 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-agent cooperation through in-context co-player inference
Feb 18, 2026Achieving cooperation among self-interested agents remains a fundamental challenge in multi-agent reinforcement learning. Recent work showed that mutual cooperation can be induced between "learning-aware" agents that account for and shape the learning dynamics of their co-players. However, existing approaches typically rely on hardcoded, often inconsistent, assumptions about co-player learning rules or enforce a strict separation between "naive learners" updating on fast timescales and "meta-learners" observing these updates. Here, we demonstrate that the in-context learning capabilities of sequence models allow for co-player learning awareness without requiring hardcoded assumptions or explicit timescale separation. We show that training sequence model agents against a diverse distribution of co-players naturally induces in-context best-response strategies, effectively functioning as learning algorithms on the fast intra-episode timescale. We find that the cooperative mechanism identified in prior work-where vulnerability to extortion drives mutual shaping-emerges naturally in this setting: in-context adaptation renders agents vulnerable to extortion, and the resulting mutual pressure to shape the opponent's in-context learning dynamics resolves into the learning of cooperative behavior. Our results suggest that standard decentralized reinforcement learning on sequence models combined with co-player diversity provides a scalable path to learning cooperative behaviors.
Emergent temporal abstractions in autoregressive models enable hierarchical reinforcement learning
Dec 24, 2025Large-scale autoregressive models pretrained on next-token prediction and finetuned with reinforcement learning (RL) have achieved unprecedented success on many problem domains. During RL, these models explore by generating new outputs, one token at a time. However, sampling actions token-by-token can result in highly inefficient learning, particularly when rewards are sparse. Here, we show that it is possible to overcome this problem by acting and exploring within the internal representations of an autoregressive model. Specifically, to discover temporally-abstract actions, we introduce a higher-order, non-causal sequence model whose outputs control the residual stream activations of a base autoregressive model. On grid world and MuJoCo-based tasks with hierarchical structure, we find that the higher-order model learns to compress long activation sequence chunks onto internal controllers. Critically, each controller executes a sequence of behaviorally meaningful actions that unfold over long timescales and are accompanied with a learned termination condition, such that composing multiple controllers over time leads to efficient exploration on novel tasks. We show that direct internal controller reinforcement, a process we term "internal RL", enables learning from sparse rewards in cases where standard RL finetuning fails. Our results demonstrate the benefits of latent action generation and reinforcement in autoregressive models, suggesting internal RL as a promising avenue for realizing hierarchical RL within foundation models.
MesaNet: Sequence Modeling by Locally Optimal Test-Time Training
Jun 05, 2025Sequence modeling is currently dominated by causal transformer architectures that use softmax self-attention. Although widely adopted, transformers require scaling memory and compute linearly during inference. A recent stream of work linearized the softmax operation, resulting in powerful recurrent neural network (RNN) models with constant memory and compute costs such as DeltaNet, Mamba or xLSTM. These models can be unified by noting that their recurrent layer dynamics can all be derived from an in-context regression objective, approximately optimized through an online learning rule. Here, we join this line of work and introduce a numerically stable, chunkwise parallelizable version of the recently proposed Mesa layer (von Oswald et al., 2024), and study it in language modeling at the billion-parameter scale. This layer again stems from an in-context loss, but which is now minimized to optimality at every time point using a fast conjugate gradient solver. Through an extensive suite of experiments, we show that optimal test-time training enables reaching lower language modeling perplexity and higher downstream benchmark performance than previous RNNs, especially on tasks requiring long context understanding. This performance gain comes at the cost of additional flops spent during inference time. Our results are therefore intriguingly related to recent trends of increasing test-time compute to improve performance -- here by spending compute to solve sequential optimization problems within the neural network itself.
All Random Features Representations are Equivalent
Jun 27, 2024Random features are an important technique that make it possible to rewrite positive-definite kernels as infinite-dimensional dot products. Over time, increasingly elaborate random feature representations have been developed in pursuit of finite approximations with ever lower error. We resolve this arms race by deriving an optimal sampling policy, and show that under this policy all random features representations have the same approximation error. This establishes a lower bound that holds across all random feature representations, and shows that we are free to choose whatever representation we please, provided we sample optimally.
