 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeU-Fold: Dynamic Intent-Aware Context Folding for User-Centric Agents
Jan 26, 2026Large language model (LLM)-based agents have been successfully deployed in many tool-augmented settings, but their scalability is fundamentally constrained by context length. Existing context-folding methods mitigate this issue by summarizing past interactions, yet they are typically designed for single-query or single-intent scenarios. In more realistic user-centric dialogues, we identify two major failure modes: (i) they irreversibly discard fine-grained constraints and intermediate facts that are crucial for later decisions, and (ii) their summaries fail to track evolving user intent, leading to omissions and erroneous actions. To address these limitations, we propose U-Fold, a dynamic context-folding framework tailored to user-centric tasks. U-Fold retains the full user--agent dialogue and tool-call history but, at each turn, uses two core components to produce an intent-aware, evolving dialogue summary and a compact, task-relevant tool log. Extensive experiments on $τ$-bench, $τ^2$-bench, VitaBench, and harder context-inflated settings show that U-Fold consistently outperforms ReAct (achieving a 71.4% win rate in long-context settings) and prior folding baselines (with improvements of up to 27.0%), particularly on long, noisy, multi-turn tasks. Our study demonstrates that U-Fold is a promising step toward transferring context-management techniques from single-query benchmarks to realistic user-centric applications.
VARD: Efficient and Dense Fine-Tuning for Diffusion Models with Value-based RL
May 21, 2025



Diffusion models have emerged as powerful generative tools across various domains, yet tailoring pre-trained models to exhibit specific desirable properties remains challenging. While reinforcement learning (RL) offers a promising solution,current methods struggle to simultaneously achieve stable, efficient fine-tuning and support non-differentiable rewards. Furthermore, their reliance on sparse rewards provides inadequate supervision during intermediate steps, often resulting in suboptimal generation quality. To address these limitations, dense and differentiable signals are required throughout the diffusion process. Hence, we propose VAlue-based Reinforced Diffusion (VARD): a novel approach that first learns a value function predicting expection of rewards from intermediate states, and subsequently uses this value function with KL regularization to provide dense supervision throughout the generation process. Our method maintains proximity to the pretrained model while enabling effective and stable training via backpropagation. Experimental results demonstrate that our approach facilitates better trajectory guidance, improves training efficiency and extends the applicability of RL to diffusion models optimized for complex, non-differentiable reward functions.
LeanVAE: An Ultra-Efficient Reconstruction VAE for Video Diffusion Models
Mar 18, 2025



Recent advances in Latent Video Diffusion Models (LVDMs) have revolutionized video generation by leveraging Video Variational Autoencoders (Video VAEs) to compress intricate video data into a compact latent space. However, as LVDM training scales, the computational overhead of Video VAEs becomes a critical bottleneck, particularly for encoding high-resolution videos. To address this, we propose LeanVAE, a novel and ultra-efficient Video VAE framework that introduces two key innovations: (1) a lightweight architecture based on a Neighborhood-Aware Feedforward (NAF) module and non-overlapping patch operations, drastically reducing computational cost, and (2) the integration of wavelet transforms and compressed sensing techniques to enhance reconstruction quality. Extensive experiments validate LeanVAE's superiority in video reconstruction and generation, particularly in enhancing efficiency over existing Video VAEs. Our model offers up to 50x fewer FLOPs and 44x faster inference speed while maintaining competitive reconstruction quality, providing insights for scalable, efficient video generation. Our models and code are available at https://github.com/westlake-repl/LeanVAE
Offline Trajectory Generalization for Offline Reinforcement Learning
Apr 16, 2024Offline reinforcement learning (RL) aims to learn policies from static datasets of previously collected trajectories. Existing methods for offline RL either constrain the learned policy to the support of offline data or utilize model-based virtual environments to generate simulated rollouts. However, these methods suffer from (i) poor generalization to unseen states; and (ii) trivial improvement from low-qualified rollout simulation. In this paper, we propose offline trajectory generalization through world transformers for offline reinforcement learning (OTTO). Specifically, we use casual Transformers, a.k.a. World Transformers, to predict state dynamics and the immediate reward. Then we propose four strategies to use World Transformers to generate high-rewarded trajectory simulation by perturbing the offline data. Finally, we jointly use offline data with simulated data to train an offline RL algorithm. OTTO serves as a plug-in module and can be integrated with existing offline RL methods to enhance them with better generalization capability of transformers and high-rewarded data augmentation. Conducting extensive experiments on D4RL benchmark datasets, we verify that OTTO significantly outperforms state-of-the-art offline RL methods.
