 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Expressive Speaking Style From Text In End-To-End Speech Synthesis
Paper and Code
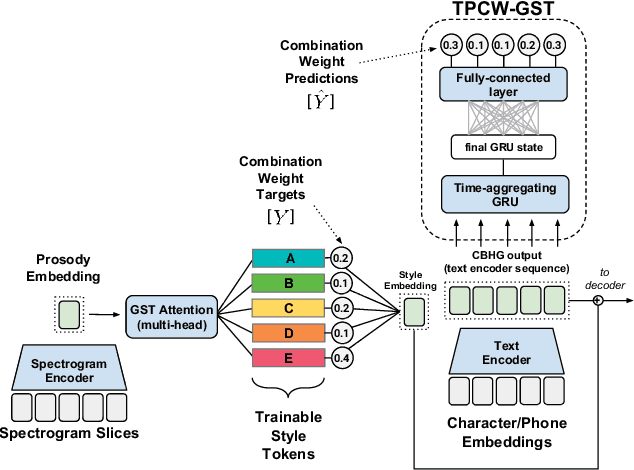

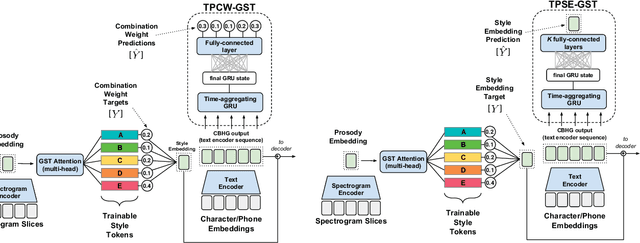

Global Style Tokens (GSTs) are a recently-proposed method to learn latent disentangled representations of high-dimensional data. GSTs can be used within Tacotron, a state-of-the-art end-to-end text-to-speech synthesis system, to uncover expressive factors of variation in speaking style. In this work, we introduce the Text-Predicted Global Style Token (TP-GST) architecture, which treats GST combination weights or style embeddings as "virtual" speaking style labels within Tacotron. TP-GST learns to predict stylistic renderings from text alone, requiring neither explicit labels during training nor auxiliary inputs for inference. We show that, when trained on a dataset of expressive speech, our system generates audio with more pitch and energy variation than two state-of-the-art baseline models. We further demonstrate that TP-GSTs can synthesize speech with background noise removed, and corroborate these analyses with positive results on human-rated listener preference audiobook tasks. Finally, we demonstrate that multi-speaker TP-GST models successfully factorize speaker identity and speaking style. We provide a website with audio samples for each of our findings.