 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Latent Space: Foundation, Evolution, Mechanism, Ability, and Outlook
Apr 02, 2026Latent space is rapidly emerging as a native substrate for language-based models. While modern systems are still commonly understood through explicit token-level generation, an increasing body of work shows that many critical internal processes are more naturally carried out in continuous latent space than in human-readable verbal traces. This shift is driven by the structural limitations of explicit-space computation, including linguistic redundancy, discretization bottlenecks, sequential inefficiency, and semantic loss. This survey aims to provide a unified and up-to-date landscape of latent space in language-based models. We organize the survey into five sequential perspectives: Foundation, Evolution, Mechanism, Ability, and Outlook. We begin by delineating the scope of latent space, distinguishing it from explicit or verbal space and from the latent spaces commonly studied in generative visual models. We then trace the field's evolution from early exploratory efforts to the current large-scale expansion. To organize the technical landscape, we examine existing work through the complementary lenses of mechanism and ability. From the perspective of Mechanism, we identify four major lines of development: Architecture, Representation, Computation, and Optimization. From the perspective of Ability, we show how latent space supports a broad capability spectrum spanning Reasoning, Planning, Modeling, Perception, Memory, Collaboration, and Embodiment. Beyond consolidation, we discuss the key open challenges, and outline promising directions for future research. We hope this survey serves not only as a reference for existing work, but also as a foundation for understanding latent space as a general computational and systems paradigm for next-generation intelligence.
CoT2-Meta: Budgeted Metacognitive Control for Test-Time Reasoning
Mar 30, 2026Recent test-time reasoning methods improve performance by generating more candidate chains or searching over larger reasoning trees, but they typically lack explicit control over when to expand, what to prune, how to repair, and when to abstain. We introduce CoT2-Meta, a training-free metacognitive reasoning framework that combines object-level chain-of-thought generation with meta-level control over partial reasoning trajectories. The framework integrates four components: strategy-conditioned thought generation, tree-structured search, an online process oracle for step-level reasoning evaluation, and a meta-controller that allocates computation through expansion, pruning, repair, stopping, and fallback decisions. Under matched inference budgets, CoT2-Meta consistently outperforms strong single-path, sampling-based, and search-based baselines, including ReST-MCTS. On the default backbone, it achieves 92.8 EM on MATH, 90.4 accuracy on GPQA, 98.65 EM on GSM8K, 75.8 accuracy on BBEH, 85.6 accuracy on MMMU-Pro, and 48.8 accuracy on HLE, with gains over the strongest non-CoT2-Meta baseline of +3.6, +5.2, +1.15, +2.0, +4.3, and +4.3 points, respectively. Beyond these core results, the framework remains effective across a broader 15-benchmark suite spanning knowledge and QA, multi-hop reasoning, coding, and out-of-distribution evaluation. Additional analyses show better compute scaling, improved calibration, stronger selective prediction, targeted repair behavior, and consistent gains across backbone families. These results suggest that explicit metacognitive control is a practical design principle for reliable and compute-efficient test-time reasoning systems.
MME-CoF-Pro: Evaluating Reasoning Coherence in Video Generative Models with Text and Visual Hints
Mar 20, 2026Video generative models show emerging reasoning behaviors. It is essential to ensure that generated events remain causally consistent across frames for reliable deployment, a property we define as reasoning coherence. To bridge the gap in literature for missing reasoning coherence evaluation, we propose MME-CoF-Pro, a comprehensive video reasoning benchmark to assess reasoning coherence in video models. Specifically, MME-CoF-Pro contains 303 samples across 16 categories, ranging from visual logical to scientific reasoning. It introduces Reasoning Score as evaluation metric for assessing process-level necessary intermediate reasoning steps, and includes three evaluation settings, (a) no hint (b) text hint and (c) visual hint, enabling a controlled investigation into the underlying mechanisms of reasoning hint guidance. Evaluation results in 7 open and closed-source video models reveals insights including: (1) Video generative models exhibit weak reasoning coherence, decoupled from generation quality. (2) Text hints boost apparent correctness but often cause inconsistency and hallucinated reasoning (3) Visual hints benefit structured perceptual tasks but struggle with fine-grained perception. Website: https://video-reasoning-coherence.github.io/
ODAR: Principled Adaptive Routing for LLM Reasoning via Active Inference
Feb 27, 2026The paradigm of large language model (LLM) reasoning is shifting from parameter scaling to test-time compute scaling, yet many existing approaches still rely on uniform brute-force sampling (for example, fixed best-of-N or self-consistency) that is costly, hard to attribute, and can trigger overthinking with diminishing returns. We propose ODAR-Expert, an adaptive routing framework that optimizes the accuracy-efficiency trade-off via principled resource allocation. ODAR uses a difficulty estimator grounded in amortized active inference to dynamically route queries between a heuristic Fast Agent and a deliberative Slow Agent. We further introduce a free-energy-principled, risk-sensitive fusion mechanism that selects answers by minimizing a variational free energy objective, balancing log-likelihood with epistemic uncertainty (varentropy) as a principled alternative to ad hoc voting over heterogeneous candidates. Extensive evaluation across 23 benchmarks shows strong and consistent gains, including 98.2% accuracy on MATH and 54.8% on Humanity's Last Exam (HLE), while improving the compute-accuracy frontier under compute-matched settings. We also validate reproducibility on a fully open-source stack (Llama 4 + DeepSeek), where ODAR surpasses homogeneous sampling strategies while reducing computational costs by 82%. Overall, our results suggest that thinking-optimal scaling requires adaptive resource allocation with free-energy-based decision-making rather than simply increasing test-time compute.