Breaking the Length Barrier: LLM-Enhanced CTR Prediction in Long Textual User Behaviors
Mar 28, 2024With the rise of large language models (LLMs), recent works have leveraged LLMs to improve the performance of click-through rate (CTR) prediction. However, we argue that a critical obstacle remains in deploying LLMs for practical use: the efficiency of LLMs when processing long textual user behaviors. As user sequences grow longer, the current efficiency of LLMs is inadequate for training on billions of users and items. To break through the efficiency barrier of LLMs, we propose Behavior Aggregated Hierarchical Encoding (BAHE) to enhance the efficiency of LLM-based CTR modeling. Specifically, BAHE proposes a novel hierarchical architecture that decouples the encoding of user behaviors from inter-behavior interactions. Firstly, to prevent computational redundancy from repeated encoding of identical user behaviors, BAHE employs the LLM's pre-trained shallow layers to extract embeddings of the most granular, atomic user behaviors from extensive user sequences and stores them in the offline database. Subsequently, the deeper, trainable layers of the LLM facilitate intricate inter-behavior interactions, thereby generating comprehensive user embeddings. This separation allows the learning of high-level user representations to be independent of low-level behavior encoding, significantly reducing computational complexity. Finally, these refined user embeddings, in conjunction with correspondingly processed item embeddings, are incorporated into the CTR model to compute the CTR scores. Extensive experimental results show that BAHE reduces training time and memory by five times for CTR models using LLMs, especially with longer user sequences. BAHE has been deployed in a real-world system, allowing for daily updates of 50 million CTR data on 8 A100 GPUs, making LLMs practical for industrial CTR prediction.
Empowering Sequential Recommendation from Collaborative Signals and Semantic Relatedness
Mar 12, 2024Sequential recommender systems (SRS) could capture dynamic user preferences by modeling historical behaviors ordered in time. Despite effectiveness, focusing only on the \textit{collaborative signals} from behaviors does not fully grasp user interests. It is also significant to model the \textit{semantic relatedness} reflected in content features, e.g., images and text. Towards that end, in this paper, we aim to enhance the SRS tasks by effectively unifying collaborative signals and semantic relatedness together. Notably, we empirically point out that it is nontrivial to achieve such a goal due to semantic gap issues. Thus, we propose an end-to-end two-stream architecture for sequential recommendation, named TSSR, to learn user preferences from ID-based and content-based sequence. Specifically, we first present novel hierarchical contrasting module, including coarse user-grained and fine item-grained terms, to align the representations of inter-modality. Furthermore, we also design a two-stream architecture to learn the dependence of intra-modality sequence and the complex interactions of inter-modality sequence, which can yield more expressive capacity in understanding user interests. We conduct extensive experiments on five public datasets. The experimental results show that the TSSR could yield superior performance than competitive baselines. We also make our experimental codes publicly available at https://anonymous.4open.science/r/TSSR-2A27/.
