 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Inverse Graphics via Probabilistic Inference
Feb 02, 2024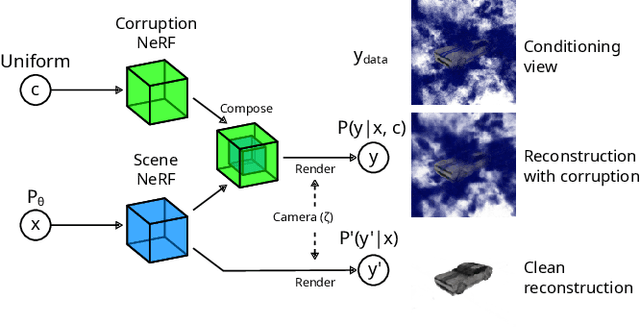
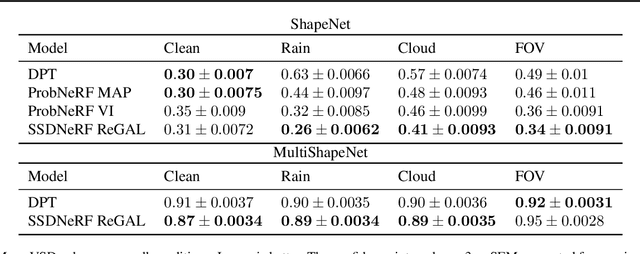

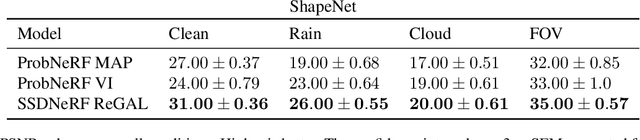
How do we infer a 3D scene from a single image in the presence of corruptions like rain, snow or fog? Straightforward domain randomization relies on knowing the family of corruptions ahead of time. Here, we propose a Bayesian approach-dubbed robust inverse graphics (RIG)-that relies on a strong scene prior and an uninformative uniform corruption prior, making it applicable to a wide range of corruptions. Given a single image, RIG performs posterior inference jointly over the scene and the corruption. We demonstrate this idea by training a neural radiance field (NeRF) scene prior and using a secondary NeRF to represent the corruptions over which we place an uninformative prior. RIG, trained only on clean data, outperforms depth estimators and alternative NeRF approaches that perform point estimation instead of full inference. The results hold for a number of scene prior architectures based on normalizing flows and diffusion models. For the latter, we develop reconstruction-guidance with auxiliary latents (ReGAL)-a diffusion conditioning algorithm that is applicable in the presence of auxiliary latent variables such as the corruption. RIG demonstrates how scene priors can be used beyond generation tasks.
Training Chain-of-Thought via Latent-Variable Inference
Nov 28, 2023
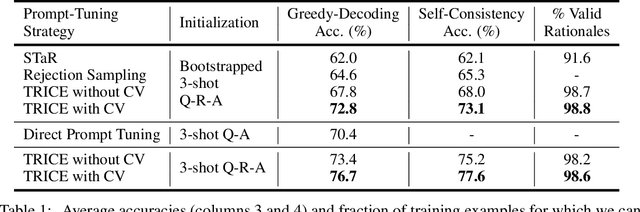
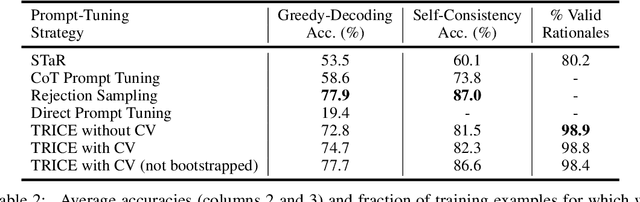
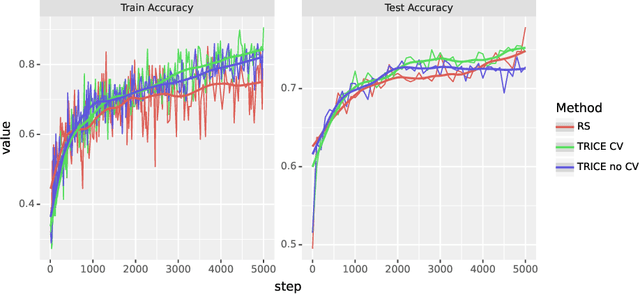
Large language models (LLMs) solve problems more accurately and interpretably when instructed to work out the answer step by step using a ``chain-of-thought'' (CoT) prompt. One can also improve LLMs' performance on a specific task by supervised fine-tuning, i.e., by using gradient ascent on some tunable parameters to maximize the average log-likelihood of correct answers from a labeled training set. Naively combining CoT with supervised tuning requires supervision not just of the correct answers, but also of detailed rationales that lead to those answers; these rationales are expensive to produce by hand. Instead, we propose a fine-tuning strategy that tries to maximize the \emph{marginal} log-likelihood of generating a correct answer using CoT prompting, approximately averaging over all possible rationales. The core challenge is sampling from the posterior over rationales conditioned on the correct answer; we address it using a simple Markov-chain Monte Carlo (MCMC) expectation-maximization (EM) algorithm inspired by the self-taught reasoner (STaR), memoized wake-sleep, Markovian score climbing, and persistent contrastive divergence. This algorithm also admits a novel control-variate technique that drives the variance of our gradient estimates to zero as the model improves. Applying our technique to GSM8K and the tasks in BIG-Bench Hard, we find that this MCMC-EM fine-tuning technique typically improves the model's accuracy on held-out examples more than STaR or prompt-tuning with or without CoT.
