 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Language Outlines for Code: Literate Programming in the LLM Era
Aug 09, 2024



We propose using natural language outlines as a novel modality and interaction surface for providing AI assistance to developers throughout the software development process. An NL outline for a code function comprises multiple statements written in concise prose, which partition the code and summarize its main ideas in the style of literate programming. Crucially, we find that modern LLMs can generate accurate and high-quality NL outlines in practice. Moreover, NL outlines enable a bidirectional sync between code and NL, allowing changes in one to be automatically reflected in the other. We discuss many use cases for NL outlines: they can accelerate understanding and navigation of code and diffs, simplify code maintenance, augment code search, steer code generation, and more. We then propose and compare multiple LLM prompting techniques for generating outlines and ask professional developers to judge outline quality. Finally, we present two case studies applying NL outlines toward code review and the difficult task of malware detection.
NExT: Teaching Large Language Models to Reason about Code Execution
Apr 23, 2024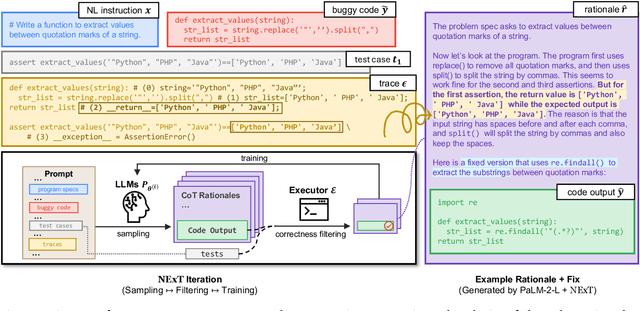



A fundamental skill among human developers is the ability to understand and reason about program execution. As an example, a programmer can mentally simulate code execution in natural language to debug and repair code (aka. rubber duck debugging). However, large language models (LLMs) of code are typically trained on the surface textual form of programs, thus may lack a semantic understanding of how programs execute at run-time. To address this issue, we propose NExT, a method to teach LLMs to inspect the execution traces of programs (variable states of executed lines) and reason about their run-time behavior through chain-of-thought (CoT) rationales. Specifically, NExT uses self-training to bootstrap a synthetic training set of execution-aware rationales that lead to correct task solutions (e.g., fixed programs) without laborious manual annotation. Experiments on program repair tasks based on MBPP and HumanEval demonstrate that NExT improves the fix rate of a PaLM 2 model, by 26.1% and 14.3% absolute, respectively, with significantly improved rationale quality as verified by automated metrics and human raters. Our model can also generalize to scenarios where program traces are absent at test-time.
Universal Self-Consistency for Large Language Model Generation
Nov 29, 2023



