 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting LLM-Generated Spam Reviews by Integrating Language Model Embeddings and Graph Neural Network
Oct 02, 2025The rise of large language models (LLMs) has enabled the generation of highly persuasive spam reviews that closely mimic human writing. These reviews pose significant challenges for existing detection systems and threaten the credibility of online platforms. In this work, we first create three realistic LLM-generated spam review datasets using three distinct LLMs, each guided by product metadata and genuine reference reviews. Evaluations by GPT-4.1 confirm the high persuasion and deceptive potential of these reviews. To address this threat, we propose FraudSquad, a hybrid detection model that integrates text embeddings from a pre-trained language model with a gated graph transformer for spam node classification. FraudSquad captures both semantic and behavioral signals without relying on manual feature engineering or massive training resources. Experiments show that FraudSquad outperforms state-of-the-art baselines by up to 44.22% in precision and 43.01% in recall on three LLM-generated datasets, while also achieving promising results on two human-written spam datasets. Furthermore, FraudSquad maintains a modest model size and requires minimal labeled training data, making it a practical solution for real-world applications. Our contributions include new synthetic datasets, a practical detection framework, and empirical evidence highlighting the urgency of adapting spam detection to the LLM era. Our code and datasets are available at: https://anonymous.4open.science/r/FraudSquad-5389/.
A Foundation Model for Chest X-ray Interpretation with Grounded Reasoning via Online Reinforcement Learning
Sep 04, 2025Medical foundation models (FMs) have shown tremendous promise amid the rapid advancements in artificial intelligence (AI) technologies. However, current medical FMs typically generate answers in a black-box manner, lacking transparent reasoning processes and locally grounded interpretability, which hinders their practical clinical deployments. To this end, we introduce DeepMedix-R1, a holistic medical FM for chest X-ray (CXR) interpretation. It leverages a sequential training pipeline: initially fine-tuned on curated CXR instruction data to equip with fundamental CXR interpretation capabilities, then exposed to high-quality synthetic reasoning samples to enable cold-start reasoning, and finally refined via online reinforcement learning to enhance both grounded reasoning quality and generation performance. Thus, the model produces both an answer and reasoning steps tied to the image's local regions for each query. Quantitative evaluation demonstrates substantial improvements in report generation (e.g., 14.54% and 31.32% over LLaVA-Rad and MedGemma) and visual question answering (e.g., 57.75% and 23.06% over MedGemma and CheXagent) tasks. To facilitate robust assessment, we propose Report Arena, a benchmarking framework using advanced language models to evaluate answer quality, further highlighting the superiority of DeepMedix-R1. Expert review of generated reasoning steps reveals greater interpretability and clinical plausibility compared to the established Qwen2.5-VL-7B model (0.7416 vs. 0.2584 overall preference). Collectively, our work advances medical FM development toward holistic, transparent, and clinically actionable modeling for CXR interpretation.
Self-supervised Quantized Representation for Seamlessly Integrating Knowledge Graphs with Large Language Models
Jan 30, 2025



Due to the presence of the natural gap between Knowledge Graph (KG) structures and the natural language, the effective integration of holistic structural information of KGs with Large Language Models (LLMs) has emerged as a significant question. To this end, we propose a two-stage framework to learn and apply quantized codes for each entity, aiming for the seamless integration of KGs with LLMs. Firstly, a self-supervised quantized representation (SSQR) method is proposed to compress both KG structural and semantic knowledge into discrete codes (\ie, tokens) that align the format of language sentences. We further design KG instruction-following data by viewing these learned codes as features to directly input to LLMs, thereby achieving seamless integration. The experiment results demonstrate that SSQR outperforms existing unsupervised quantized methods, producing more distinguishable codes. Further, the fine-tuned LLaMA2 and LLaMA3.1 also have superior performance on KG link prediction and triple classification tasks, utilizing only 16 tokens per entity instead of thousands in conventional prompting methods.
