 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrashFixer: A crash resolution agent for the Linux kernel
Apr 29, 2025

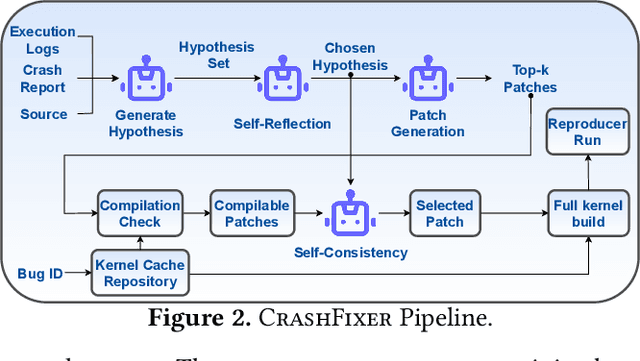
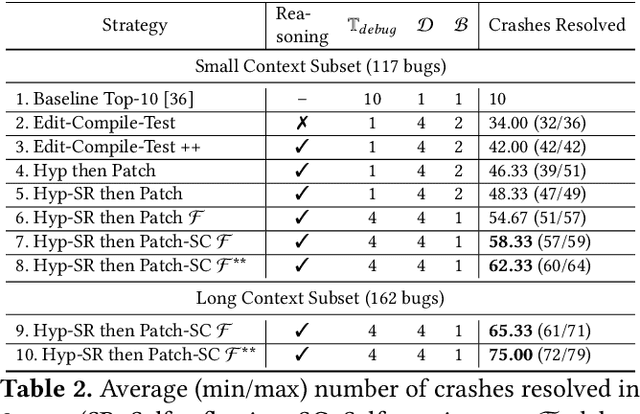
Code large language models (LLMs) have shown impressive capabilities on a multitude of software engineering tasks. In particular, they have demonstrated remarkable utility in the task of code repair. However, common benchmarks used to evaluate the performance of code LLMs are often limited to small-scale settings. In this work, we build upon kGym, which shares a benchmark for system-level Linux kernel bugs and a platform to run experiments on the Linux kernel. This paper introduces CrashFixer, the first LLM-based software repair agent that is applicable to Linux kernel bugs. Inspired by the typical workflow of a kernel developer, we identify the key capabilities an expert developer leverages to resolve a kernel crash. Using this as our guide, we revisit the kGym platform and identify key system improvements needed to practically run LLM-based agents at the scale of the Linux kernel (50K files and 20M lines of code). We implement these changes by extending kGym to create an improved platform - called kGymSuite, which will be open-sourced. Finally, the paper presents an evaluation of various repair strategies for such complex kernel bugs and showcases the value of explicitly generating a hypothesis before attempting to fix bugs in complex systems such as the Linux kernel. We also evaluated CrashFixer's capabilities on still open bugs, and found at least two patch suggestions considered plausible to resolve the reported bug.
AI-Assisted Assessment of Coding Practices in Modern Code Review
May 22, 2024



Modern code review is a process in which an incremental code contribution made by a code author is reviewed by one or more peers before it is committed to the version control system. An important element of modern code review is verifying that code contributions adhere to best practices. While some of these best practices can be automatically verified, verifying others is commonly left to human reviewers. This paper reports on the development, deployment, and evaluation of AutoCommenter, a system backed by a large language model that automatically learns and enforces coding best practices. We implemented AutoCommenter for four programming languages (C++, Java, Python, and Go) and evaluated its performance and adoption in a large industrial setting. Our evaluation shows that an end-to-end system for learning and enforcing coding best practices is feasible and has a positive impact on the developer workflow. Additionally, this paper reports on the challenges associated with deploying such a system to tens of thousands of developers and the corresponding lessons learned.