Multi-Modality is All You Need for Transferable Recommender Systems
Dec 18, 2023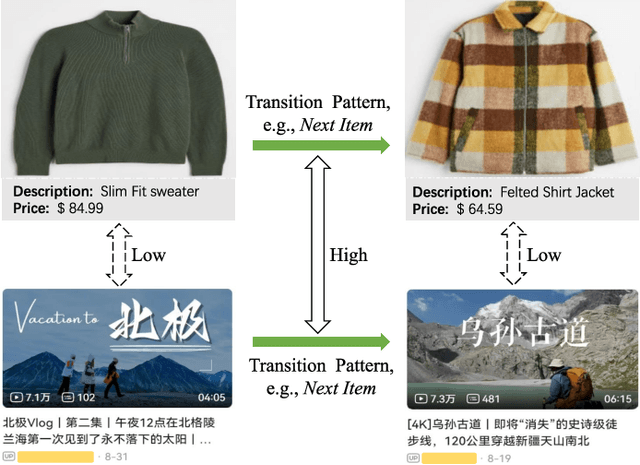
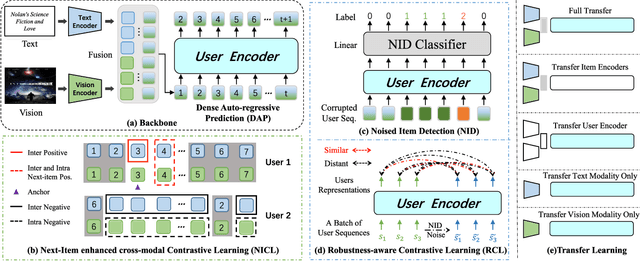
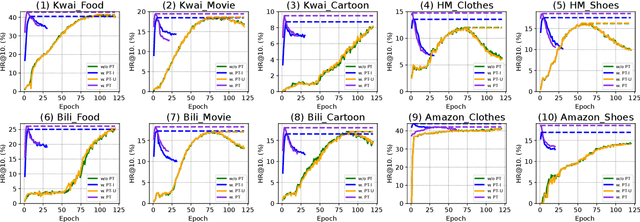
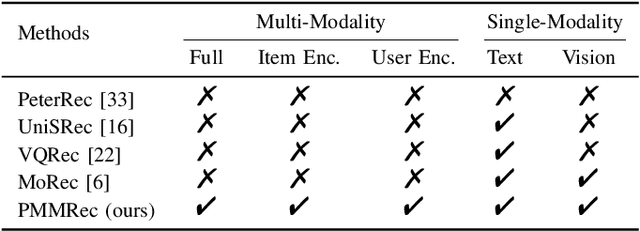
ID-based Recommender Systems (RecSys), where each item is assigned a unique identifier and subsequently converted into an embedding vector, have dominated the designing of RecSys. Though prevalent, such ID-based paradigm is not suitable for developing transferable RecSys and is also susceptible to the cold-start issue. In this paper, we unleash the boundaries of the ID-based paradigm and propose a Pure Multi-Modality based Recommender system (PMMRec), which relies solely on the multi-modal contents of the items (e.g., texts and images) and learns transition patterns general enough to transfer across domains and platforms. Specifically, we design a plug-and-play framework architecture consisting of multi-modal item encoders, a fusion module, and a user encoder. To align the cross-modal item representations, we propose a novel next-item enhanced cross-modal contrastive learning objective, which is equipped with both inter- and intra-modality negative samples and explicitly incorporates the transition patterns of user behaviors into the item encoders. To ensure the robustness of user representations, we propose a novel noised item detection objective and a robustness-aware contrastive learning objective, which work together to denoise user sequences in a self-supervised manner. PMMRec is designed to be loosely coupled, so after being pre-trained on the source data, each component can be transferred alone, or in conjunction with other components, allowing PMMRec to achieve versatility under both multi-modality and single-modality transfer learning settings. Extensive experiments on 4 sources and 10 target datasets demonstrate that PMMRec surpasses the state-of-the-art recommenders in both recommendation performance and transferability. Our code and dataset is available at: https://github.com/ICDE24/PMMRec.
