 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeet Dynamic Individual Preferences: Resolving Conflicting Human Value with Paired Fine-Tuning
Apr 14, 2026Recent advances in large language models (LLMs) have significantly improved the alignment of models with general human preferences. However, a major challenge remains in adapting LLMs to individual preferences, which are not only diverse but also dynamic. In this paper, we introduce a novel framework, Preference-Paired Fine-Tuning (PFT), designed to align models with contradictory and evolving individual preferences. We present a new dataset, Value Conflict Dilemma (VCD), which includes scenarios that involve conflicting human preferences, facilitating the evaluation of our approach. Our experiments demonstrate that PFT outperforms single-preference training methods, achieving up to 96.6% accuracy in multi-choice classification tasks and the highest open-ended generation score of 8.69. PFT also shows significant improvements over DPO, SFT and some traditional training methods, especially when handling conflicting preferences. Additionally, with limited user history data, models can inferring preference vector rapidly, achieving a 44.76% improvement in user-specific preference alignment in comparison to single-preference models.
Errors in AI-Assisted Retrieval of Medical Literature: A Comparative Study
Mar 21, 2026Large language models (LLMs) assisted literature retrieval may lead to erroneous references, but these errors have not been rigorously quantified. Therefore, we quantitatively assess errors in reference retrieval of widely used free-version LLM platforms and identify the factors associated with retrieval errors. We evaluated 2,000 references retrieved by 5 LLMs (Grok-2, ChatGPT GPT-4.1, Google Gemini Flash 2.5, Perplexity AI, and DeepSeek GPT-4) for 40 randomly-selected original articles (10 per journal) published Jan. 2024 to July 2025 from British Medical Journal (BMJ), Journal of the American Medical Association, and The New England Journal of Medicine (NEJM). Primary outcomes were a multimetric score ratio combining validity of digital object identifier, PubMed ID, Google-Scholar link, and relevance; and complete miss rate (proportion of references failing all applicable metrics). Multivariable regression was used to examine independent associations. LLM platforms completely failed to retrieve correct reference data 47.8% of the time. The average score ratio of the 5 LLM platforms was 0.29 (standard deviation, 0.35; range, 0-1.25), with a higher score ratio indicating a higher accuracy in retrieving relevant references and correct bibliographic data. The highest and lowest accuracies were achieved by Grok (0.57) and Genimi (0.11), respectively. Compared with BMJ, NEJM articles had lower score ratios and higher complete miss rates. Multivariable analysis shows LLM platforms and journals were independently associated with score ratios and complete miss rate, respectively. We show modest overall performance of LLMs and significant variability in retrieval accuracy across platforms and journals. LLM platforms and journals are associated with LLM's performance in retrieving medical literature. Bibliographic data should be carefully reviewed when using LLM-assisted literature retrieval.
RAGRouter-Bench: A Dataset and Benchmark for Adaptive RAG Routing
Jan 30, 2026Retrieval-Augmented Generation (RAG) has become a core paradigm for grounding large language models with external knowledge. Despite extensive efforts exploring diverse retrieval strategies, existing studies predominantly focus on query-side complexity or isolated method improvements, lacking a systematic understanding of how RAG paradigms behave across different query-corpus contexts and effectiveness-efficiency trade-offs. In this work, we introduce RAGRouter-Bench, the first dataset and benchmark designed for adaptive RAG routing. RAGRouter-Bench revisits retrieval from a query-corpus compatibility perspective and standardizes five representative RAG paradigms for systematic evaluation across 7,727 queries and 21,460 documents spanning diverse domains. The benchmark incorporates three canonical query types together with fine-grained semantic and structural corpus metrics, as well as a unified evaluation for both generation quality and resource consumption. Experiments with DeepSeek-V3 and LLaMA-3.1-8B demonstrate that no single RAG paradigm is universally optimal, that paradigm applicability is strongly shaped by query-corpus interactions, and that increased advanced mechanism does not necessarily yield better effectiveness-efficiency trade-offs. These findings underscore the necessity of routing-aware evaluation and establish a foundation for adaptive, interpretable, and generalizable next-generation RAG systems.