Crowdsourcing-Based Knowledge Graph Construction for Drug Side Effects Using Large Language Models with an Application on Semaglutide
Apr 08, 2025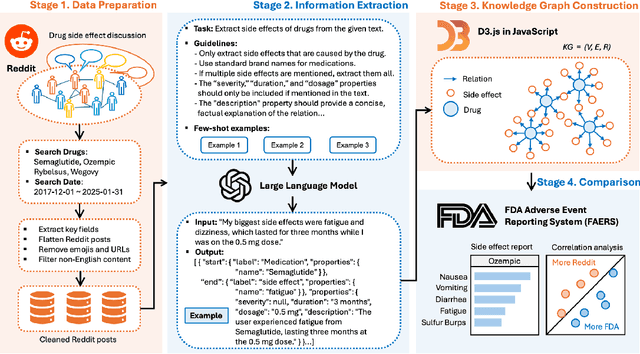

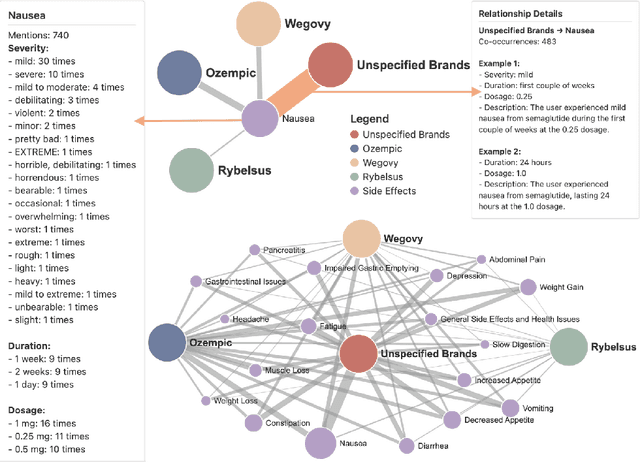
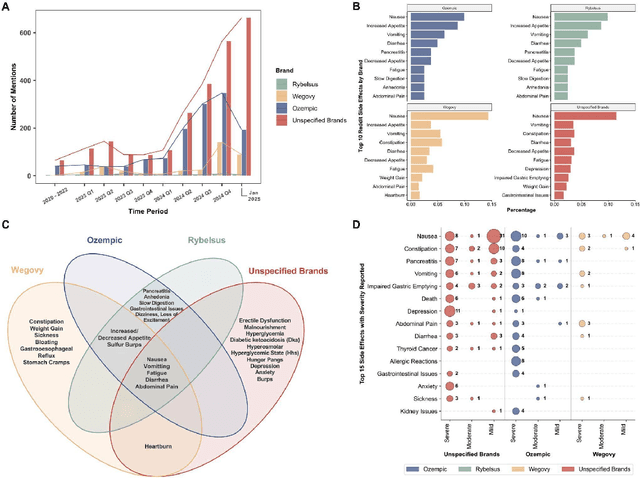
Social media is a rich source of real-world data that captures valuable patient experience information for pharmacovigilance. However, mining data from unstructured and noisy social media content remains a challenging task. We present a systematic framework that leverages large language models (LLMs) to extract medication side effects from social media and organize them into a knowledge graph (KG). We apply this framework to semaglutide for weight loss using data from Reddit. Using the constructed knowledge graph, we perform comprehensive analyses to investigate reported side effects across different semaglutide brands over time. These findings are further validated through comparison with adverse events reported in the FAERS database, providing important patient-centered insights into semaglutide's side effects that complement its safety profile and current knowledge base of semaglutide for both healthcare professionals and patients. Our work demonstrates the feasibility of using LLMs to transform social media data into structured KGs for pharmacovigilance.