Hypergraph Node Representation Learning with One-Stage Message Passing
Dec 01, 2023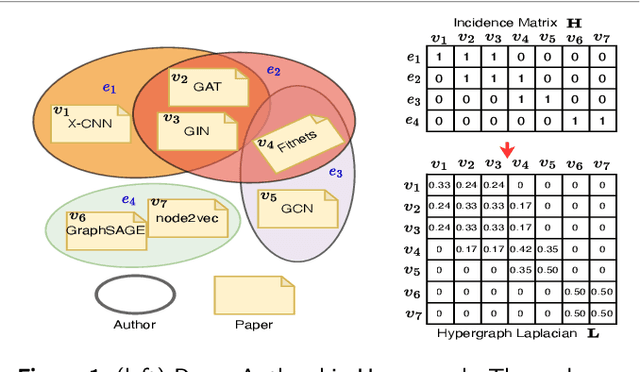
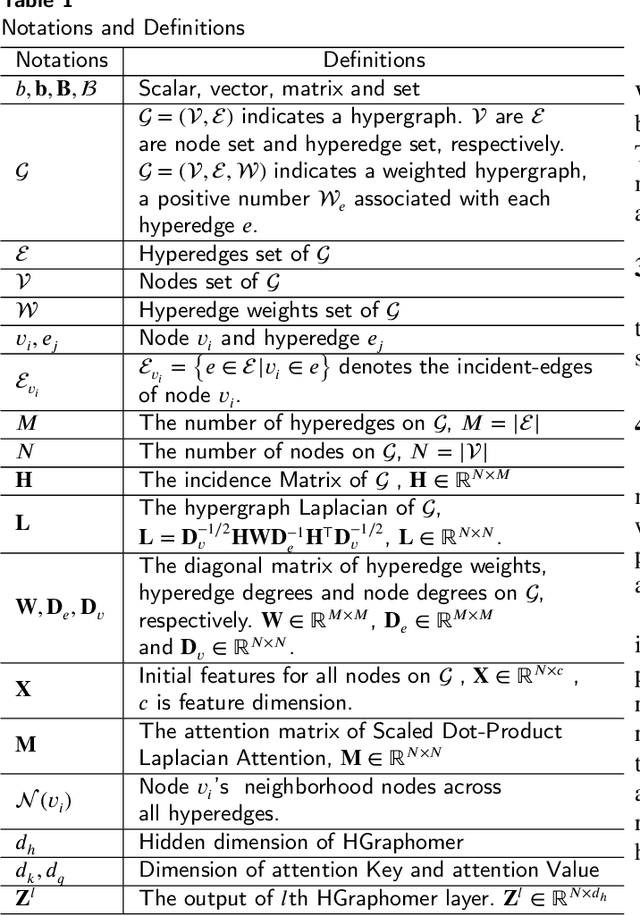
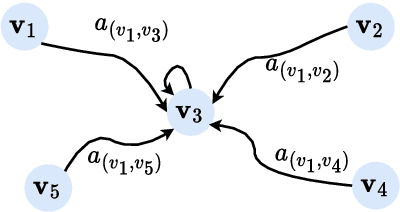
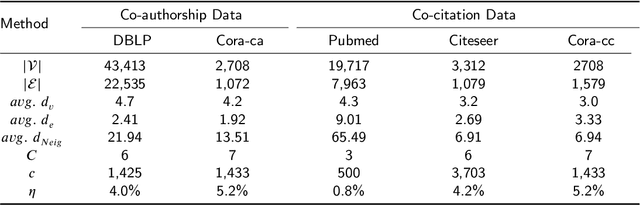
Hypergraphs as an expressive and general structure have attracted considerable attention from various research domains. Most existing hypergraph node representation learning techniques are based on graph neural networks, and thus adopt the two-stage message passing paradigm (i.e. node -> hyperedge -> node). This paradigm only focuses on local information propagation and does not effectively take into account global information, resulting in less optimal representations. Our theoretical analysis of representative two-stage message passing methods shows that, mathematically, they model different ways of local message passing through hyperedges, and can be unified into one-stage message passing (i.e. node -> node). However, they still only model local information. Motivated by this theoretical analysis, we propose a novel one-stage message passing paradigm to model both global and local information propagation for hypergraphs. We integrate this paradigm into HGraphormer, a Transformer-based framework for hypergraph node representation learning. HGraphormer injects the hypergraph structure information (local information) into Transformers (global information) by combining the attention matrix and hypergraph Laplacian. Extensive experiments demonstrate that HGraphormer outperforms recent hypergraph learning methods on five representative benchmark datasets on the semi-supervised hypernode classification task, setting new state-of-the-art performance, with accuracy improvements between 2.52% and 6.70%. Our code and datasets are available.