EsurvFusion: An evidential multimodal survival fusion model based on Gaussian random fuzzy numbers
Dec 02, 2024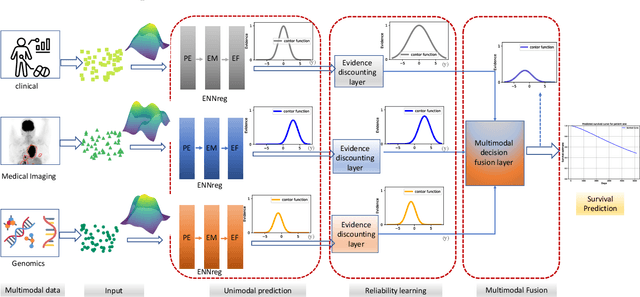
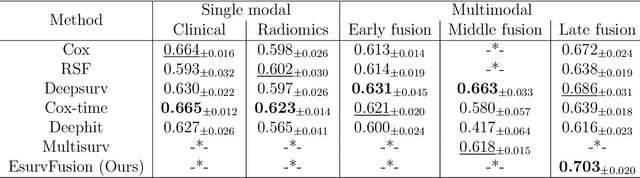
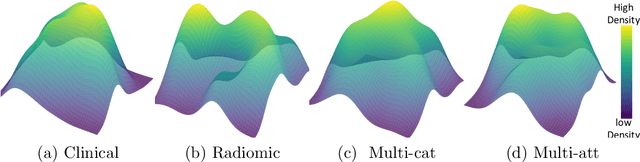
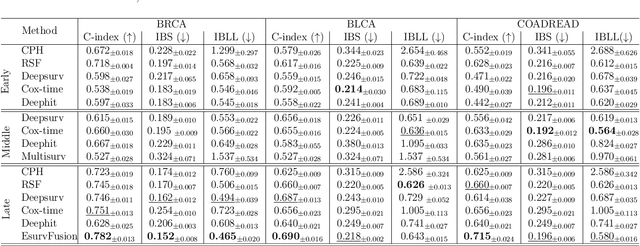
Multimodal survival analysis aims to combine heterogeneous data sources (e.g., clinical, imaging, text, genomics) to improve the prediction quality of survival outcomes. However, this task is particularly challenging due to high heterogeneity and noise across data sources, which vary in structure, distribution, and context. Additionally, the ground truth is often censored (uncertain) due to incomplete follow-up data. In this paper, we propose a novel evidential multimodal survival fusion model, EsurvFusion, designed to combine multimodal data at the decision level through an evidence-based decision fusion layer that jointly addresses both data and model uncertainty while incorporating modality-level reliability. Specifically, EsurvFusion first models unimodal data with newly introduced Gaussian random fuzzy numbers, producing unimodal survival predictions along with corresponding aleatoric and epistemic uncertainties. It then estimates modality-level reliability through a reliability discounting layer to correct the misleading impact of noisy data modalities. Finally, a multimodal evidence-based fusion layer is introduced to combine the discounted predictions to form a unified, interpretable multimodal survival analysis model, revealing each modality's influence based on the learned reliability coefficients. This is the first work that studies multimodal survival analysis with both uncertainty and reliability. Extensive experiments on four multimodal survival datasets demonstrate the effectiveness of our model in handling high heterogeneity data, establishing new state-of-the-art on several benchmarks.
Evidential time-to-event prediction model with well-calibrated uncertainty estimation
Nov 12, 2024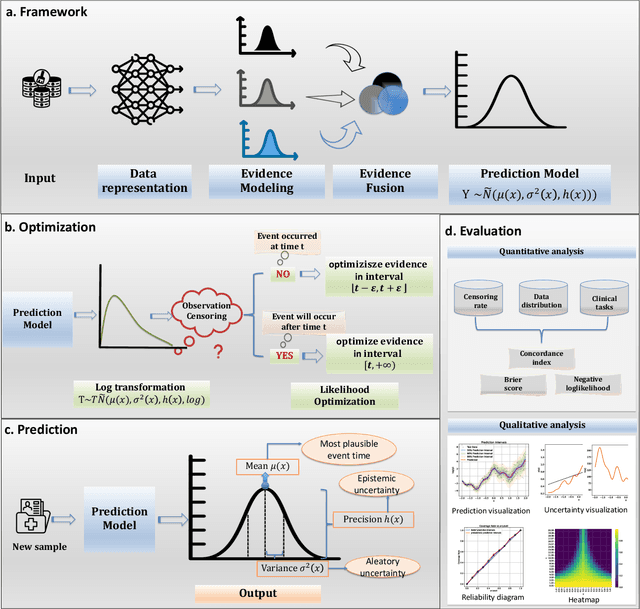

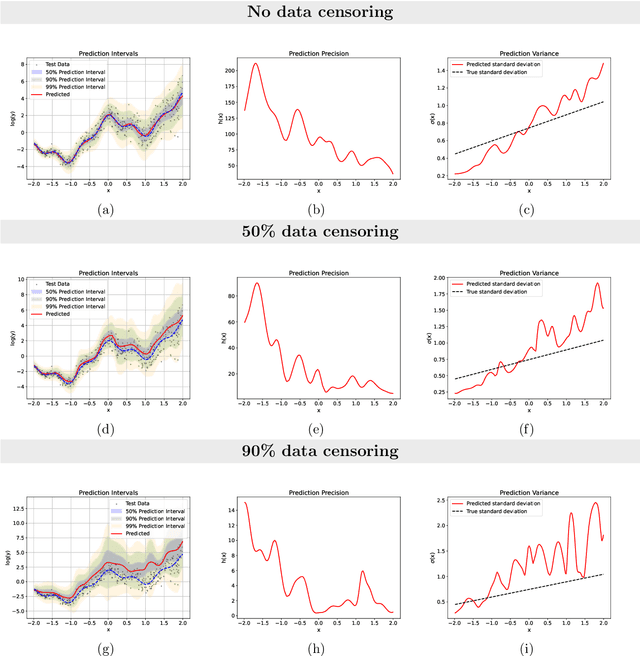
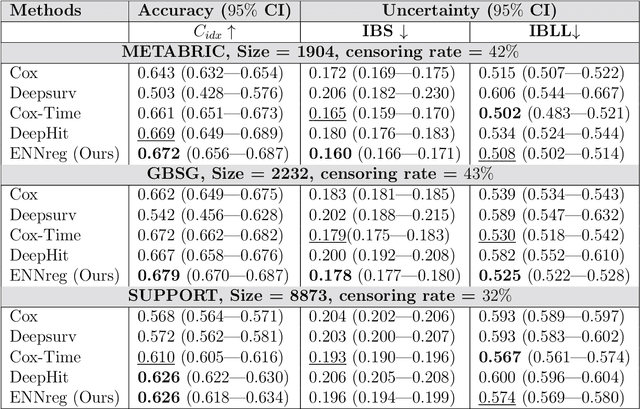
Time-to-event analysis, or Survival analysis, provides valuable insights into clinical prognosis and treatment recommendations. However, this task is typically more challenging than other regression tasks due to the censored observations. Moreover, concerns regarding the reliability of predictions persist among clinicians, mainly attributed to the absence of confidence assessment, robustness, and calibration of prediction. To address those challenges, we introduce an evidential regression model designed especially for time-to-event prediction tasks, with which the most