Self-consistency with chain-of-thought prompting (CoT) has demonstrated remarkable performance gains on various challenging tasks, by utilizing multiple reasoning paths sampled from large language models (LLMs). However, self-consistency relies on the answer extraction process to aggregate multiple solutions, which is not applicable to free-form answers. In this work, we propose Universal Self-Consistency (USC), which leverages LLMs themselves to select the most consistent answer among multiple candidates. We evaluate USC on a variety of benchmarks, including mathematical reasoning, code generation, long-context summarization, and open-ended question answering. On open-ended generation tasks where the original self-consistency method is not applicable, USC effectively utilizes multiple samples and improves the performance. For mathematical reasoning, USC matches the standard self-consistency performance without requiring the answer formats to be similar. Finally, without access to execution results, USC also matches the execution-based voting performance on code generation.
Training Chain-of-Thought via Latent-Variable Inference
Nov 28, 2023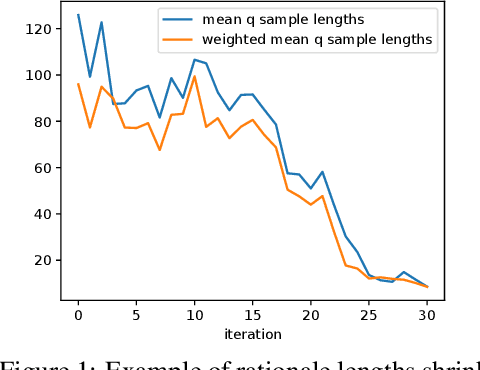
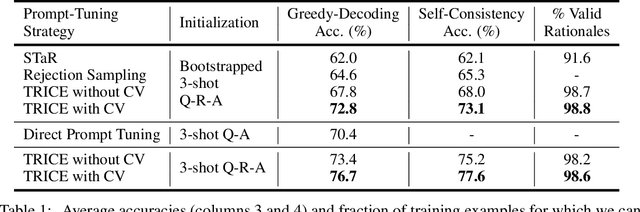
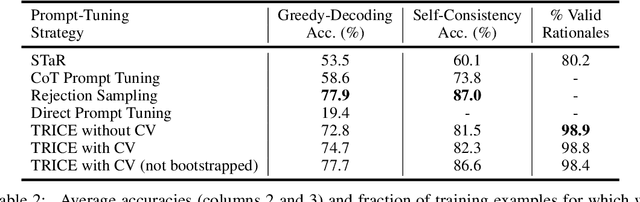
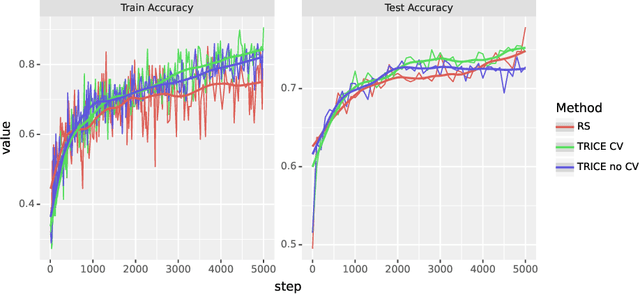
Large language models (LLMs) solve problems more accurately and interpretably when instructed to work out the answer step by step using a ``chain-of-thought'' (CoT) prompt. One can also improve LLMs' performance on a specific task by supervised fine-tuning, i.e., by using gradient ascent on some tunable parameters to maximize the average log-likelihood of correct answers from a labeled training set. Naively combining CoT with supervised tuning requires supervision not just of the correct answers, but also of detailed rationales that lead to those answers; these rationales are expensive to produce by hand. Instead, we propose a fine-tuning strategy that tries to maximize the \emph{marginal} log-likelihood of generating a correct answer using CoT prompting, approximately averaging over all possible rationales. The core challenge is sampling from the posterior over rationales conditioned on the correct answer; we address it using a simple Markov-chain Monte Carlo (MCMC) expectation-maximization (EM) algorithm inspired by the self-taught reasoner (STaR), memoized wake-sleep, Markovian score climbing, and persistent contrastive divergence. This algorithm also admits a novel control-variate technique that drives the variance of our gradient estimates to zero as the model improves. Applying our technique to GSM8K and the tasks in BIG-Bench Hard, we find that this MCMC-EM fine-tuning technique typically improves the model's accuracy on held-out examples more than STaR or prompt-tuning with or without CoT.
ExeDec: Execution Decomposition for Compositional Generalization in Neural Program Synthesis
Jul 26, 2023When writing programs, people have the ability to tackle a new complex task by decomposing it into smaller and more familiar subtasks. While it is difficult to measure whether neural program synthesis methods have similar capabilities, we can measure whether they compositionally generalize, that is, whether a model that has been trained on the simpler subtasks is subsequently able to solve more complex tasks. In this paper, we characterize several different forms of compositional generalization that are desirable in program synthesis, forming a meta-benchmark which we use to create generalization tasks for two popular datasets, RobustFill and DeepCoder. We then propose ExeDec, a novel decomposition-based synthesis strategy that predicts execution subgoals to solve problems step-by-step informed by program execution at each step. ExeDec has better synthesis performance and greatly improved compositional generalization ability compared to baselines.
A Probabilistic Framework for Modular Continual Learning
Jun 11, 2023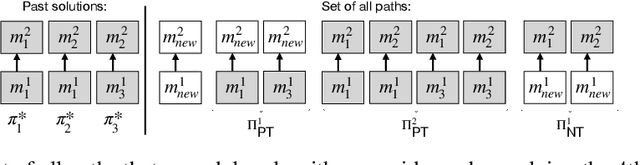
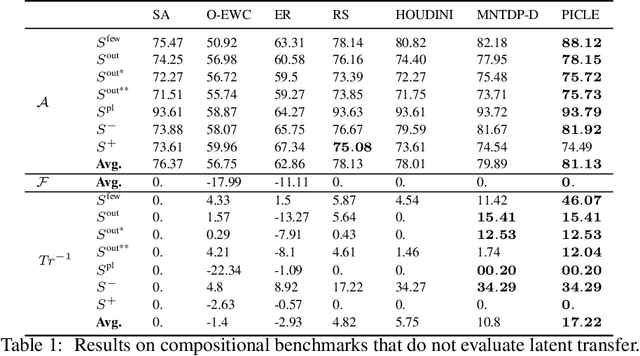

