 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent-Constrained Conditional VAEs for Augmenting Large-Scale Climate Ensembles
Jan 01, 2026Large climate-model ensembles are computationally expensive; yet many downstream analyses would benefit from additional, statistically consistent realizations of spatiotemporal climate variables. We study a generative modeling approach for producing new realizations from a limited set of available runs by transferring structure learned across an ensemble. Using monthly near-surface temperature time series from ten independent reanalysis realizations (ERA5), we find that a vanilla conditional variational autoencoder (CVAE) trained jointly across realizations yields a fragmented latent space that fails to generalize to unseen ensemble members. To address this, we introduce a latent-constrained CVAE (LC-CVAE) that enforces cross-realization homogeneity of latent embeddings at a small set of shared geographic 'anchor' locations. We then use multi-output Gaussian process regression in the latent space to predict latent coordinates at unsampled locations in a new realization, followed by decoding to generate full time series fields. Experiments and ablations demonstrate (i) instability when training on a single realization, (ii) diminishing returns after incorporating roughly five realizations, and (iii) a trade-off between spatial coverage and reconstruction quality that is closely linked to the average neighbor distance in latent space.
Scalable Spatiotemporal Prediction with Bayesian Neural Fields
Mar 12, 2024Spatiotemporal datasets, which consist of spatially-referenced time series, are ubiquitous in many scientific and business-intelligence applications, such as air pollution monitoring, disease tracking, and cloud-demand forecasting. As modern datasets continue to increase in size and complexity, there is a growing need for new statistical methods that are flexible enough to capture complex spatiotemporal dynamics and scalable enough to handle large prediction problems. This work presents the Bayesian Neural Field (BayesNF), a domain-general statistical model for inferring rich probability distributions over a spatiotemporal domain, which can be used for data-analysis tasks including forecasting, interpolation, and variography. BayesNF integrates a novel deep neural network architecture for high-capacity function estimation with hierarchical Bayesian inference for robust uncertainty quantification. By defining