plausible event time, is directly quantified by aggregated Gaussian random fuzzy numbers (GRFNs). The GRFNs are a newly introduced family of random fuzzy subsets of the real line that generalizes both Gaussian random variables and Gaussian possibility distributions. Different from conventional methods that construct models based on strict data distribution, e.g., proportional hazard function, our model only assumes the event time is encoded in a real line GFRN without any strict distribution assumption, therefore offering more flexibility in complex data scenarios. Furthermore, the epistemic and aleatory uncertainty regarding the event time is quantified within the aggregated GRFN as well. Our model can, therefore, provide more detailed clinical decision-making guidance with two more degrees of information. The model is fit by minimizing a generalized negative log-likelihood function that accounts for data censoring based on uncertainty evidence reasoning. Experimental results on simulated datasets with varying data distributions and censoring scenarios, as well as on real-world datasets across diverse clinical settings and tasks, demonstrate that our model achieves both accurate and reliable performance, outperforming state-of-the-art methods.
Camouflaged_Object_Tracking__A_Benchmark
Aug 25, 2024



Visual tracking has seen remarkable advancements, largely driven by the availability of large-scale training datasets that have enabled the development of highly accurate and robust algorithms. While significant progress has been made in tracking general objects, research on more challenging scenarios, such as tracking camouflaged objects, remains limited. Camouflaged objects, which blend seamlessly with their surroundings or other objects, present unique challenges for detection and tracking in complex environments. This challenge is particularly critical in applications such as military, security, agriculture, and marine monitoring, where precise tracking of camouflaged objects is essential. To address this gap, we introduce the Camouflaged Object Tracking Dataset (COTD), a specialized benchmark designed specifically for evaluating camouflaged object tracking methods. The COTD dataset comprises 200 sequences and approximately 80,000 frames, each annotated with detailed bounding boxes. Our evaluation of 20 existing tracking algorithms reveals significant deficiencies in their performance with camouflaged objects. To address these issues, we propose a novel tracking framework, HiPTrack-MLS, which demonstrates promising results in improving tracking performance for camouflaged objects. COTD and code are avialable at https://github.com/openat25/HIPTrack-MLS.
