 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVery Attentive Tacotron: Robust and Unbounded Length Generalization in Autoregressive Transformer-Based Text-to-Speech
Oct 29, 2024Autoregressive (AR) Transformer-based sequence models are known to have difficulty generalizing to sequences longer than those seen during training. When applied to text-to-speech (TTS), these models tend to drop or repeat words or produce erratic output, especially for longer utterances. In this paper, we introduce enhancements aimed at AR Transformer-based encoder-decoder TTS systems that address these robustness and length generalization issues. Our approach uses an alignment mechanism to provide cross-attention operations with relative location information. The associated alignment position is learned as a latent property of the model via backprop and requires no external alignment information during training. While the approach is tailored to the monotonic nature of TTS input-output alignment, it is still able to benefit from the flexible modeling power of interleaved multi-head self- and cross-attention operations. A system incorporating these improvements, which we call Very Attentive Tacotron, matches the naturalness and expressiveness of a baseline T5-based TTS system, while eliminating problems with repeated or dropped words and enabling generalization to any practical utterance length.
Learning the joint distribution of two sequences using little or no paired data
Dec 06, 2022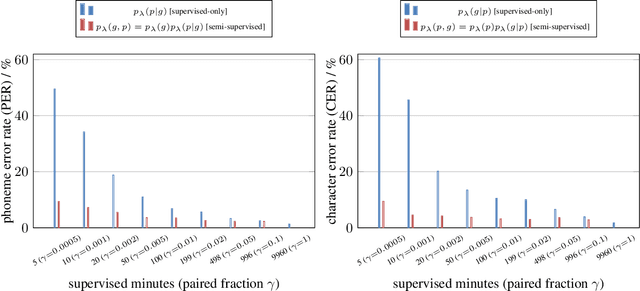



We present a noisy channel generative model of two sequences, for example text and speech, which enables uncovering the association between the two modalities when limited paired data is available. To address the intractability of the exact model under a realistic data setup, we propose a variational inference approximation. To train this variational model with categorical data, we propose a KL encoder loss approach which has connections to the wake-sleep algorithm. Identifying the joint or conditional distributions by only observing unpaired samples from the marginals is only possible under certain conditions in the data distribution and we discuss under what type of conditional independence assumptions that might be achieved, which guides the architecture designs. Experimental results show that even tiny amount of paired data (5 minutes) is sufficient to learn to relate the two modalities (graphemes and phonemes here) when a massive amount of unpaired data is available, paving the path to adopting this principled approach for all seq2seq models in low data resource regimes.
Speaker Generation
Nov 07, 2021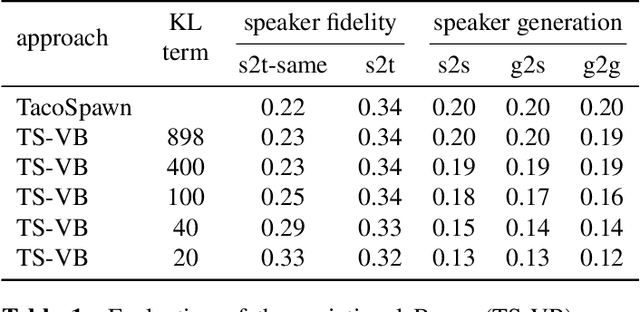
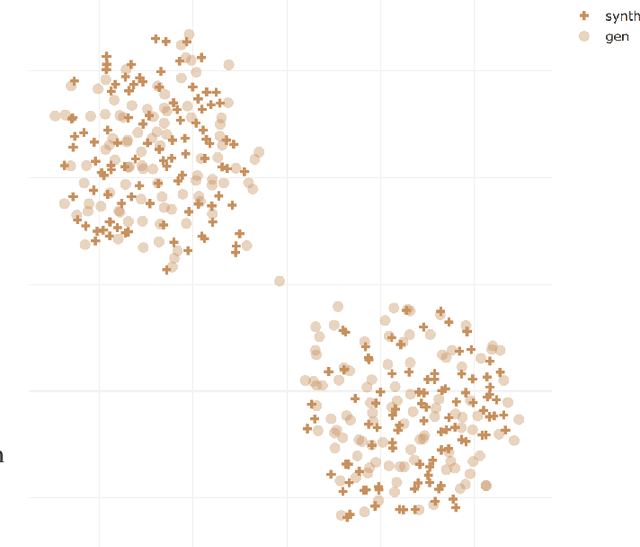
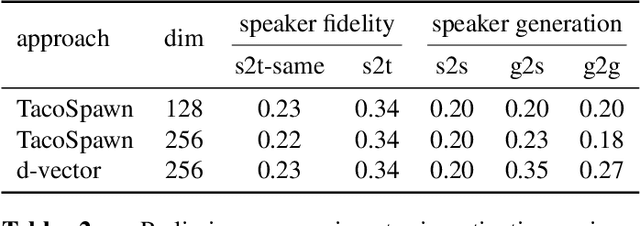
This work explores the task of synthesizing speech in nonexistent human-sounding voices. We call this task "speaker generation", and present TacoSpawn, a system that performs competitively at this task. TacoSpawn is a recurrent attention-based text-to-speech model that learns a distribution over a speaker embedding space, which enables sampling of novel and diverse speakers. Our method is easy to implement, and does not require transfer learning from speaker ID systems. We present objective and subjective metrics for evaluating performance on this task, and demonstrate that our proposed objective metrics correlate with human perception of speaker similarity. Audio samples are available on our demo page.