the prior through a sequence of smooth differentiable transforms, posterior inference is conducted on large-scale data using variationally learned surrogates trained via stochastic gradient descent. We evaluate BayesNF against prominent statistical and machine-learning baselines, showing considerable improvements on diverse prediction problems from climate and public health datasets that contain tens to hundreds of thousands of measurements. The paper is accompanied with an open-source software package (https://github.com/google/bayesnf) that is easy-to-use and compatible with modern GPU and TPU accelerators on the JAX machine learning platform.
Semantic Segmentation with Active Semi-Supervised Representation Learning
Oct 16, 2022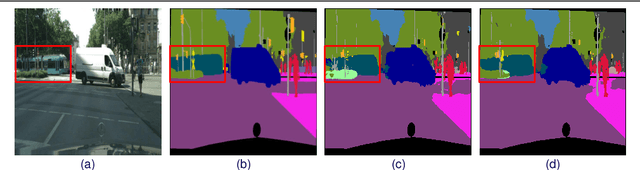
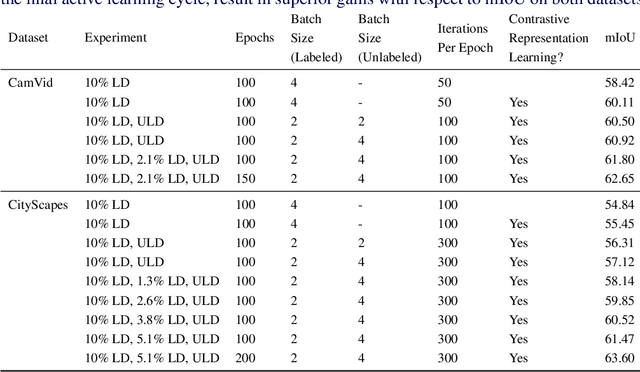
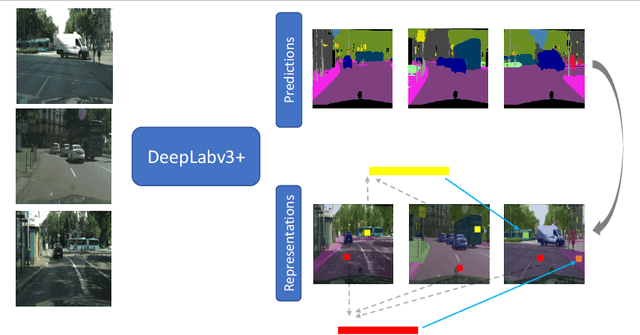
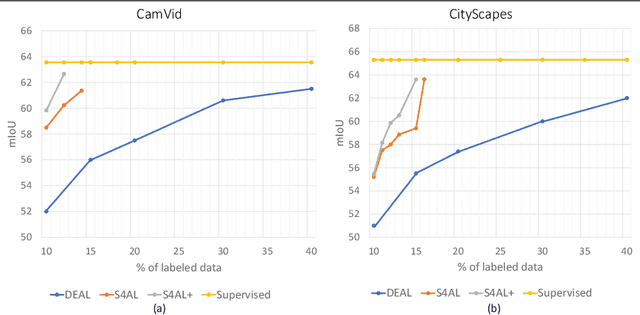
Obtaining human per-pixel labels for semantic segmentation is incredibly laborious, often making labeled dataset construction prohibitively expensive. Here, we endeavor to overcome this problem with a novel algorithm that combines semi-supervised and active learning, resulting in the ability to train an effective semantic segmentation algorithm with significantly lesser labeled data. To do this, we extend the prior state-of-the-art S4AL algorithm by replacing its mean teacher approach for semi-supervised learning with a self-training approach that improves learning with noisy labels. We further boost the neural network's ability to query useful data by adding a contrastive learning head, which leads to better understanding of the objects in the scene, and hence, better queries for active learning. We evaluate our method on CamVid and CityScapes datasets, the de-facto standards for active learning for semantic segmentation. We achieve more than 95% of the network's performance on CamVid and CityScapes datasets, utilizing only 12.1% and 15.1% of the labeled data, respectively. We also benchmark our method across existing stand-alone semi-supervised learning methods on the CityScapes dataset and achieve superior performance without any bells or whistles.
Semantic Segmentation with Active Semi-Supervised Learning
Mar 21, 2022
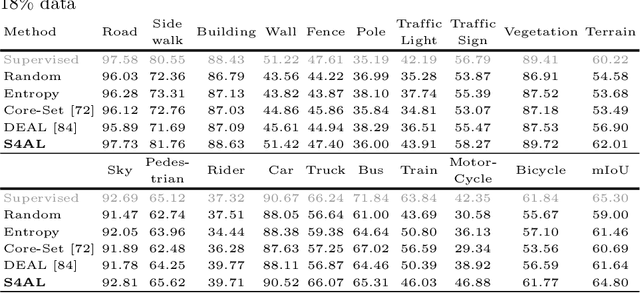
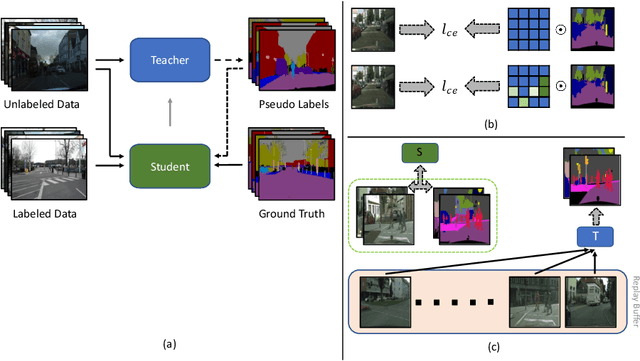
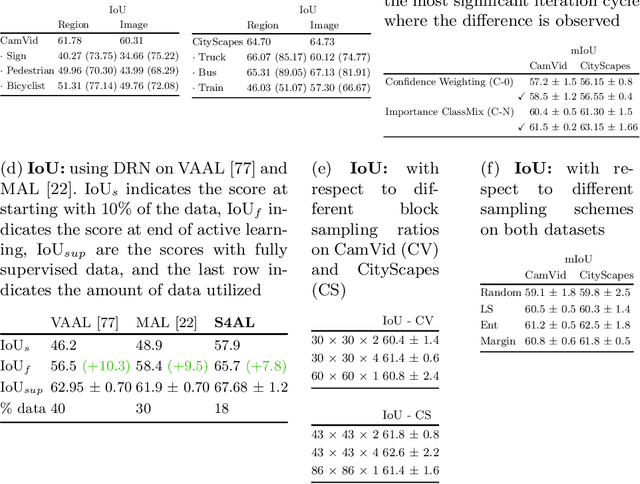
