 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompting LLMs for Code Editing: Struggles and Remedies
Apr 28, 2025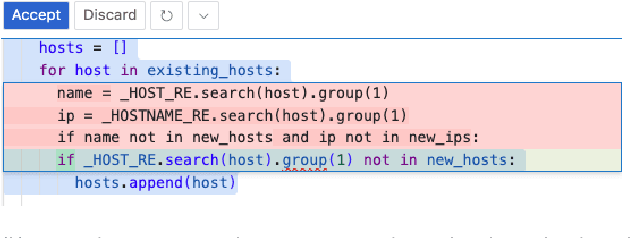

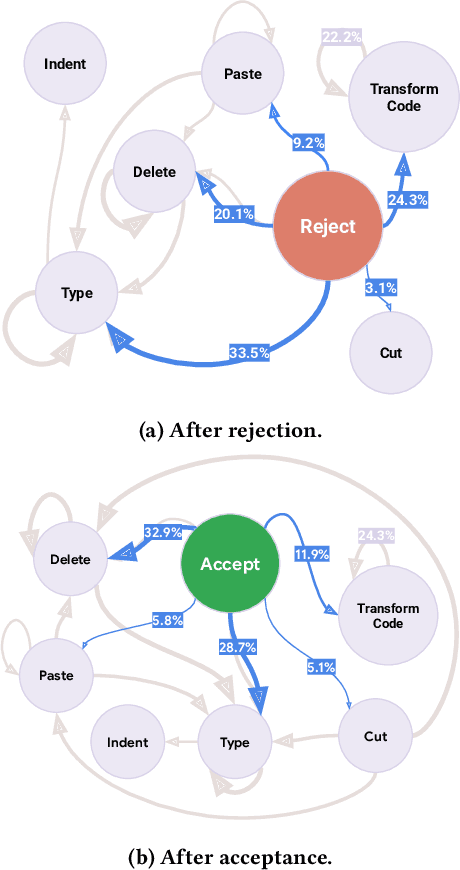

Large Language Models (LLMs) are rapidly transforming software engineering, with coding assistants embedded in an IDE becoming increasingly prevalent. While research has focused on improving the tools and understanding developer perceptions, a critical gap exists in understanding how developers actually use these tools in their daily workflows, and, crucially, where they struggle. This paper addresses part of this gap through a multi-phased investigation of developer interactions with an LLM-powered code editing and transformation feature, Transform Code, in an IDE widely used at Google. First, we analyze telemetry logs of the feature usage, revealing that frequent re-prompting can be an indicator of developer struggles with using Transform Code. Second, we conduct a qualitative analysis of unsatisfactory requests, identifying five key categories of information often missing from developer prompts. Finally, based on these findings, we propose and evaluate a tool, AutoPrompter, for automatically improving prompts by inferring missing information from the surrounding code context, leading to a 27% improvement in edit correctness on our test set.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
In-IDE Generation-based Information Support with a Large Language Model
Jul 17, 2023Developers often face challenges in code understanding, which is crucial for building and maintaining high-quality software systems. Code comments and documentation can provide some context for the code, but are often scarce or missing. This challenge has become even more pressing with the rise of large language model (LLM) based code generation tools. To understand unfamiliar code, most software developers rely on general-purpose search engines to search through various programming information resources, which often requires multiple iterations of query rewriting and information foraging. More recently, developers have turned to online chatbots powered by LLMs, such as ChatGPT, which can provide more customized responses but also incur more overhead as developers need to communicate a significant amount of context to the LLM via a textual interface. In this study, we provide the investigation of an LLM-based conversational UI in the IDE. We aim to understand the promises and obstacles for tools powered by LLMs that are contextually aware, in that they automatically leverage the developer's programming context to answer queries. To this end, we develop an IDE Plugin that allows users to query back-ends such as OpenAI's GPT-3.5 and GPT-4 with high-level requests, like: explaining a highlighted section of code, explaining key domain-specific terms, or providing usage examples for an API. We conduct an exploratory user study with 32 participants to understand the usefulness and effectiveness, as well as individual preferences in the usage of, this LLM-powered information support tool. The study confirms that this approach can aid code understanding more effectively than web search, but the degree of the benefit differed by participants' experience levels.
A Library for Representing Python Programs as Graphs for Machine Learning
Aug 15, 2022



Graph representations of programs are commonly a central element of machine learning for code research. We introduce an open source Python library python_graphs that applies static analysis to construct graph representations of Python programs suitable for training machine learning models. Our library admits the construction of control-flow graphs, data-flow graphs, and composite ``program graphs'' that combine control-flow, data-flow, syntactic, and lexical information about a program. We present the capabilities and limitations of the library, perform a case study applying the library to millions of competitive programming submissions, and showcase the library's utility for machine learning research.