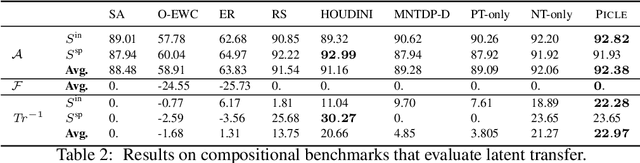
Modular approaches, which use a different composition of modules for each problem and avoid forgetting by design, have been shown to be a promising direction in continual learning (CL). However, searching through the large, discrete space of possible module compositions is a challenge because evaluating a composition's performance requires a round of neural network training. To address this challenge, we develop a modular CL framework, called PICLE, that accelerates search by using a probabilistic model to cheaply compute the fitness of each composition. The model combines prior knowledge about good module compositions with dataset-specific information. Its use is complemented by splitting up the search space into subsets, such as perceptual and latent subsets. We show that PICLE is the first modular CL algorithm to achieve different types of transfer while scaling to large search spaces. We evaluate it on two benchmark suites designed to capture different desiderata of CL techniques. On these benchmarks, PICLE offers significantly better performance than state-of-the-art CL baselines.
LambdaBeam: Neural Program Search with Higher-Order Functions and Lambdas
Jun 03, 2023Search is an important technique in program synthesis that allows for adaptive strategies such as focusing on particular search directions based on execution results. Several prior works have demonstrated that neural models are effective at guiding program synthesis searches. However, a common drawback of those approaches is the inability to handle iterative loops, higher-order functions, or lambda functions, thus limiting prior neural searches from synthesizing longer and more general programs. We address this gap by designing a search algorithm called LambdaBeam that can construct arbitrary lambda functions that compose operations within a given DSL. We create semantic vector representations of the execution behavior of the lambda functions and train a neural policy network to choose which lambdas to construct during search, and pass them as arguments to higher-order functions to perform looping computations. Our experiments show that LambdaBeam outperforms neural, symbolic, and LLM-based techniques in an integer list manipulation domain.
Natural Language to Code Generation in Interactive Data Science Notebooks
Dec 19, 2022



Computational notebooks, such as Jupyter notebooks, are interactive computing environments that are ubiquitous among data scientists to perform data wrangling and analytic tasks. To measure the performance of AI pair programmers that automatically synthesize programs for those tasks given natural language (NL) intents from users, we build ARCADE, a benchmark of 1082 code generation problems using the pandas data analysis framework in data science notebooks. ARCADE features multiple rounds of NL-to-code problems from the same notebook. It requires a model to understand rich multi-modal contexts, such as existing notebook cells and their execution states as well as previous turns of interaction. To establish a strong baseline on this challenging task, we develop PaChiNCo, a 62B code language model (LM) for Python computational notebooks, which significantly outperforms public code LMs. Finally, we explore few-shot prompting strategies to elicit better code with step-by-step decomposition and NL explanation, showing the potential to improve the diversity and explainability of model predictions.
A Library for Representing Python Programs as Graphs for Machine Learning
Aug 15, 2022



Graph representations of programs are commonly a central element of machine learning for code research. We introduce an open source Python library python_graphs that applies static analysis to construct graph representations of Python programs suitable for training machine learning models. Our library admits the construction of control-flow graphs, data-flow graphs, and composite ``program graphs'' that combine control-flow, data-flow, syntactic, and lexical information about a program. We present the capabilities and limitations of the library, perform a case study applying the library to millions of competitive programming submissions, and showcase the library's utility for machine learning research.
Language Model Cascades
Jul 28, 2022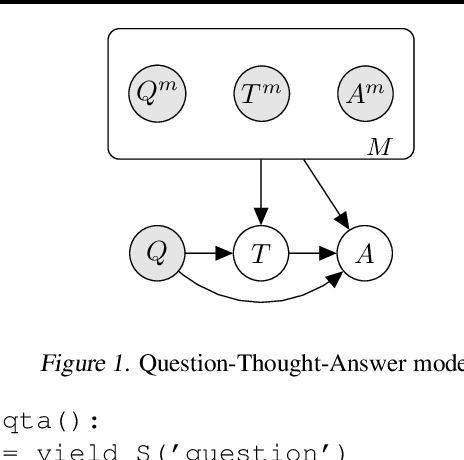
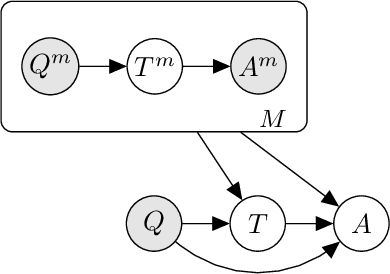
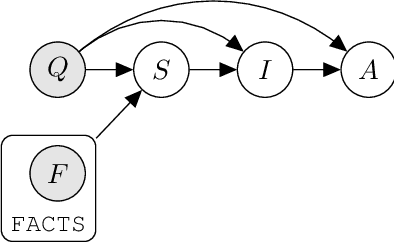
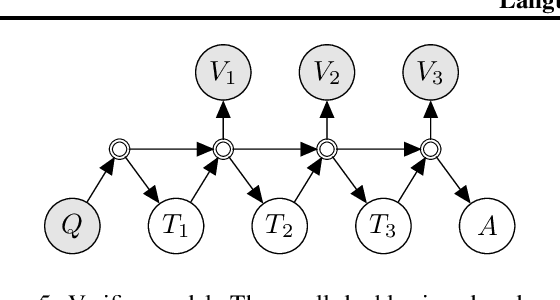
Prompted models have demonstrated impressive few-shot learning abilities. Repeated interactions at test-time with a single model, or the composition of multiple models together, further expands capabilities. These compositions are probabilistic models, and may be expressed in the language of graphical models with random variables whose values are complex data types such as strings. Cases with control flow and dynamic structure require techniques from probabilistic programming, which allow implementing disparate model structures and inference strategies in a unified language. We formalize several existing techniques from this perspective, including scratchpads / chain of thought, verifiers, STaR, selection-inference, and tool use. We refer to the resulting programs as language model cascades.