Learning to Answer Semantic Queries over Code
Sep 17, 2022
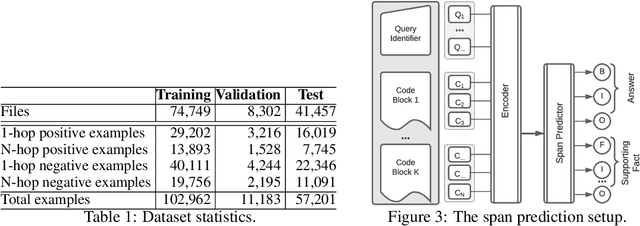
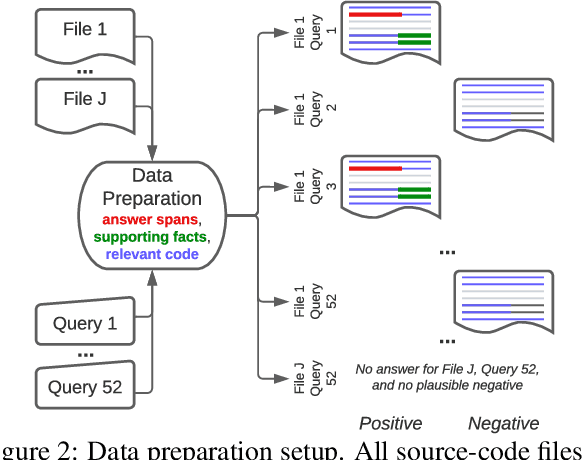

During software development, developers need answers to queries about semantic aspects of code. Even though extractive question-answering using neural approaches has been studied widely in natural languages, the problem of answering semantic queries over code using neural networks has not yet been explored. This is mainly because there is no existing dataset with extractive question and answer pairs over code involving complex concepts and long chains of reasoning. We bridge this gap by building a new, curated dataset called CodeQueries, and proposing a neural question-answering methodology over code. We build upon state-of-the-art pre-trained models of code to predict answer and supporting-fact spans. Given a query and code, only some of the code may be relevant to answer the query. We first experiment under an ideal setting where only the relevant code is given to the model and show that our models do well. We then experiment under three pragmatic considerations: (1) scaling to large-size code, (2) learning from a limited number of examples and (3) robustness to minor syntax errors in code. Our results show that while a neural model can be resilient to minor syntax errors in code, increasing size of code, presence of code that is not relevant to the query, and reduced number of training examples limit the model performance. We are releasing our data and models to facilitate future work on the proposed problem of answering semantic queries over code.
A Library for Representing Python Programs as Graphs for Machine Learning
Aug 15, 2022



Graph representations of programs are commonly a central element of machine learning for code research. We introduce an open source Python library python_graphs that applies static analysis to construct graph representations of Python programs suitable for training machine learning models. Our library admits the construction of control-flow graphs, data-flow graphs, and composite ``program graphs'' that combine control-flow, data-flow, syntactic, and lexical information about a program. We present the capabilities and limitations of the library, perform a case study applying the library to millions of competitive programming submissions, and showcase the library's utility for machine learning research.