Using deep learning, we now have the ability to create exceptionally good semantic segmentation systems; however, collecting the prerequisite pixel-wise annotations for training images remains expensive and time-consuming. Therefore, it would be ideal to minimize the number of human annotations needed when creating a new dataset. Here, we address this problem by proposing a novel algorithm that combines active learning and semi-supervised learning. Active learning is an approach for identifying the best unlabeled samples to annotate. While there has been work on active learning for segmentation, most methods require annotating all pixel objects in each image, rather than only the most informative regions. We argue that this is inefficient. Instead, our active learning approach aims to minimize the number of annotations per-image. Our method is enriched with semi-supervised learning, where we use pseudo labels generated with a teacher-student framework to identify image regions that help disambiguate confused classes. We also integrate mechanisms that enable better performance on imbalanced label distributions, which have not been studied previously for active learning in semantic segmentation. In experiments on the CamVid and CityScapes datasets, our method obtains over 95% of the network's performance on the full-training set using less than 19% of the training data, whereas the previous state of the art required 40% of the training data.
Launchpad: A Programming Model for Distributed Machine Learning Research
Jun 07, 2021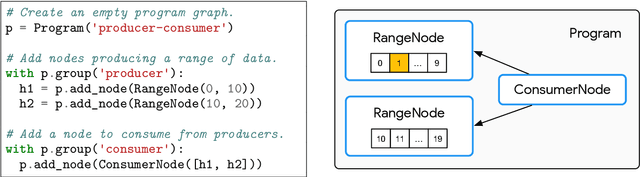
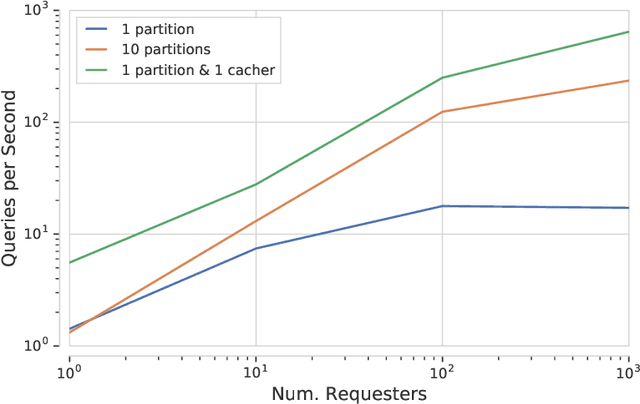
A major driver behind the success of modern machine learning algorithms has been their ability to process ever-larger amounts of data. As a result, the use of distributed systems in both research and production has become increasingly prevalent as a means to scale to this growing data. At the same time, however, distributing the learning process can drastically complicate the implementation of even simple algorithms. This is especially problematic as many machine learning practitioners are not well-versed in the design of distributed systems, let alone those that have complicated communication topologies. In this work we introduce Launchpad, a programming model that simplifies the process of defining and launching distributed systems that is specifically tailored towards a machine learning audience. We describe our framework, its design philosophy and implementation, and give a number of examples of common learning algorithms whose designs are greatly simplified by this approach.