Scalable Spatiotemporal Prediction with Bayesian Neural Fields
Mar 12, 2024Spatiotemporal datasets, which consist of spatially-referenced time series, are ubiquitous in many scientific and business-intelligence applications, such as air pollution monitoring, disease tracking, and cloud-demand forecasting. As modern datasets continue to increase in size and complexity, there is a growing need for new statistical methods that are flexible enough to capture complex spatiotemporal dynamics and scalable enough to handle large prediction problems. This work presents the Bayesian Neural Field (BayesNF), a domain-general statistical model for inferring rich probability distributions over a spatiotemporal domain, which can be used for data-analysis tasks including forecasting, interpolation, and variography. BayesNF integrates a novel deep neural network architecture for high-capacity function estimation with hierarchical Bayesian inference for robust uncertainty quantification. By defining the prior through a sequence of smooth differentiable transforms, posterior inference is conducted on large-scale data using variationally learned surrogates trained via stochastic gradient descent. We evaluate BayesNF against prominent statistical and machine-learning baselines, showing considerable improvements on diverse prediction problems from climate and public health datasets that contain tens to hundreds of thousands of measurements. The paper is accompanied with an open-source software package (https://github.com/google/bayesnf) that is easy-to-use and compatible with modern GPU and TPU accelerators on the JAX machine learning platform.
Robust Inverse Graphics via Probabilistic Inference
Feb 02, 2024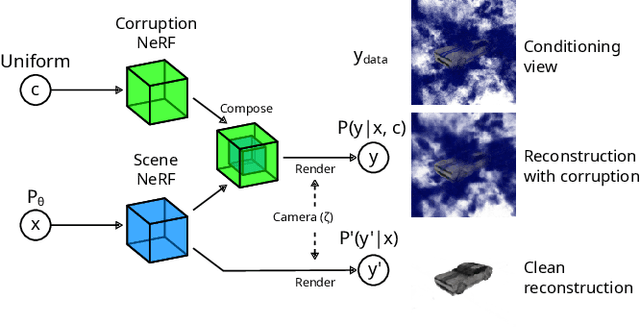
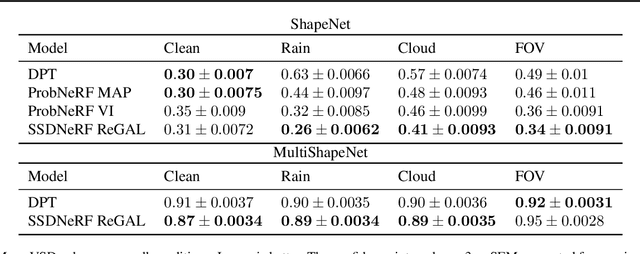

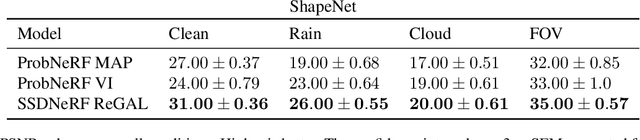
How do we infer a 3D scene from a single image in the presence of corruptions like rain, snow or fog? Straightforward domain randomization relies on knowing the family of corruptions ahead of time. Here, we propose a Bayesian approach-dubbed robust inverse graphics (RIG)-that relies on a strong scene prior and an uninformative uniform corruption prior, making it applicable to a wide range of corruptions. Given a single image, RIG performs posterior inference jointly over the scene and the corruption. We demonstrate this idea by training a neural radiance field (NeRF) scene prior and using a secondary NeRF to represent the corruptions over which we place an uninformative prior. RIG, trained only on clean data, outperforms depth estimators and alternative NeRF approaches that perform point estimation instead of full inference. The results hold for a number of scene prior architectures based on normalizing flows and diffusion models. For the latter, we develop reconstruction-guidance with auxiliary latents (ReGAL)-a diffusion conditioning algorithm that is applicable in the presence of auxiliary latent variables such as the corruption. RIG demonstrates how scene priors can be used beyond generation tasks.