MemRec: Collaborative Memory-Augmented Agentic Recommender System
Jan 13, 2026The evolution of recommender systems has shifted preference storage from rating matrices and dense embeddings to semantic memory in the agentic era. Yet existing agents rely on isolated memory, overlooking crucial collaborative signals. Bridging this gap is hindered by the dual challenges of distilling vast graph contexts without overwhelming reasoning agents with cognitive load, and evolving the collaborative memory efficiently without incurring prohibitive computational costs. To address this, we propose MemRec, a framework that architecturally decouples reasoning from memory management to enable efficient collaborative augmentation. MemRec introduces a dedicated, cost-effective LM_Mem to manage a dynamic collaborative memory graph, serving synthesized, high-signal context to a downstream LLM_Rec. The framework operates via a practical pipeline featuring efficient retrieval and cost-effective asynchronous graph propagation that evolves memory in the background. Extensive experiments on four benchmarks demonstrate that MemRec achieves state-of-the-art performance. Furthermore, architectural analysis confirms its flexibility, establishing a new Pareto frontier that balances reasoning quality, cost, and privacy through support for diverse deployments, including local open-source models. Code:https://github.com/rutgerswiselab/memrec and Homepage: https://memrec.weixinchen.com
DeSocial: Blockchain-based Decentralized Social Networks
May 28, 2025Web 2.0 social platforms are inherently centralized, with user data and algorithmic decisions controlled by the platform. However, users can only passively receive social predictions without being able to choose the underlying algorithm, which limits personalization. Fortunately, with the emergence of blockchain, users are allowed to choose algorithms that are tailored to their local situation, improving prediction results in a personalized way. In a blockchain environment, each user possesses its own model to perform the social prediction, capturing different perspectives on social interactions. In our work, we propose DeSocial, a decentralized social network learning framework deployed on an Ethereum (ETH) local development chain that integrates distributed data storage, node-level consensus, and user-driven model selection through Ganache. In the first stage, each user leverages DeSocial to evaluate multiple backbone models on their local subgraph. DeSocial coordinates the execution and returns model-wise prediction results, enabling the user to select the most suitable backbone for personalized social prediction. Then, DeSocial uniformly selects several validation nodes that possess the algorithm specified by each user, and aggregates the prediction results by majority voting, to prevent errors caused by any single model's misjudgment. Extensive experiments show that DeSocial has an evident improvement compared to the five classical centralized social network learning models, promoting user empowerment in blockchain-based decentralized social networks, showing the importance of multi-node validation and personalized algorithm selection based on blockchain. Our implementation is available at: https://github.com/agiresearch/DeSocial.
LiteCUA: Computer as MCP Server for Computer-Use Agent on AIOS
May 24, 2025We present AIOS 1.0, a novel platform designed to advance computer-use agent (CUA) capabilities through environmental contextualization. While existing approaches primarily focus on building more powerful agent frameworks or enhancing agent models, we identify a fundamental limitation: the semantic disconnect between how language models understand the world and how computer interfaces are structured. AIOS 1.0 addresses this challenge by transforming computers into contextual environments that language models can natively comprehend, implementing a Model Context Protocol (MCP) server architecture to abstract computer states and actions. This approach effectively decouples interface complexity from decision complexity, enabling agents to reason more effectively about computing environments. To demonstrate our platform's effectiveness, we introduce LiteCUA, a lightweight computer-use agent built on AIOS 1.0 that achieves a 14.66% success rate on the OSWorld benchmark, outperforming several specialized agent frameworks despite its simple architecture. Our results suggest that contextualizing computer environments for language models represents a promising direction for developing more capable computer-use agents and advancing toward AI that can interact with digital systems. The source code of LiteCUA is available at https://github.com/agiresearch/LiteCUA, and it is also integrated into the AIOS main branch as part of AIOS at https://github.com/agiresearch/AIOS.
Know the Ropes: A Heuristic Strategy for LLM-based Multi-Agent System Design
May 22, 2025Single-agent LLMs hit hard limits--finite context, role overload, and brittle domain transfer. Conventional multi-agent fixes soften those edges yet expose fresh pains: ill-posed decompositions, fuzzy contracts, and verification overhead that blunts the gains. We therefore present Know-The-Ropes (KtR), a framework that converts domain priors into an algorithmic blueprint hierarchy, in which tasks are recursively split into typed, controller-mediated subtasks, each solved zero-shot or with the lightest viable boost (e.g., chain-of-thought, micro-tune, self-check). Grounded in the No-Free-Lunch theorem, KtR trades the chase for a universal prompt for disciplined decomposition. On the Knapsack problem (3-8 items), three GPT-4o-mini agents raise accuracy from 3% zero-shot to 95% on size-5 instances after patching a single bottleneck agent. On the tougher Task-Assignment problem (6-15 jobs), a six-agent o3-mini blueprint hits 100% up to size 10 and 84% on sizes 13-15, versus 11% zero-shot. Algorithm-aware decomposition plus targeted augmentation thus turns modest models into reliable collaborators--no ever-larger monoliths required.