Regularized Behavior Value Estimation
Mar 17, 2021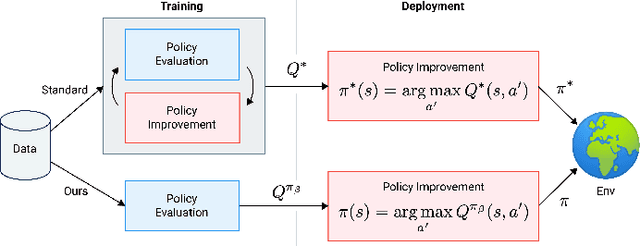
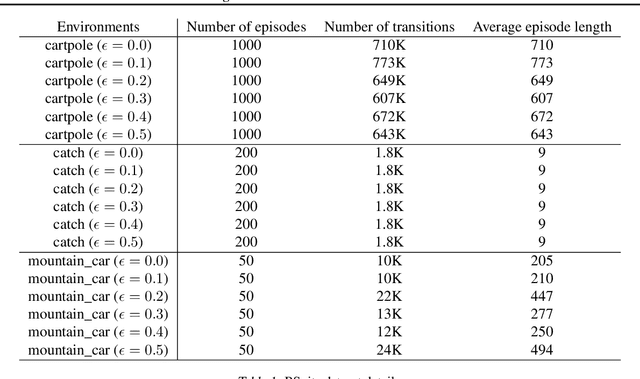
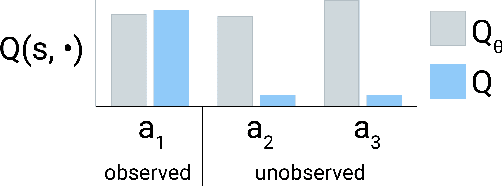
Offline reinforcement learning restricts the learning process to rely only on logged-data without access to an environment. While this enables real-world applications, it also poses unique challenges. One important challenge is dealing with errors caused by the overestimation of values for state-action pairs not well-covered by the training data. Due to bootstrapping, these errors get amplified during training and can lead to divergence, thereby crippling learning. To overcome this challenge, we introduce Regularized Behavior Value Estimation (R-BVE). Unlike most approaches, which use policy improvement during training, R-BVE estimates the value of the behavior policy during training and only performs policy improvement at deployment time. Further, R-BVE uses a ranking regularisation term that favours actions in the dataset that lead to successful outcomes. We provide ample empirical evidence of R-BVE's effectiveness, including state-of-the-art performance on the RL Unplugged ATARI dataset. We also test R-BVE on new datasets, from bsuite and a challenging DeepMind Lab task, and show that R-BVE outperforms other state-of-the-art discrete control offline RL methods.
NeuTra-lizing Bad Geometry in Hamiltonian Monte Carlo Using Neural Transport
Mar 09, 2019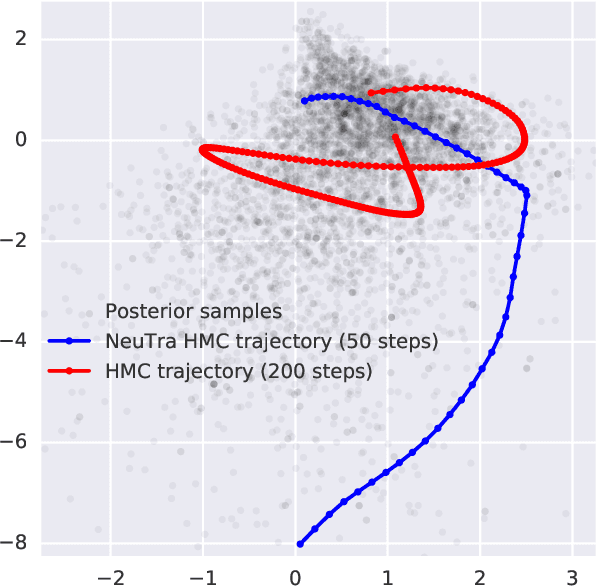

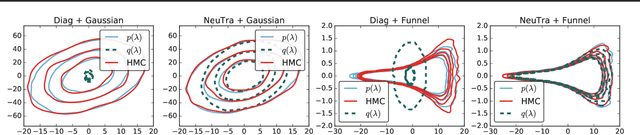
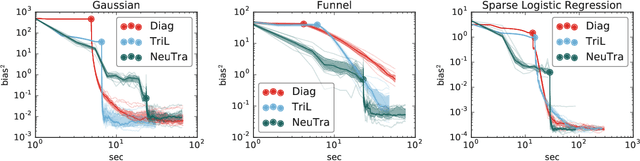
Hamiltonian Monte Carlo is a powerful algorithm for sampling from difficult-to-normalize posterior distributions. However, when the geometry of the posterior is unfavorable, it may take many expensive evaluations of the target distribution and its gradient to converge and mix. We propose neural transport (NeuTra) HMC, a technique for learning to correct this sort of unfavorable geometry using inverse autoregressive flows (IAF), a powerful neural variational inference technique. The IAF is trained to minimize the KL divergence from an isotropic Gaussian to the warped posterior, and then HMC sampling is performed in the warped space. We evaluate NeuTra HMC on a variety of synthetic and real problems, and find that it significantly outperforms vanilla HMC both in time to reach the stationary distribution and asymptotic effective-sample-size rates.