Non-saturating GAN training as divergence minimization
Oct 15, 2020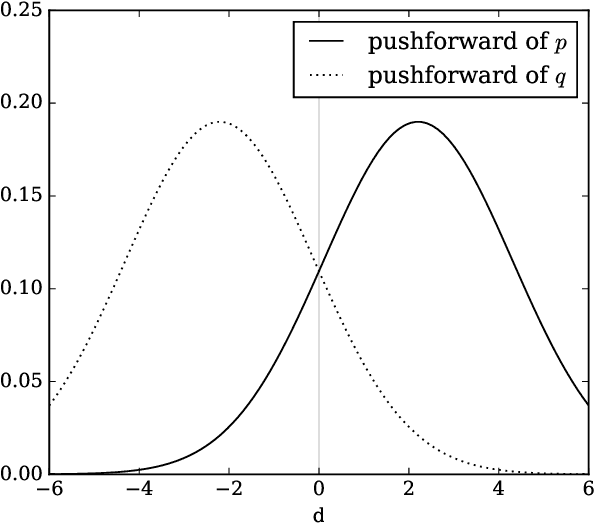

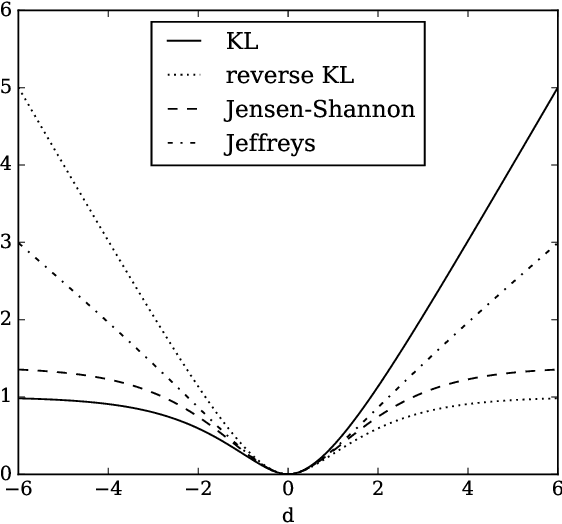
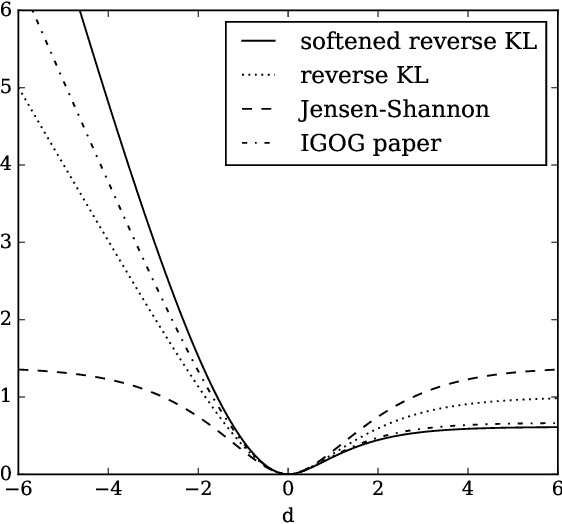
Non-saturating generative adversarial network (GAN) training is widely used and has continued to obtain groundbreaking results. However so far this approach has lacked strong theoretical justification, in contrast to alternatives such as f-GANs and Wasserstein GANs which are motivated in terms of approximate divergence minimization. In this paper we show that non-saturating GAN training does in fact approximately minimize a particular f-divergence. We develop general theoretical tools to compare and classify f-divergences and use these to show that the new f-divergence is qualitatively similar to reverse KL. These results help to explain the high sample quality but poor diversity often observed empirically when using this scheme.
