 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Segmentation with Active Semi-Supervised Representation Learning
Paper and Code
Oct 16, 2022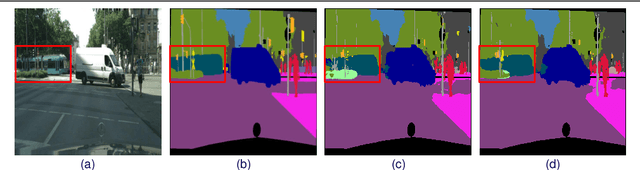
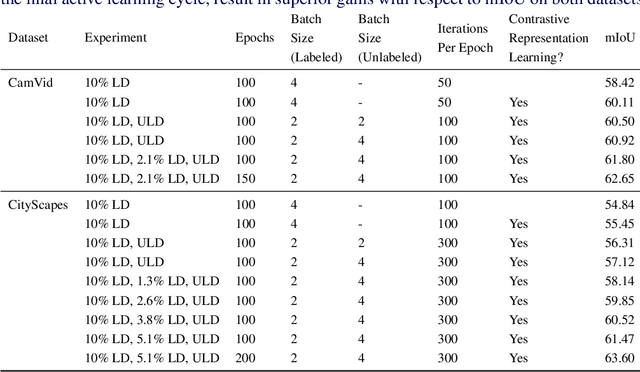
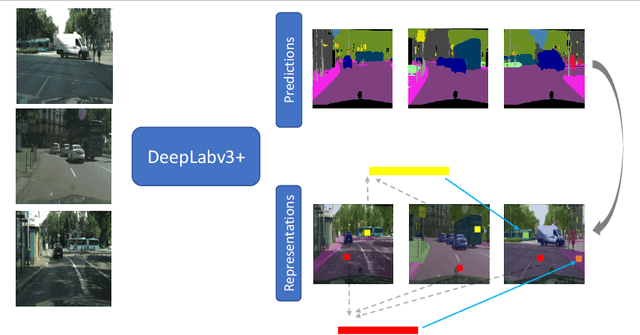
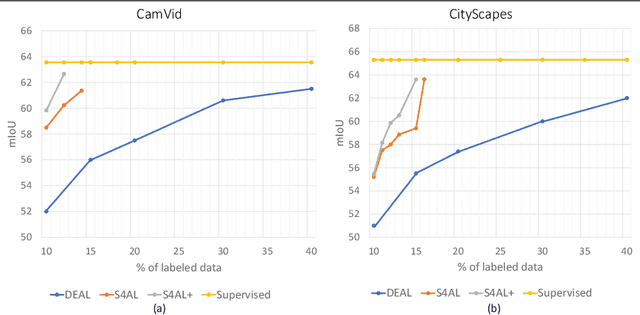
Obtaining human per-pixel labels for semantic segmentation is incredibly laborious, often making labeled dataset construction prohibitively expensive. Here, we endeavor to overcome this problem with a novel algorithm that combines semi-supervised and active learning, resulting in the ability to train an effective semantic segmentation algorithm with significantly lesser labeled data. To do this, we extend the prior state-of-the-art S4AL algorithm by replacing its mean teacher approach for semi-supervised learning with a self-training approach that improves learning with noisy labels. We further boost the neural network's ability to query useful data by adding a contrastive learning head, which leads to better understanding of the objects in the scene, and hence, better queries for active learning. We evaluate our method on CamVid and CityScapes datasets, the de-facto standards for active learning for semantic segmentation. We achieve more than 95% of the network's performance on CamVid and CityScapes datasets, utilizing only 12.1% and 15.1% of the labeled data, respectively. We also benchmark our method across existing stand-alone semi-supervised learning methods on the CityScapes dataset and achieve superior performance without any bells or whistles.