Training Chain-of-Thought via Latent-Variable Inference
Nov 28, 2023
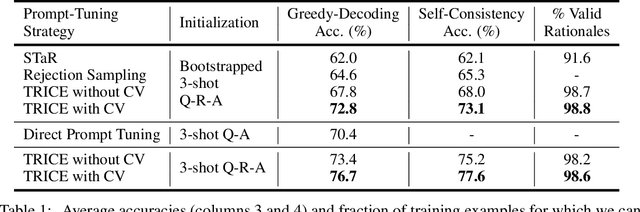
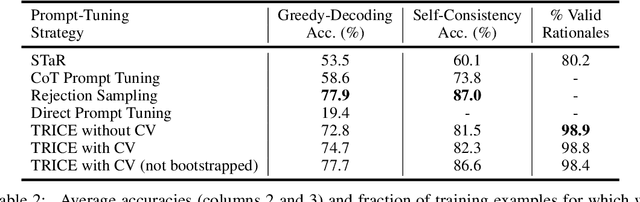
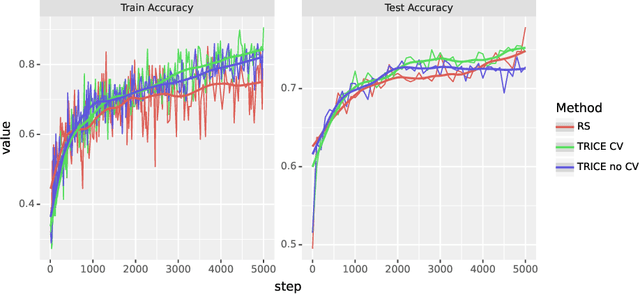
Large language models (LLMs) solve problems more accurately and interpretably when instructed to work out the answer step by step using a ``chain-of-thought'' (CoT) prompt. One can also improve LLMs' performance on a specific task by supervised fine-tuning, i.e., by using gradient ascent on some tunable parameters to maximize the average log-likelihood of correct answers from a labeled training set. Naively combining CoT with supervised tuning requires supervision not just of the correct answers, but also of detailed rationales that lead to those answers; these rationales are expensive to produce by hand. Instead, we propose a fine-tuning strategy that tries to maximize the \emph{marginal} log-likelihood of generating a correct answer using CoT prompting, approximately averaging over all possible rationales. The core challenge is sampling from the posterior over rationales conditioned on the correct answer; we address it using a simple Markov-chain Monte Carlo (MCMC) expectation-maximization (EM) algorithm inspired by the self-taught reasoner (STaR), memoized wake-sleep, Markovian score climbing, and persistent contrastive divergence. This algorithm also admits a novel control-variate technique that drives the variance of our gradient estimates to zero as the model improves. Applying our technique to GSM8K and the tasks in BIG-Bench Hard, we find that this MCMC-EM fine-tuning technique typically improves the model's accuracy on held-out examples more than STaR or prompt-tuning with or without CoT.
Sequential Monte Carlo Learning for Time Series Structure Discovery
Jul 13, 2023This paper presents a new approach to automatically discovering accurate models of complex time series data. Working within a Bayesian nonparametric prior over a symbolic space of Gaussian process time series models, we present a novel structure learning algorithm that integrates sequential Monte Carlo (SMC) and involutive MCMC for highly effective posterior inference. Our method can be used both in "online" settings, where new data is incorporated sequentially in time, and in "offline" settings, by using nested subsets of historical data to anneal the posterior. Empirical measurements on real-world time series show that our method can deliver 10x--100x runtime speedups over previous MCMC and greedy-search structure learning algorithms targeting the same model family. We use our method to perform the first large-scale evaluation of Gaussian process time series structure learning on a prominent benchmark of 1,428 econometric datasets. The results show that our method discovers sensible models that deliver more accurate point forecasts and interval forecasts over multiple horizons as compared to widely used statistical and neural baselines that struggle on this challenging data.