Location-Relative Attention Mechanisms For Robust Long-Form Speech Synthesis
Oct 23, 2019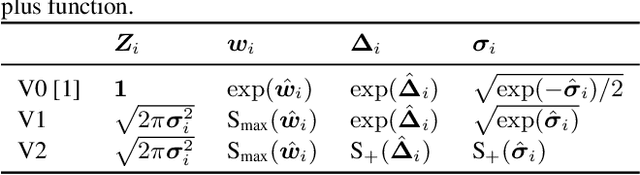

Despite the ability to produce human-level speech for in-domain text, attention-based end-to-end text-to-speech (TTS) systems suffer from text alignment failures that increase in frequency for out-of-domain text. We show that these failures can be addressed using simple location-relative attention mechanisms that do away with content-based query/key comparisons. We compare two families of attention mechanisms: location-relative GMM-based mechanisms and additive energy-based mechanisms. We suggest simple modifications to GMM-based attention that allow it to align quickly and consistently during training, and introduce a new location-relative attention mechanism to the additive energy-based family, called Dynamic Convolution Attention (DCA). We compare the various mechanisms in terms of alignment speed and consistency during training, naturalness, and ability to generalize to long utterances, and conclude that GMM attention and DCA can generalize to very long utterances, while preserving naturalness for shorter, in-domain utterances.
Semi-Supervised Generative Modeling for Controllable Speech Synthesis
Oct 03, 2019


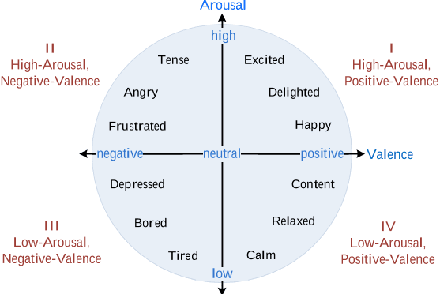
We present a novel generative model that combines state-of-the-art neural text-to-speech (TTS) with semi-supervised probabilistic latent variable models. By providing partial supervision to some of the latent variables, we are able to force them to take on consistent and interpretable purposes, which previously hasn't been possible with purely unsupervised TTS models. We demonstrate that our model is able to reliably discover and control important but rarely labelled attributes of speech, such as affect and speaking rate, with as little as 1% (30 minutes) supervision. Even at such low supervision levels we do not observe a degradation of synthesis quality compared to a state-of-the-art baseline. Audio samples are available on the web.
Effective Use of Variational Embedding Capacity in Expressive End-to-End Speech Synthesis
Jul 09, 2019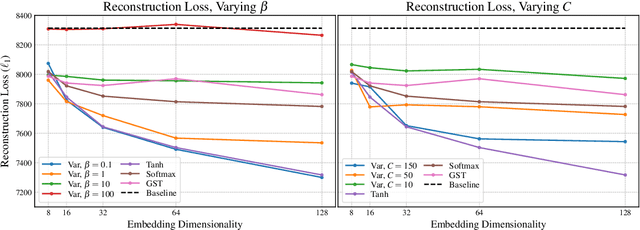
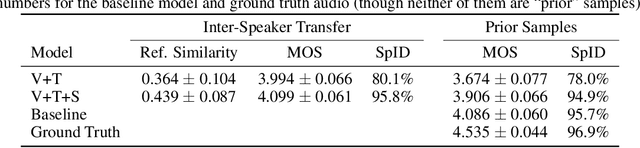
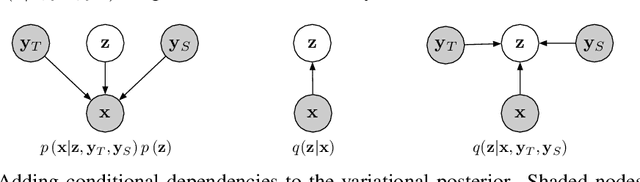
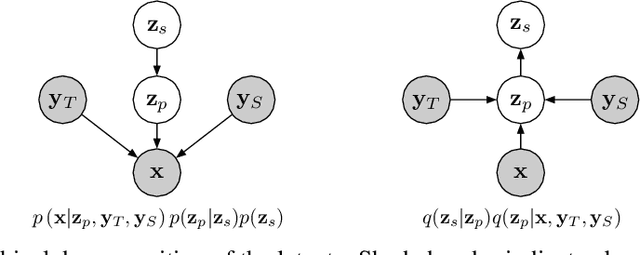
Recent work has explored sequence-to-sequence latent variable models for expressive speech synthesis (supporting control and transfer of prosody and style), but has not presented a coherent framework for understanding the trade-offs between the competing methods. In this paper, we propose embedding capacity as a unified method of analyzing the behavior of latent variable models of speech, comparing existing heuristic (non-variational) methods to variational methods that are able to explicitly constrain capacity using an upper bound on representational mutual information. In our proposed model (Capacitron), we show that by adding conditional dependencies to the variational posterior such that it matches the form of the true posterior, the same model can be used for high-precision prosody transfer, text-agnostic style transfer, and generation of natural-sounding prior samples. For multi-speaker models, Capacitron is able to preserve target speaker identity during inter-speaker prosody transfer and when drawing samples from the latent prior. Lastly, we introduce a method for decomposing embedding capacity hierarchically across two sets of latents, allowing a portion of the latent variability to be specified and the remaining variability sampled from a learned prior.