SpreadsheetCoder: Formula Prediction from Semi-structured Context
Jun 26, 2021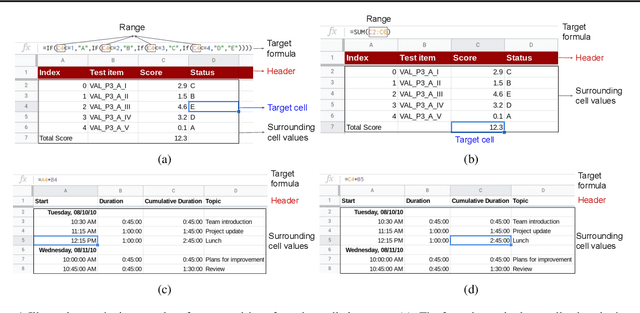
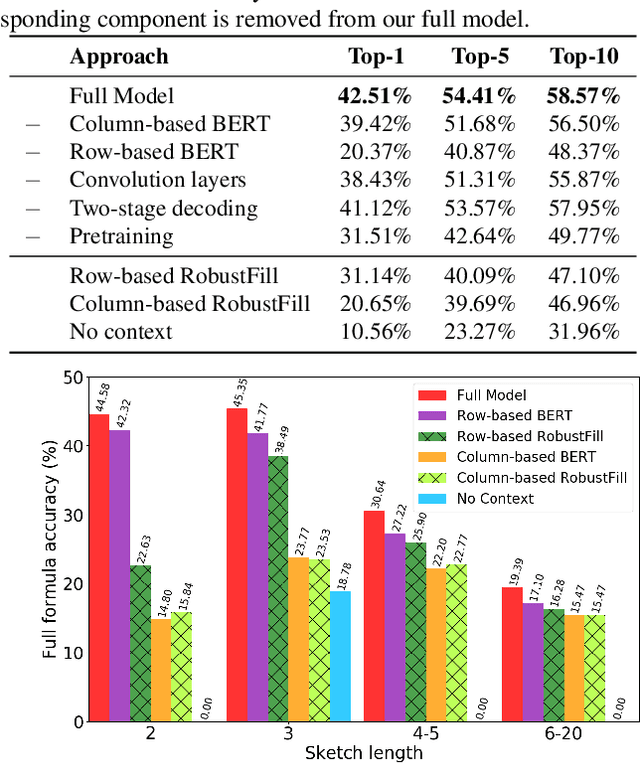

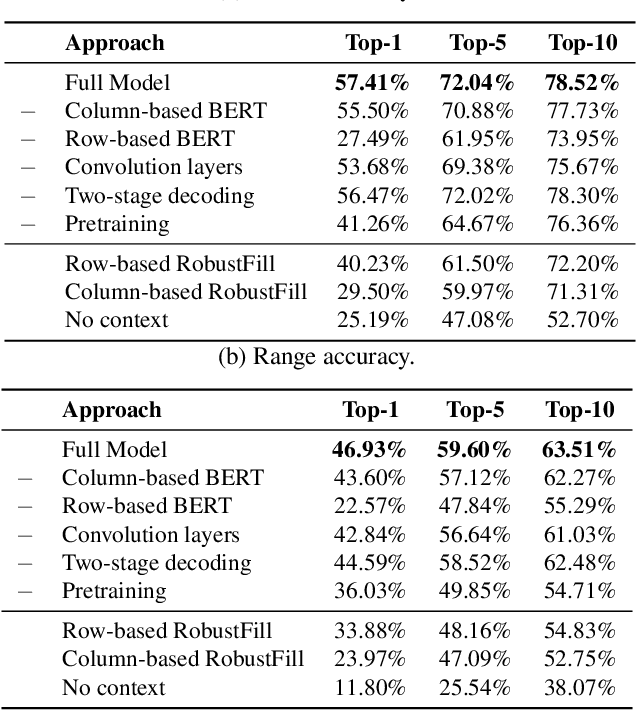
Spreadsheet formula prediction has been an important program synthesis problem with many real-world applications. Previous works typically utilize input-output examples as the specification for spreadsheet formula synthesis, where each input-output pair simulates a separate row in the spreadsheet. However, this formulation does not fully capture the rich context in real-world spreadsheets. First, spreadsheet data entries are organized as tables, thus rows and columns are not necessarily independent from each other. In addition, many spreadsheet tables include headers, which provide high-level descriptions of the cell data. However, previous synthesis approaches do not consider headers as part of the specification. In this work, we present the first approach for synthesizing spreadsheet formulas from tabular context, which includes both headers and semi-structured tabular data. In particular, we propose SpreadsheetCoder, a BERT-based model architecture to represent the tabular context in both row-based and column-based formats. We train our model on a large dataset of spreadsheets, and demonstrate that SpreadsheetCoder achieves top-1 prediction accuracy of 42.51%, which is a considerable improvement over baselines that do not employ rich tabular context. Compared to the rule-based system, SpreadsheetCoder assists 82% more users in composing formulas on Google Sheets.