* 17 pages, 8 figures, 2 tables. Appearing in ICML 2023
Grammar Prompting for Domain-Specific Language Generation with Large Language Models
May 31, 2023



Large language models (LLMs) can learn to perform a wide range of natural language tasks from just a handful of in-context examples. However, for generating strings from highly structured languages (e.g., semantic parsing to complex domain-specific languages), it is challenging for the LLM to generalize from just a few exemplars. We explore $\textbf{grammar prompting}$ as a simple approach for enabling LLMs to use external knowledge and domain-specific constraints, expressed through a grammar expressed in Backus--Naur Form (BNF), during in-context learning. Grammar prompting augments each demonstration example with a specialized grammar that is minimally sufficient for generating the particular output example, where the specialized grammar is a subset of the full DSL grammar. For inference, the LLM first predicts a BNF grammar given a test input, and then generates the output according to the rules of the grammar. Experiments demonstrate that grammar prompting can enable LLMs to perform competitively on a diverse set of DSL generation tasks, including semantic parsing (SMCalFlow, Overnight, GeoQuery), PDDL planning, and even molecule generation (SMILES).
ProbNeRF: Uncertainty-Aware Inference of 3D Shapes from 2D Images
Oct 27, 2022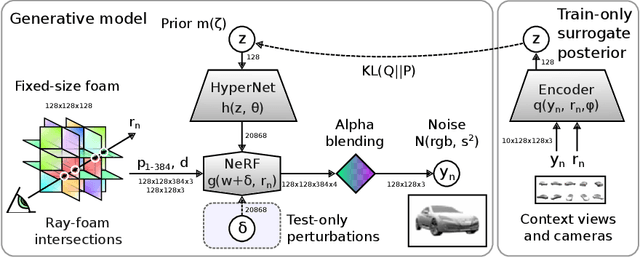

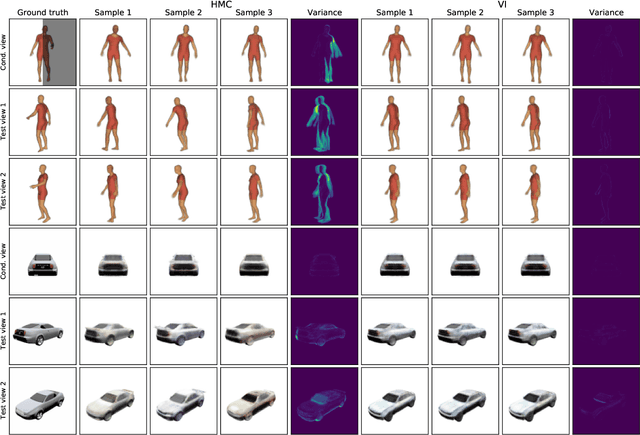
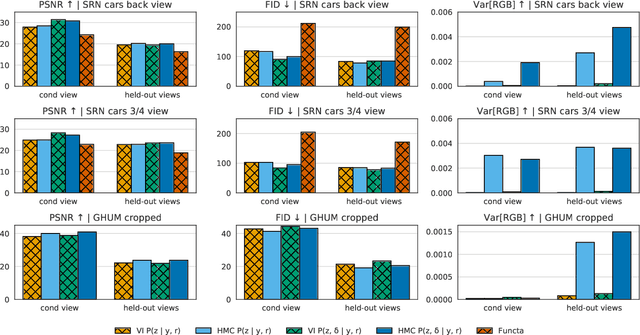
The problem of inferring object shape from a single 2D image is underconstrained. Prior knowledge about what objects are plausible can help, but even given such prior knowledge there may still be uncertainty about the shapes of occluded parts of objects. Recently, conditional neural radiance field (NeRF) models have been developed that can learn to infer good point estimates of 3D models from single 2D images. The problem of inferring uncertainty estimates for these models has received less attention. In this work, we propose probabilistic NeRF (ProbNeRF), a model and inference strategy for learning probabilistic generative models of 3D objects' shapes and appearances, and for doing posterior inference to recover those properties from 2D images. ProbNeRF is trained as a variational autoencoder, but at test time we use Hamiltonian Monte Carlo (HMC) for inference. Given one or a few 2D images of an object (which may be partially occluded), ProbNeRF is able not only to accurately model the parts it sees, but also to propose realistic and diverse hypotheses about the parts it does not see. We show that key to the success of ProbNeRF are (i) a deterministic rendering scheme, (ii) an annealed-HMC strategy, (iii) a hypernetwork-based decoder architecture, and (iv) doing inference over a full set of NeRF weights, rather than just a low-dimensional code.