Simple, Distributed, and Accelerated Probabilistic Programming
Nov 29, 2018
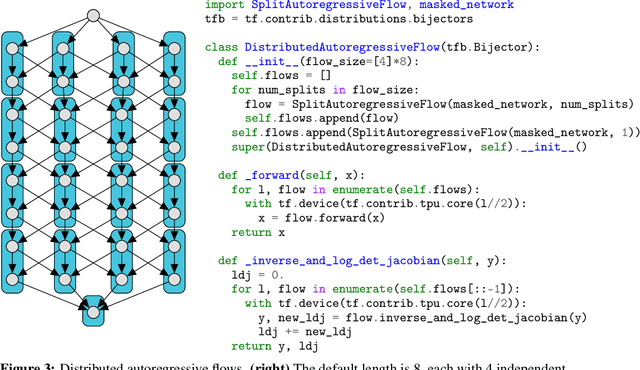
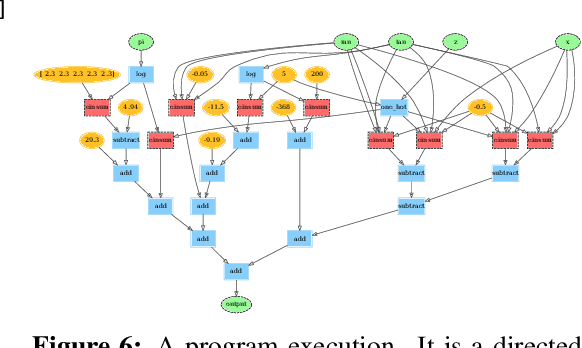
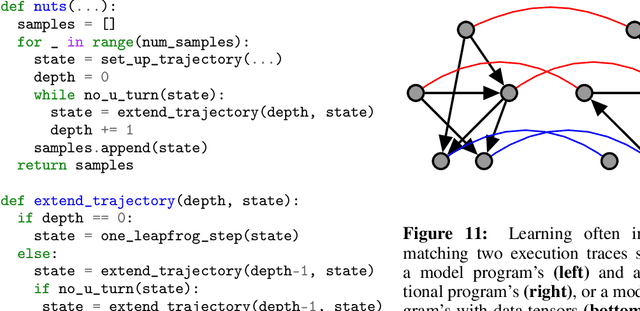
We describe a simple, low-level approach for embedding probabilistic programming in a deep learning ecosystem. In particular, we distill probabilistic programming down to a single abstraction---the random variable. Our lightweight implementation in TensorFlow enables numerous applications: a model-parallel variational auto-encoder (VAE) with 2nd-generation tensor processing units (TPUv2s); a data-parallel autoregressive model (Image Transformer) with TPUv2s; and multi-GPU No-U-Turn Sampler (NUTS). For both a state-of-the-art VAE on 64x64 ImageNet and Image Transformer on 256x256 CelebA-HQ, our approach achieves an optimal linear speedup from 1 to 256 TPUv2 chips. With NUTS, we see a 100x speedup on GPUs over Stan and 37x over PyMC3.
