 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning the joint distribution of two sequences using little or no paired data
Paper and Code
Dec 06, 2022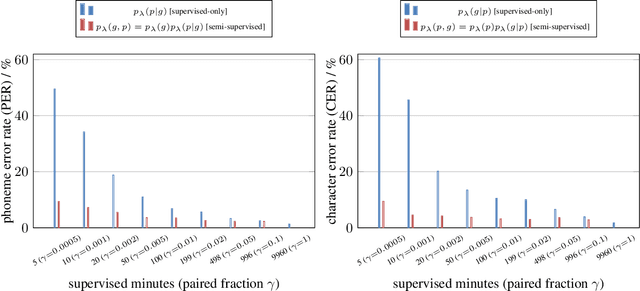



We present a noisy channel generative model of two sequences, for example text and speech, which enables uncovering the association between the two modalities when limited paired data is available. To address the intractability of the exact model under a realistic data setup, we propose a variational inference approximation. To train this variational model with categorical data, we propose a KL encoder loss approach which has connections to the wake-sleep algorithm. Identifying the joint or conditional distributions by only observing unpaired samples from the marginals is only possible under certain conditions in the data distribution and we discuss under what type of conditional independence assumptions that might be achieved, which guides the architecture designs. Experimental results show that even tiny amount of paired data (5 minutes) is sufficient to learn to relate the two modalities (graphemes and phonemes here) when a massive amount of unpaired data is available, paving the path to adopting this principled approach for all seq2seq models in low data resource regimes.