Patients Speak, AI Listens: LLM-based Analysis of Online Reviews Uncovers Key Drivers for Urgent Care Satisfaction
Mar 26, 2025Investigating the public experience of urgent care facilities is essential for promoting community healthcare development. Traditional survey methods often fall short due to limited scope, time, and spatial coverage. Crowdsourcing through online reviews or social media offers a valuable approach to gaining such insights. With recent advancements in large language models (LLMs), extracting nuanced perceptions from reviews has become feasible. This study collects Google Maps reviews across the DMV and Florida areas and conducts prompt engineering with the GPT model to analyze the aspect-based sentiment of urgent care. We first analyze the geospatial patterns of various aspects, including interpersonal factors, operational efficiency, technical quality, finances, and facilities. Next, we determine Census Block Group(CBG)-level characteristics underpinning differences in public perception, including population density, median income, GINI Index, rent-to-income ratio, household below poverty rate, no insurance rate, and unemployment rate. Our results show that interpersonal factors and operational efficiency emerge as the strongest determinants of patient satisfaction in urgent care, while technical quality, finances, and facilities show no significant independent effects when adjusted for in multivariate models. Among socioeconomic and demographic factors, only population density demonstrates a significant but modest association with patient ratings, while the remaining factors exhibit no significant correlations. Overall, this study highlights the potential of crowdsourcing to uncover the key factors that matter to residents and provide valuable insights for stakeholders to improve public satisfaction with urgent care.
Fast training of large kernel models with delayed projections
Nov 25, 2024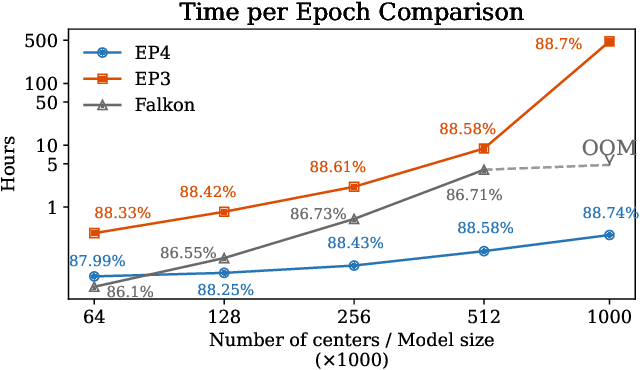

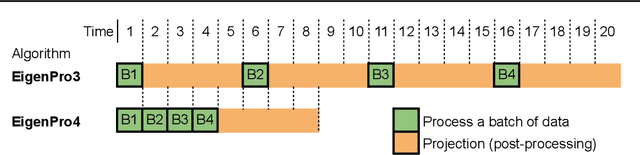

Classical kernel machines have historically faced significant challenges in scaling to large datasets and model sizes--a key ingredient that has driven the success of neural networks. In this paper, we present a new methodology for building kernel machines that can scale efficiently with both data size and model size. Our algorithm introduces delayed projections to Preconditioned Stochastic Gradient Descent (PSGD) allowing the training of much larger models than was previously feasible, pushing the practical limits of kernel-based learning. We validate our algorithm, EigenPro4, across multiple datasets, demonstrating drastic training speed up over the existing methods while maintaining comparable or better classification accuracy.