Neural Program Synthesis with a Differentiable Fixer
Jun 19, 2020
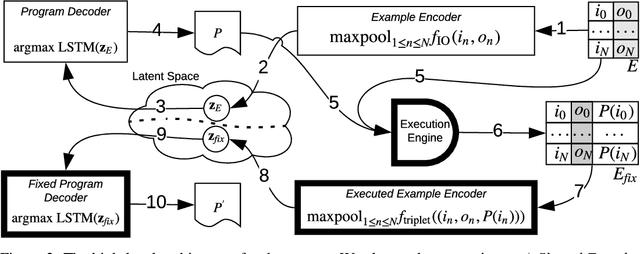
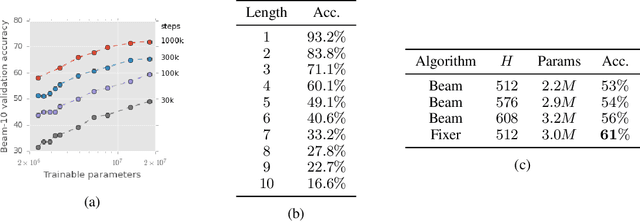
We present a new program synthesis approach that combines an encoder-decoder based synthesis architecture with a differentiable program fixer. Our approach is inspired from the fact that human developers seldom get their program correct on the first attempt, and perform iterative testing-based program fixing to get to the desired program functionality. Similarly, our approach first learns a distribution over programs conditioned on an encoding of a set of input-output examples, and then iteratively performs fix operations using the differentiable fixer. The fixer takes as input the original examples and the current program's outputs on example inputs, and generates a new distribution over the programs with the goal of reducing the discrepancies between the current program outputs and the desired example outputs. We train our architecture end-to-end on the RobustFill domain, and show that the addition of the fixer module leads to a significant improvement on synthesis accuracy compared to using beam search.
Pre-trained Contextual Embedding of Source Code
Dec 21, 2019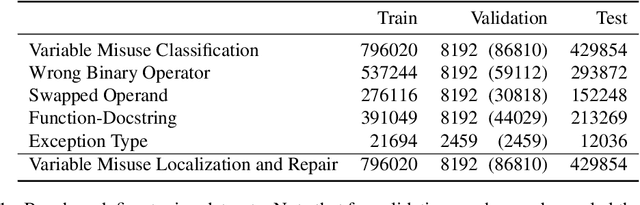
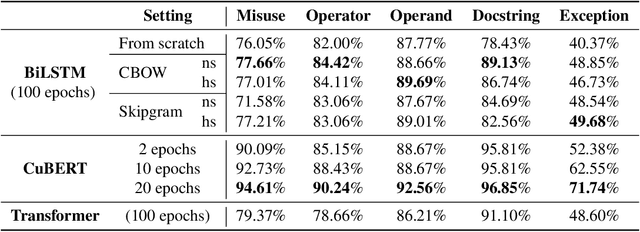

The source code of a program not only serves as a formal description of an executable task, but it also serves to communicate developer intent in a human-readable form. To facilitate this, developers use meaningful identifier names and natural-language documentation. This makes it possible to successfully apply sequence-modeling approaches, shown to be effective in natural-language processing, to source code. A major advancement in natural-language understanding has been the use of pre-trained token embeddings; BERT and other works have further shown that pre-trained contextual embeddings can be extremely powerful and can be fine-tuned effectively for a variety of downstream supervised tasks. Inspired by these developments, we present the first attempt to replicate this success on source code. We curate a massive corpus of Python programs from GitHub to pre-train a BERT model, which we call Code Understanding BERT (CuBERT). We also pre-train Word2Vec embeddings on the same dataset. We create a benchmark of five classification tasks and compare fine-tuned CuBERT against sequence models trained with and without the Word2Vec embeddings. Our results show that CuBERT outperforms the baseline methods by a margin of 2.9-22%. We also show its superiority when fine-tuned with smaller datasets, and over fewer epochs. We further evaluate CuBERT's effectiveness on a joint classification, localization and repair task involving prediction of two pointers.