Aerial Spectral Super-Resolution using Conditional Adversarial Networks
Dec 23, 2017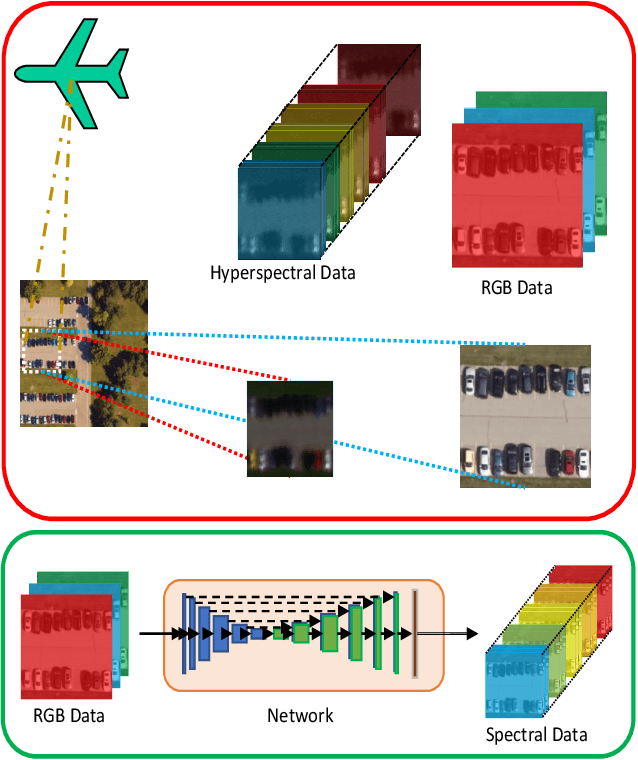
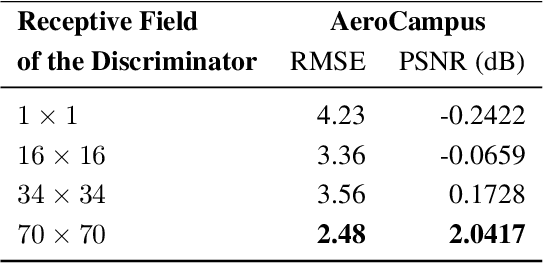

Inferring spectral signatures from ground based natural images has acquired a lot of interest in applied deep learning. In contrast to the spectra of ground based images, aerial spectral images have low spatial resolution and suffer from higher noise interference. In this paper, we train a conditional adversarial network to learn an inverse mapping from a trichromatic space to 31 spectral bands within 400 to 700 nm. The network is trained on AeroCampus, a first of its kind aerial hyperspectral dataset. AeroCampus consists of high spatial resolution color images and low spatial resolution hyperspectral images (HSI). Color images synthesized from 31 spectral bands are used to train our network. With a baseline root mean square error of 2.48 on the synthesized RGB test data, we show that it is possible to generate spectral signatures in aerial imagery.
Latent Constraints: Learning to Generate Conditionally from Unconditional Generative Models
Dec 21, 2017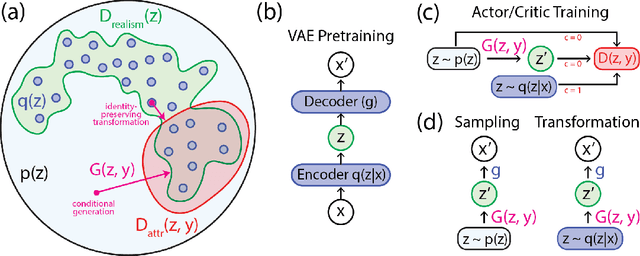
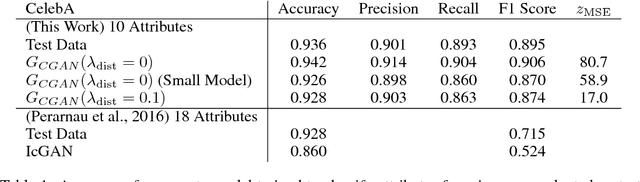

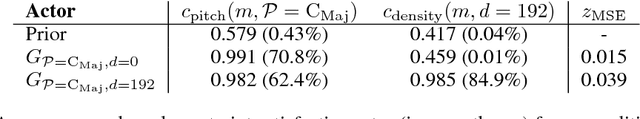
Deep generative neural networks have proven effective at both conditional and unconditional modeling of complex data distributions. Conditional generation enables interactive control, but creating new controls often requires expensive retraining. In this paper, we develop a method to condition generation without retraining the model. By post-hoc learning latent constraints, value functions that identify regions in latent space that generate outputs with desired attributes, we can conditionally sample from these regions with gradient-based optimization or amortized actor functions. Combining attribute constraints with a universal "realism" constraint, which enforces similarity to the data distribution, we generate realistic conditional images from an unconditional variational autoencoder. Further, using gradient-based optimization, we demonstrate identity-preserving transformations that make the minimal adjustment in latent space to modify the attributes of an image. Finally, with discrete sequences of musical notes, we demonstrate zero-shot conditional generation, learning latent constraints in the absence of labeled data or a differentiable reward function. Code with dedicated cloud instance has been made publicly available (https://goo.gl/STGMGx).