ProbNeRF: Uncertainty-Aware Inference of 3D Shapes from 2D Images
Oct 27, 2022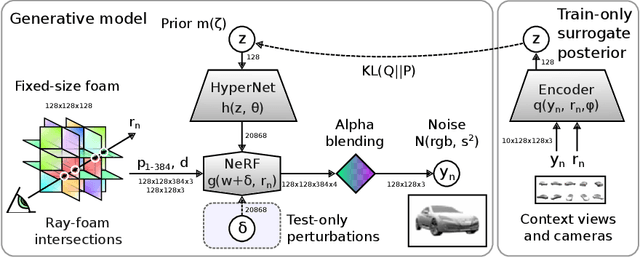

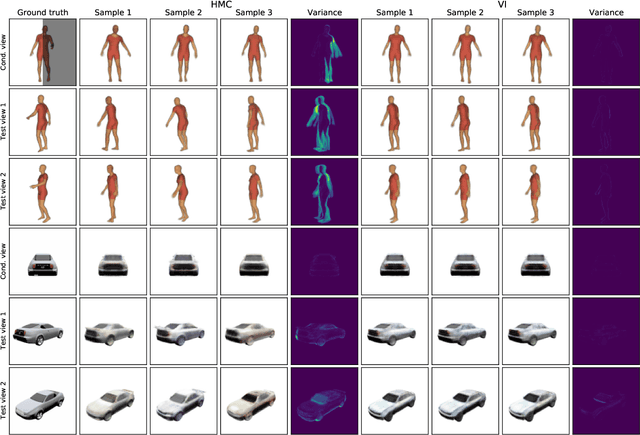
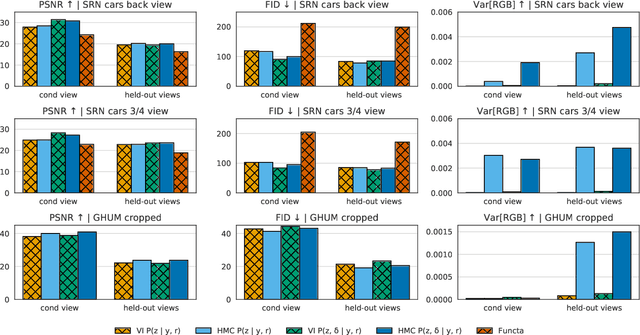
The problem of inferring object shape from a single 2D image is underconstrained. Prior knowledge about what objects are plausible can help, but even given such prior knowledge there may still be uncertainty about the shapes of occluded parts of objects. Recently, conditional neural radiance field (NeRF) models have been developed that can learn to infer good point estimates of 3D models from single 2D images. The problem of inferring uncertainty estimates for these models has received less attention. In this work, we propose probabilistic NeRF (ProbNeRF), a model and inference strategy for learning probabilistic generative models of 3D objects' shapes and appearances, and for doing posterior inference to recover those properties from 2D images. ProbNeRF is trained as a variational autoencoder, but at test time we use Hamiltonian Monte Carlo (HMC) for inference. Given one or a few 2D images of an object (which may be partially occluded), ProbNeRF is able not only to accurately model the parts it sees, but also to propose realistic and diverse hypotheses about the parts it does not see. We show that key to the success of ProbNeRF are (i) a deterministic rendering scheme, (ii) an annealed-HMC strategy, (iii) a hypernetwork-based decoder architecture, and (iv) doing inference over a full set of NeRF weights, rather than just a low-dimensional code.