Benchmarking Vision Language Model Unlearning via Fictitious Facial Identity Dataset
Nov 05, 2024



Machine unlearning has emerged as an effective strategy for forgetting specific information in the training data. However, with the increasing integration of visual data, privacy concerns in Vision Language Models (VLMs) remain underexplored. To address this, we introduce Facial Identity Unlearning Benchmark (FIUBench), a novel VLM unlearning benchmark designed to robustly evaluate the effectiveness of unlearning algorithms under the Right to be Forgotten setting. Specifically, we formulate the VLM unlearning task via constructing the Fictitious Facial Identity VQA dataset and apply a two-stage evaluation pipeline that is designed to precisely control the sources of information and their exposure levels. In terms of evaluation, since VLM supports various forms of ways to ask questions with the same semantic meaning, we also provide robust evaluation metrics including membership inference attacks and carefully designed adversarial privacy attacks to evaluate the performance of algorithms. Through the evaluation of four baseline VLM unlearning algorithms within FIUBench, we find that all methods remain limited in their unlearning performance, with significant trade-offs between model utility and forget quality. Furthermore, our findings also highlight the importance of privacy attacks for robust evaluations. We hope FIUBench will drive progress in developing more effective VLM unlearning algorithms.
Recent advances in deep learning and language models for studying the microbiome
Sep 15, 2024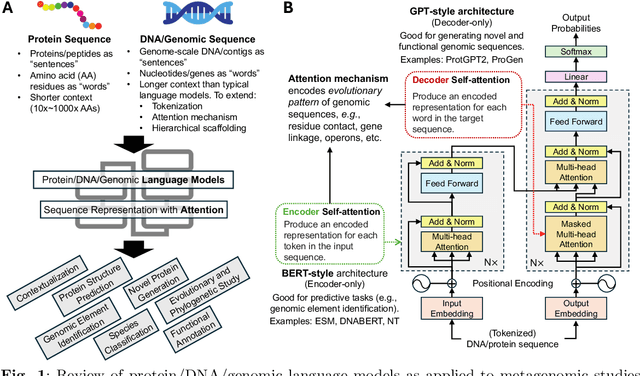

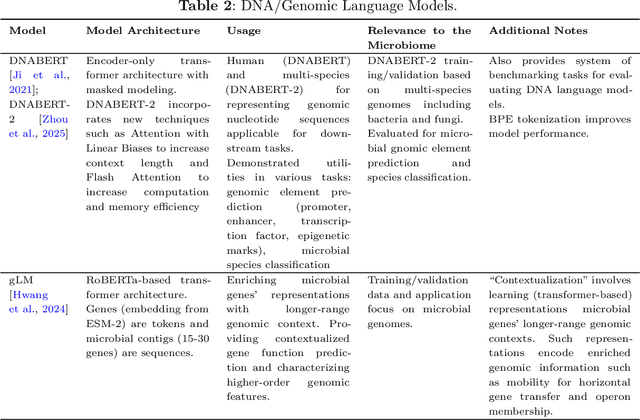

Recent advancements in deep learning, particularly large language models (LLMs), made a significant impact on how researchers study microbiome and metagenomics data. Microbial protein and genomic sequences, like natural languages, form a language of life, enabling the adoption of LLMs to extract useful insights from complex microbial ecologies. In this paper, we review applications of deep learning and language models in analyzing microbiome and metagenomics data. We focus on problem formulations, necessary datasets, and the integration of language modeling techniques. We provide an extensive overview of protein/genomic language modeling and their contributions to microbiome studies. We also discuss applications such as novel viromics language modeling, biosynthetic gene cluster prediction, and knowledge integration for metagenomics studies.
Visual-RolePlay: Universal Jailbreak Attack on MultiModal Large Language Models via Role-playing Image Characte
May 25, 2024With the advent and widespread deployment of Multimodal Large Language Models (MLLMs), ensuring their safety has become increasingly critical. To achieve this objective, it requires us to proactively discover the vulnerability of MLLMs by exploring the attack methods. Thus, structure-based jailbreak attacks, where harmful semantic content is embedded within images, have been proposed to mislead the models. However, previous structure-based jailbreak methods mainly focus on transforming the format of malicious queries, such as converting harmful content into images through typography, which lacks sufficient jailbreak effectiveness and generalizability. To address these limitations, we first introduce the concept of "Role-play" into MLLM jailbreak attacks and propose a novel and effective method called Visual Role-play (VRP). Specifically, VRP leverages Large Language Models to generate detailed descriptions of high-risk characters and create corresponding images based on the descriptions. When paired with benign role-play instruction texts, these high-risk character images effectively mislead MLLMs into generating malicious responses by enacting characters with negative attributes. We further extend our VRP method into a universal setup to demonstrate its generalizability. Extensive experiments on popular benchmarks show that VRP outperforms the strongest baseline, Query relevant and FigStep, by an average Attack Success Rate (ASR) margin of 14.3% across all models.