Predicting Expressive Speaking Style From Text In End-To-End Speech Synthesis
Aug 04, 2018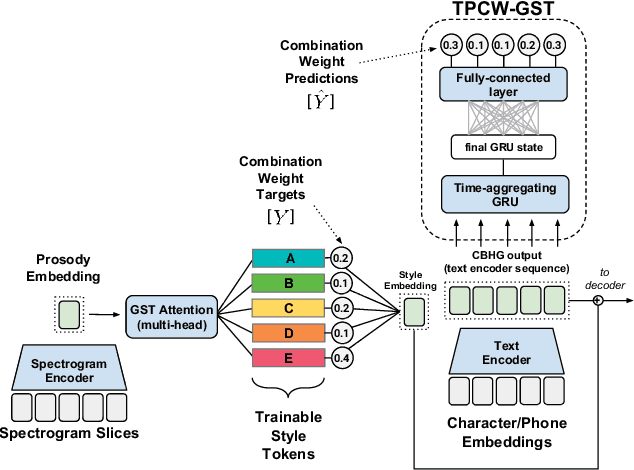

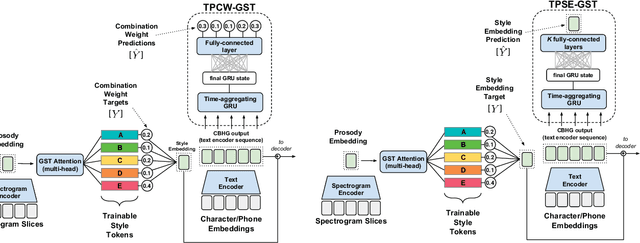

Global Style Tokens (GSTs) are a recently-proposed method to learn latent disentangled representations of high-dimensional data. GSTs can be used within Tacotron, a state-of-the-art end-to-end text-to-speech synthesis system, to uncover expressive factors of variation in speaking style. In this work, we introduce the Text-Predicted Global Style Token (TP-GST) architecture, which treats GST combination weights or style embeddings as "virtual" speaking style labels within Tacotron. TP-GST learns to predict stylistic renderings from text alone, requiring neither explicit labels during training nor auxiliary inputs for inference. We show that, when trained on a dataset of expressive speech, our system generates audio with more pitch and energy variation than two state-of-the-art baseline models. We further demonstrate that TP-GSTs can synthesize speech with background noise removed, and corroborate these analyses with positive results on human-rated listener preference audiobook tasks. Finally, we demonstrate that multi-speaker TP-GST models successfully factorize speaker identity and speaking style. We provide a website with audio samples for each of our findings.