FMMRec: Fairness-aware Multimodal Recommendation
Oct 26, 2023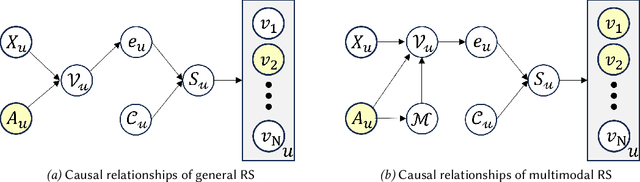

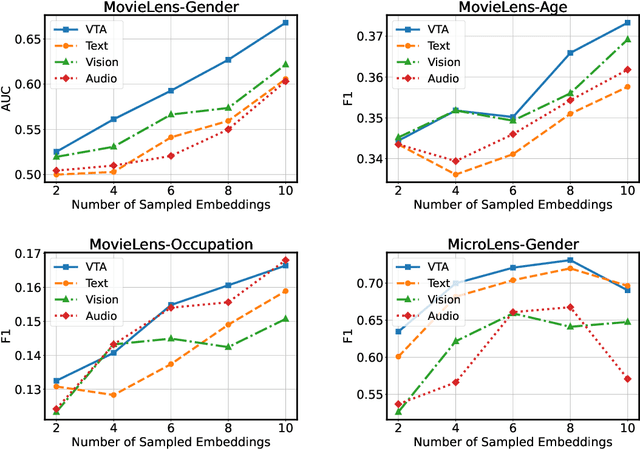
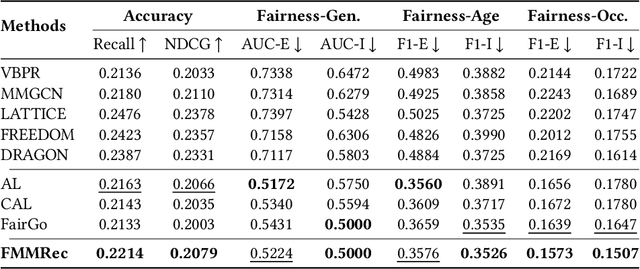
Recently, multimodal recommendations have gained increasing attention for effectively addressing the data sparsity problem by incorporating modality-based representations. Although multimodal recommendations excel in accuracy, the introduction of different modalities (e.g., images, text, and audio) may expose more users' sensitive information (e.g., gender and age) to recommender systems, resulting in potentially more serious unfairness issues. Despite many efforts on fairness, existing fairness-aware methods are either incompatible with multimodal scenarios, or lead to suboptimal fairness performance due to neglecting sensitive information of multimodal content. To achieve counterfactual fairness in multimodal recommendations, we propose a novel fairness-aware multimodal recommendation approach (dubbed as FMMRec) to disentangle the sensitive and non-sensitive information from modal representations and leverage the disentangled modal representations to guide fairer representation learning. Specifically, we first disentangle biased and filtered modal representations by maximizing and minimizing their sensitive attribute prediction ability respectively. With the disentangled modal representations, we mine the modality-based unfair and fair (corresponding to biased and filtered) user-user structures for enhancing explicit user representation with the biased and filtered neighbors from the corresponding structures, followed by adversarially filtering out sensitive information. Experiments on two real-world public datasets demonstrate the superiority of our FMMRec relative to the state-of-the-art baselines. Our source code is available at https://anonymous.4open.science/r/FMMRec.
A Content-Driven Micro-Video Recommendation Dataset at Scale
Sep 27, 2023



Micro-videos have recently gained immense popularity, sparking critical research in micro-video recommendation with significant implications for the entertainment, advertising, and e-commerce industries. However, the lack of large-scale public micro-video datasets poses a major challenge for developing effective recommender systems. To address this challenge, we introduce a very large micro-video recommendation dataset, named "MicroLens", consisting of one billion user-item interaction behaviors, 34 million users, and one million micro-videos. This dataset also contains various raw modality information about videos, including titles, cover images, audio, and full-length videos. MicroLens serves as a benchmark for content-driven micro-video recommendation, enabling researchers to utilize various modalities of video information for recommendation, rather than relying solely on item IDs or off-the-shelf video features extracted from a pre-trained network. Our benchmarking of multiple recommender models and video encoders on MicroLens has yielded valuable insights into the performance of micro-video recommendation. We believe that this dataset will not only benefit the recommender system community but also promote the development of the video understanding field. Our datasets and code are available at https://github.com/westlake-repl/MicroLens.