Has Multimodal Learning Delivered Universal Intelligence in Healthcare? A Comprehensive Survey
Aug 23, 2024


The rapid development of artificial intelligence has constantly reshaped the field of intelligent healthcare and medicine. As a vital technology, multimodal learning has increasingly garnered interest due to data complementarity, comprehensive modeling form, and great application potential. Currently, numerous researchers are dedicating their attention to this field, conducting extensive studies and constructing abundant intelligent systems. Naturally, an open question arises that has multimodal learning delivered universal intelligence in healthcare? To answer the question, we adopt three unique viewpoints for a holistic analysis. Firstly, we conduct a comprehensive survey of the current progress of medical multimodal learning from the perspectives of datasets, task-oriented methods, and universal foundation models. Based on them, we further discuss the proposed question from five issues to explore the real impacts of advanced techniques in healthcare, from data and technologies to performance and ethics. The answer is that current technologies have NOT achieved universal intelligence and there remains a significant journey to undertake. Finally, in light of the above reviews and discussions, we point out ten potential directions for exploration towards the goal of universal intelligence in healthcare.
Tracking Reflected Objects: A Benchmark
Jul 07, 2024

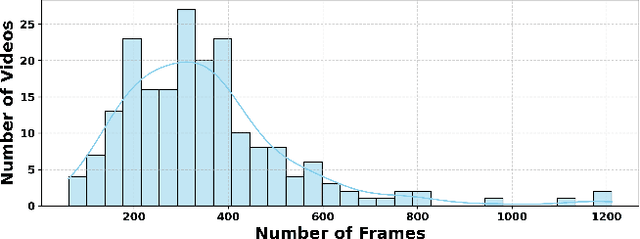
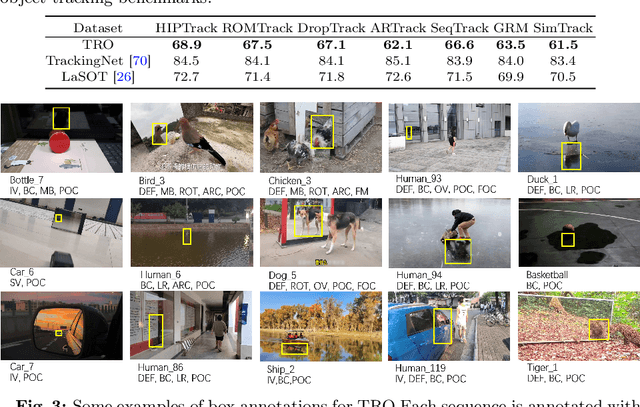
Visual tracking has advanced significantly in recent years, mainly due to the availability of large-scale training datasets. These datasets have enabled the development of numerous algorithms that can track objects with high accuracy and robustness.However, the majority of current research has been directed towards tracking generic objects, with less emphasis on more specialized and challenging scenarios. One such challenging scenario involves tracking reflected objects. Reflections can significantly distort the appearance of objects, creating ambiguous visual cues that complicate the tracking process. This issue is particularly pertinent in applications such as autonomous driving, security, smart homes, and industrial production, where accurately tracking objects reflected in surfaces like mirrors or glass is crucial. To address this gap, we introduce TRO, a benchmark specifically for Tracking Reflected Objects. TRO includes 200 sequences with around 70,000 frames, each carefully annotated with bounding boxes. This dataset aims to encourage the development of new, accurate methods for tracking reflected objects, which present unique challenges not sufficiently covered by existing benchmarks. We evaluated 20 state-of-the-art trackers and found that they struggle with the complexities of reflections. To provide a stronger baseline, we propose a new tracker, HiP-HaTrack, which uses hierarchical features to improve performance, significantly outperforming existing algorithms. We believe our benchmark, evaluation, and HiP-HaTrack will inspire further research and applications in tracking reflected objects. The TRO and code are available at https://github.com/OpenCodeGithub/HIP-HaTrack.