Towards End-to-End Prosody Transfer for Expressive Speech Synthesis with Tacotron
Mar 24, 2018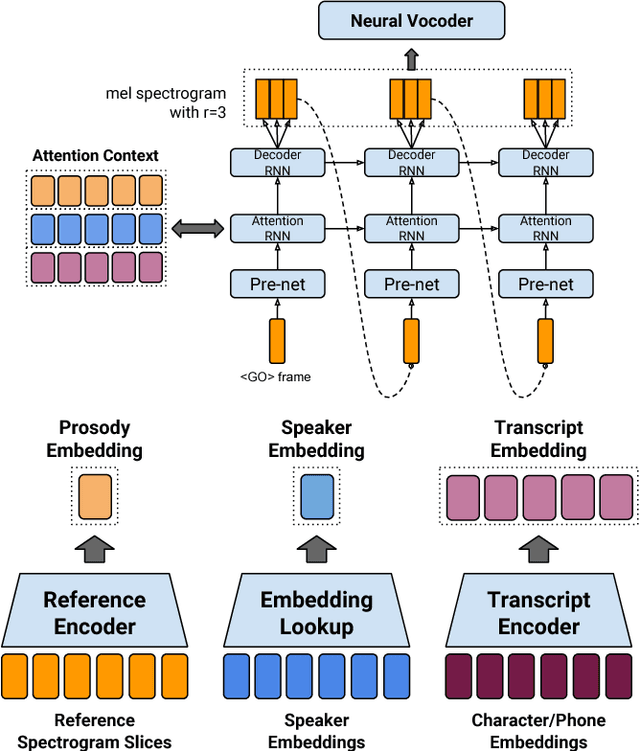
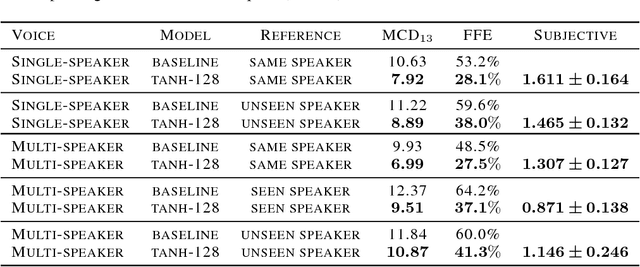

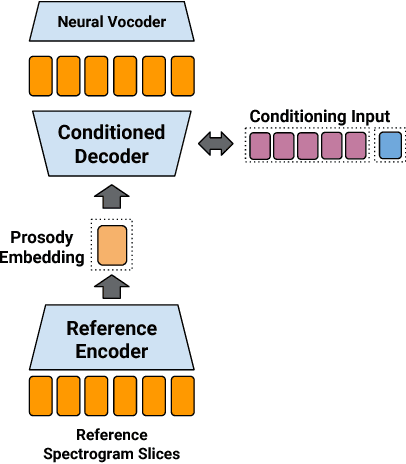
We present an extension to the Tacotron speech synthesis architecture that learns a latent embedding space of prosody, derived from a reference acoustic representation containing the desired prosody. We show that conditioning Tacotron on this learned embedding space results in synthesized audio that matches the prosody of the reference signal with fine time detail even when the reference and synthesis speakers are different. Additionally, we show that a reference prosody embedding can be used to synthesize text that is different from that of the reference utterance. We define several quantitative and subjective metrics for evaluating prosody transfer, and report results with accompanying audio samples from single-speaker and 44-speaker Tacotron models on a prosody transfer task.
Style Tokens: Unsupervised Style Modeling, Control and Transfer in End-to-End Speech Synthesis
Mar 23, 2018
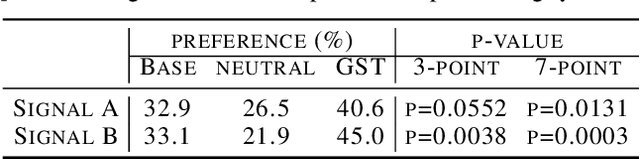
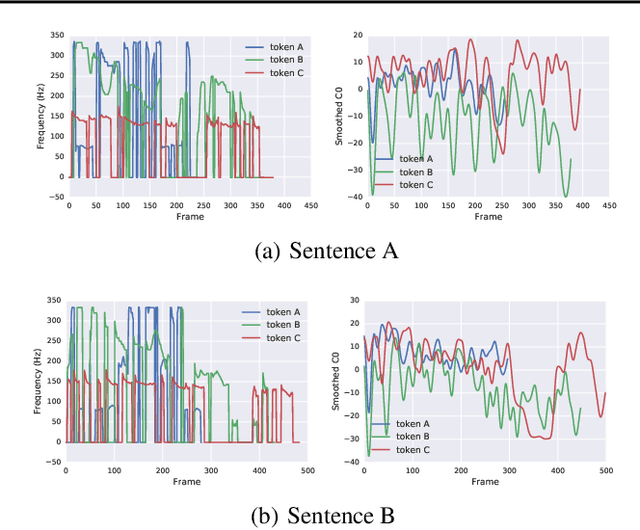

In this work, we propose "global style tokens" (GSTs), a bank of embeddings that are jointly trained within Tacotron, a state-of-the-art end-to-end speech synthesis system. The embeddings are trained with no explicit labels, yet learn to model a large range of acoustic expressiveness. GSTs lead to a rich set of significant results. The soft interpretable "labels" they generate can be used to control synthesis in novel ways, such as varying speed and speaking style - independently of the text content. They can also be used for style transfer, replicating the speaking style of a single audio clip across an entire long-form text corpus. When trained on noisy, unlabeled found data, GSTs learn to factorize noise and speaker identity, providing a path towards highly scalable but robust speech synthesis.