Learning Energy-based Model with Flow-based Backbone by Neural Transport MCMC
Jun 12, 2020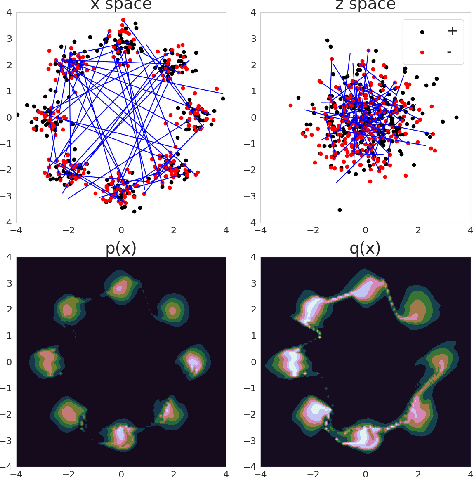
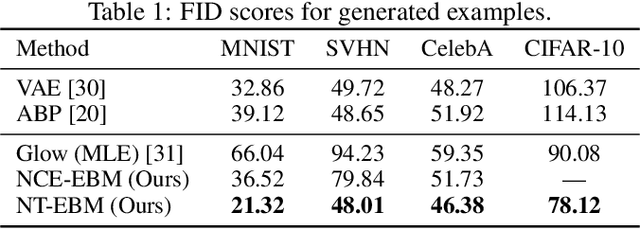
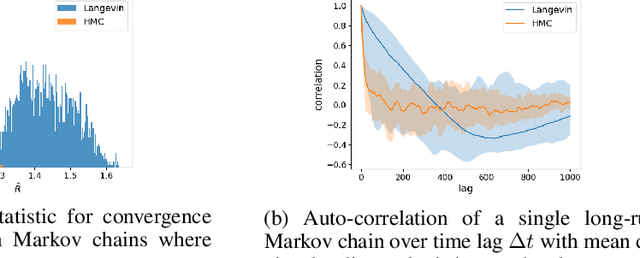

Learning energy-based model (EBM) requires MCMC sampling of the learned model as the inner loop of the learning algorithm. However, MCMC sampling of EBM in data space is generally not mixing, because the energy function, which is usually parametrized by deep network, is highly multi-modal in the data space. This is a serious handicap for both the theory and practice of EBM. In this paper, we propose to learn EBM with a flow-based model serving as a backbone, so that the EBM is a correction or an exponential tilting of the flow-based model. We show that the model has a particularly simple form in the space of the latent variables of the flow-based model, and MCMC sampling of the EBM in the latent space, which is a simple special case of neural transport MCMC, mixes well and traverses modes in the data space. This enables proper sampling and learning of EBM.
tfp.mcmc: Modern Markov Chain Monte Carlo Tools Built for Modern Hardware
Feb 04, 2020Markov chain Monte Carlo (MCMC) is widely regarded as one of the most important algorithms of the 20th century. Its guarantees of asymptotic convergence, stability, and estimator-variance bounds using only unnormalized probability functions make it indispensable to probabilistic programming. In this paper, we introduce the TensorFlow Probability MCMC toolkit, and discuss some of the considerations that motivated its design.
NeuTra-lizing Bad Geometry in Hamiltonian Monte Carlo Using Neural Transport
Mar 09, 2019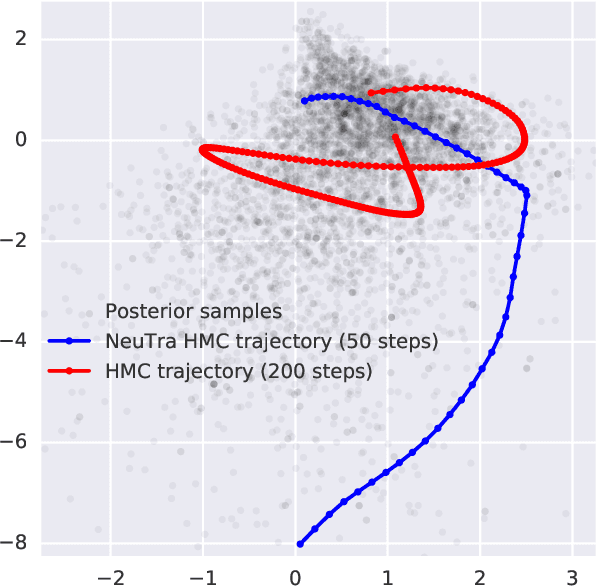

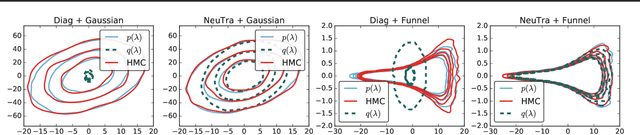
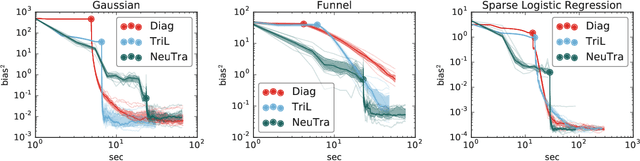
Hamiltonian Monte Carlo is a powerful algorithm for sampling from difficult-to-normalize posterior distributions. However, when the geometry of the posterior is unfavorable, it may take many expensive evaluations of the target distribution and its gradient to converge and mix. We propose neural transport (NeuTra) HMC, a technique for learning to correct this sort of unfavorable geometry using inverse autoregressive flows (IAF), a powerful neural variational inference technique. The IAF is trained to minimize the KL divergence from an isotropic Gaussian to the warped posterior, and then HMC sampling is performed in the warped space. We evaluate NeuTra HMC on a variety of synthetic and real problems, and find that it significantly outperforms vanilla HMC both in time to reach the stationary distribution and asymptotic effective-sample-size rates.