Invisible Prompts, Visible Threats: Malicious Font Injection in External Resources for Large Language Models
May 22, 2025Large Language Models (LLMs) are increasingly equipped with capabilities of real-time web search and integrated with protocols like Model Context Protocol (MCP). This extension could introduce new security vulnerabilities. We present a systematic investigation of LLM vulnerabilities to hidden adversarial prompts through malicious font injection in external resources like webpages, where attackers manipulate code-to-glyph mapping to inject deceptive content which are invisible to users. We evaluate two critical attack scenarios: (1) "malicious content relay" and (2) "sensitive data leakage" through MCP-enabled tools. Our experiments reveal that indirect prompts with injected malicious font can bypass LLM safety mechanisms through external resources, achieving varying success rates based on data sensitivity and prompt design. Our research underscores the urgent need for enhanced security measures in LLM deployments when processing external content.
SAE-SSV: Supervised Steering in Sparse Representation Spaces for Reliable Control of Language Models
May 22, 2025Large language models (LLMs) have demonstrated impressive capabilities in natural language understanding and generation, but controlling their behavior reliably remains challenging, especially in open-ended generation settings. This paper introduces a novel supervised steering approach that operates in sparse, interpretable representation spaces. We employ sparse autoencoders (SAEs)to obtain sparse latent representations that aim to disentangle semantic attributes from model activations. Then we train linear classifiers to identify a small subspace of task-relevant dimensions in latent representations. Finally, we learn supervised steering vectors constrained to this subspace, optimized to align with target behaviors. Experiments across sentiment, truthfulness, and politics polarity steering tasks with multiple LLMs demonstrate that our supervised steering vectors achieve higher success rates with minimal degradation in generation quality compared to existing methods. Further analysis reveals that a notably small subspace is sufficient for effective steering, enabling more targeted and interpretable interventions.
Planet as a Brain: Towards Internet of AgentSites based on AIOS Server
Apr 22, 2025
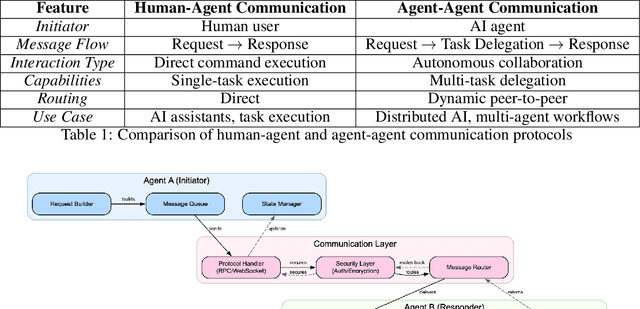
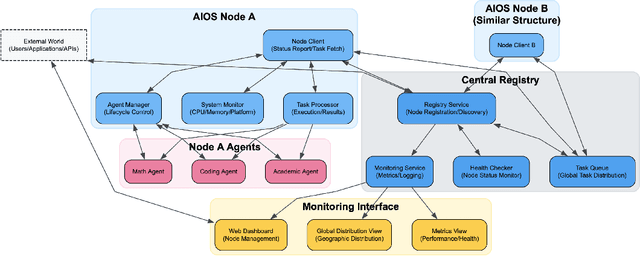
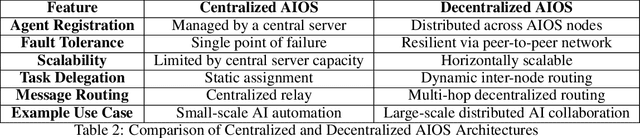
The internet is undergoing a historical transformation from the "Internet of Websites" to the "Internet of AgentSites." While traditional Websites served as the foundation for information hosting and dissemination, a new frontier is emerging where AgentSites serve as the hubs of the internet, where each AgentSite hosts one or more AI agents that receive tasks, address them, and deliver actionable solutions, marking a significant shift in the digital landscape and representing the next generation of online ecosystems. Under this vision, AIOS, the AI Agent Operating System, serves as the server for the development, deployment and execution of AI agents, which is a fundamental infrastructure for the Internet of Agentsites. In this paper, we introduce AIOS Server, a runtime framework to host agents and enable global-scale collaboration among decentralized agents. AIOS Server provides a communication protocol leveraging the Model Context Protocol (MCP) and JSON-RPC to enable agent-agent or human-agent interactions. Each AIOS node operates as a server to host and execute agents, while supporting peer-to-peer coordination without reliance on centralized orchestration. Based on AIOS Server, we further present the world's first practically deployed Internet of Agentsites (AIOS-IoA), including AgentHub for agent registration and discovery and AgentChat for interactive communication, at https://planet.aios.foundation. The agent discovery mechanism based on Distributed Hash Tables (DHT) and a Gossip protocol serves as the search engine for the internet of agentsites. This work provides a practical foundation for building the Internet of Agentsites-a new paradigm where autonomous agents become first-class citizens of the web. The implementation is available at https://github.com/agiresearch/AIOS.Server and will be integrated into the AIOS main branch at https://github.com/agiresearch/AIOS.