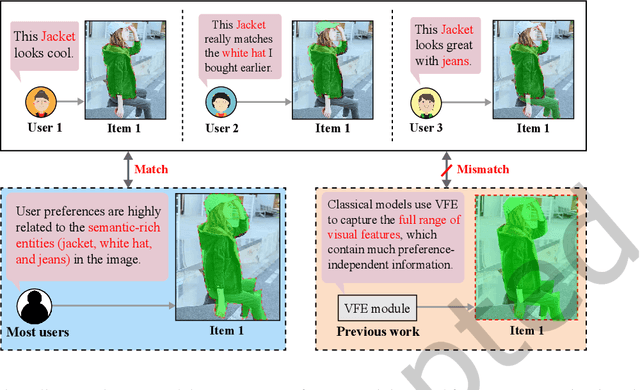
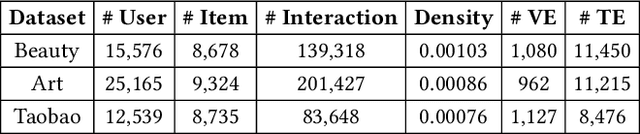
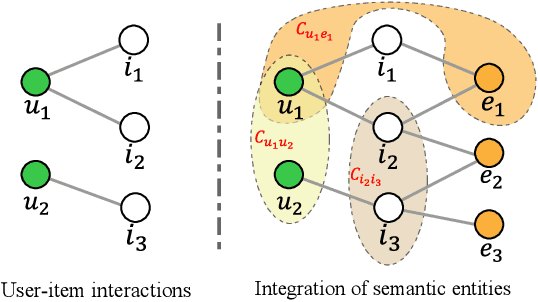
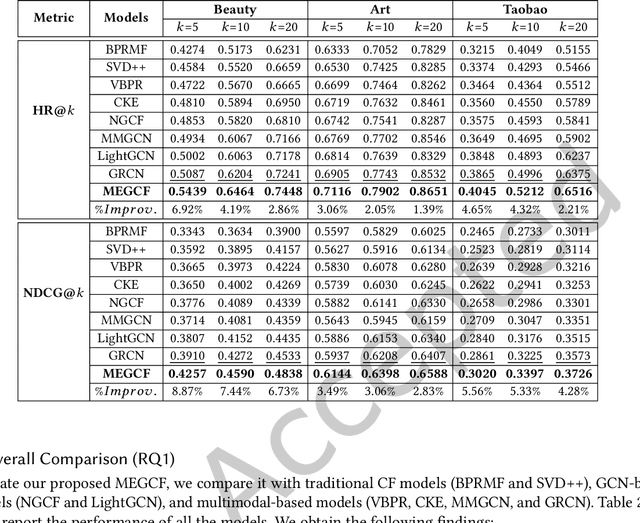
In most E-commerce platforms, whether the displayed items trigger the user's interest largely depends on their most eye-catching multimodal content. Consequently, increasing efforts focus on modeling multimodal user preference, and the pressing paradigm is to incorporate complete multimodal deep features of the items into the recommendation module. However, the existing studies ignore the mismatch problem between multimodal feature extraction (MFE) and user interest modeling (UIM). That is, MFE and UIM have different emphases. Specifically, MFE is migrated from and adapted to upstream tasks such as image classification. In addition, it is mainly a content-oriented and non-personalized process, while UIM, with its greater focus on understanding user interaction, is essentially a user-oriented and personalized process. Therefore, the direct incorporation of MFE into UIM for purely user-oriented tasks, tends to introduce a large number of preference-independent multimodal noise and contaminate the embedding representations in UIM. This paper aims at solving the mismatch problem between MFE and UIM, so as to generate high-quality embedding representations and better model multimodal user preferences. Towards this end, we develop a novel model, MEGCF. The UIM of the proposed model captures the semantic correlation between interactions and the features obtained from MFE, thus making a better match between MFE and UIM. More precisely, semantic-rich entities are first extracted from the multimodal data, since they are more relevant to user preferences than other multimodal information. These entities are then integrated into the user-item interaction graph. Afterwards, a symmetric linear Graph Convolution Network (GCN) module is constructed to perform message propagation over the graph, in order to capture both high-order semantic correlation and collaborative filtering signals.