Length bias in Encoder Decoder Models and a Case for Global Conditioning
Sep 21, 2016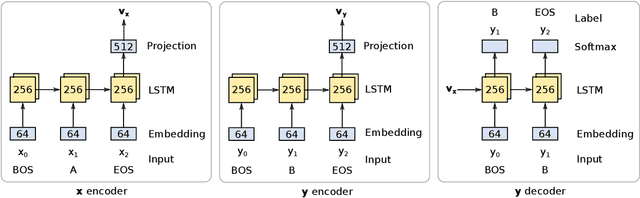
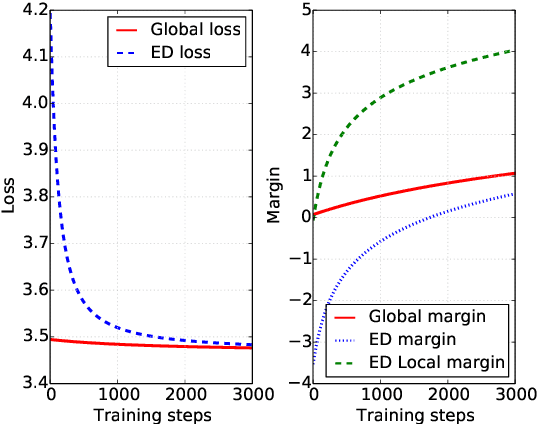
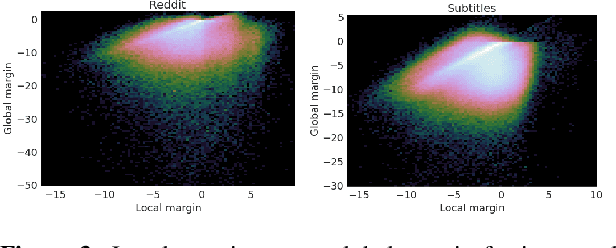
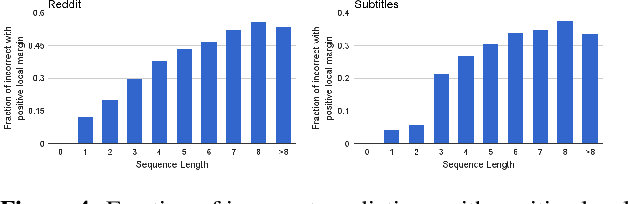
Encoder-decoder networks are popular for modeling sequences probabilistically in many applications. These models use the power of the Long Short-Term Memory (LSTM) architecture to capture the full dependence among variables, unlike earlier models like CRFs that typically assumed conditional independence among non-adjacent variables. However in practice encoder-decoder models exhibit a bias towards short sequences that surprisingly gets worse with increasing beam size. In this paper we show that such phenomenon is due to a discrepancy between the full sequence margin and the per-element margin enforced by the locally conditioned training objective of a encoder-decoder model. The discrepancy more adversely impacts long sequences, explaining the bias towards predicting short sequences. For the case where the predicted sequences come from a closed set, we show that a globally conditioned model alleviates the above problems of encoder-decoder models. From a practical point of view, our proposed model also eliminates the need for a beam-search during inference, which reduces to an efficient dot-product based search in a vector-space.