Neural Program Repair by Jointly Learning to Localize and Repair
Apr 03, 2019
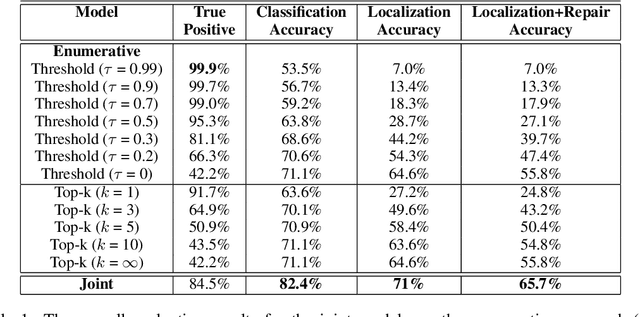
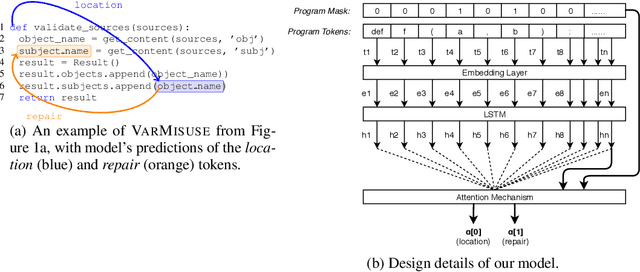

Due to its potential to improve programmer productivity and software quality, automated program repair has been an active topic of research. Newer techniques harness neural networks to learn directly from examples of buggy programs and their fixes. In this work, we consider a recently identified class of bugs called variable-misuse bugs. The state-of-the-art solution for variable misuse enumerates potential fixes for all possible bug locations in a program, before selecting the best prediction. We show that it is beneficial to train a model that jointly and directly localizes and repairs variable-misuse bugs. We present multi-headed pointer networks for this purpose, with one head each for localization and repair. The experimental results show that the joint model significantly outperforms an enumerative solution that uses a pointer based model for repair alone.
Mantis: Predicting System Performance through Program Analysis and Modeling
Sep 30, 2010

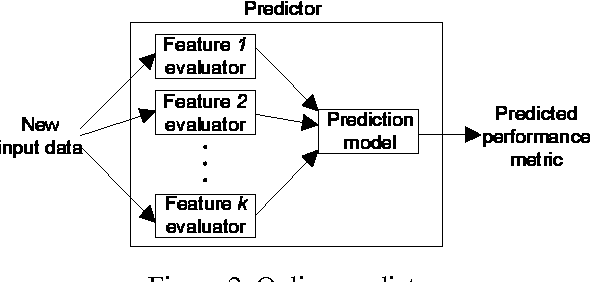
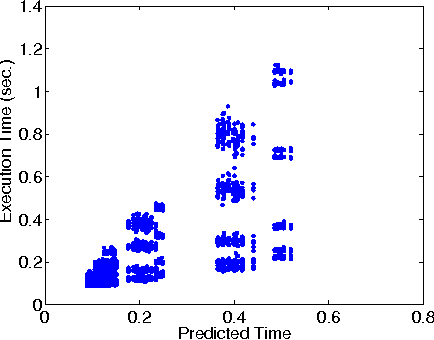
We present Mantis, a new framework that automatically predicts program performance with high accuracy. Mantis integrates techniques from programming language and machine learning for performance modeling, and is a radical departure from traditional approaches. Mantis extracts program features, which are information about program execution runs, through program instrumentation. It uses machine learning techniques to select features relevant to performance and creates prediction models as a function of the selected features. Through program analysis, it then generates compact code slices that compute these feature values for prediction. Our evaluation shows that Mantis can achieve more than 93% accuracy with less than 10% training data set, which is a significant improvement over models that are oblivious to program features. The system generates code slices that are cheap to compute feature values.