An evidential time-to-event prediction model based on Gaussian random fuzzy numbers
Jun 19, 2024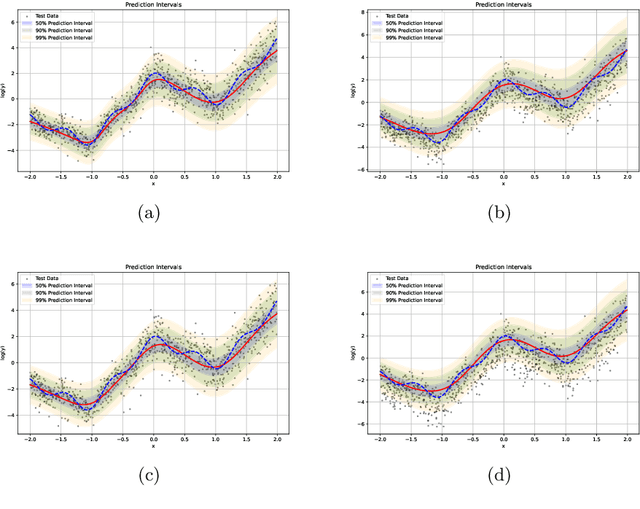

We introduce an evidential model for time-to-event prediction with censored data. In this model, uncertainty on event time is quantified by Gaussian random fuzzy numbers, a newly introduced family of random fuzzy subsets of the real line with associated belief functions, generalizing both Gaussian random variables and Gaussian possibility distributions. Our approach makes minimal assumptions about the underlying time-to-event distribution. The model is fit by minimizing a generalized negative log-likelihood function that accounts for both normal and censored data. Comparative experiments on two real-world datasets demonstrate the very good performance of our model as compared to the state-of-the-art.
A review of uncertainty quantification in medical image analysis: probabilistic and non-probabilistic methods
Oct 09, 2023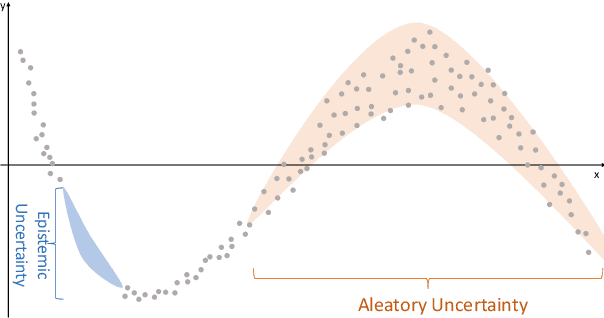
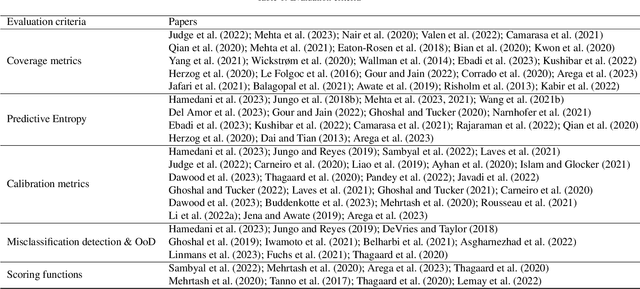
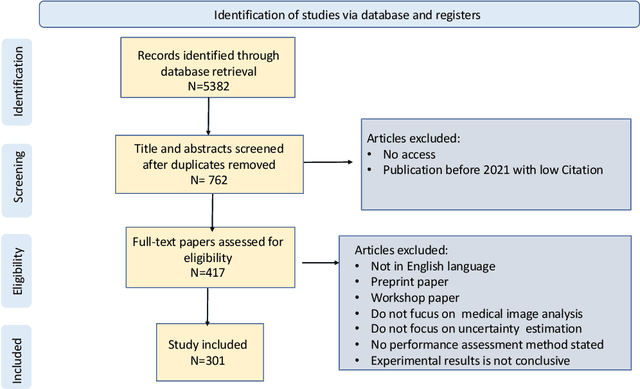
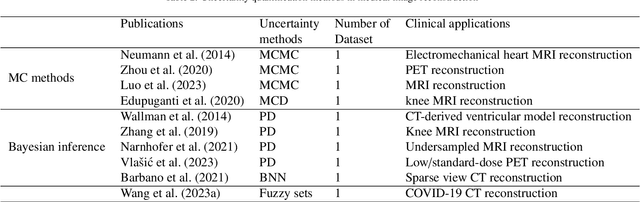
The comprehensive integration of machine learning healthcare models within clinical practice remains suboptimal, notwithstanding the proliferation of high-performing solutions reported in the literature. A predominant factor hindering widespread adoption pertains to an insufficiency of evidence affirming the reliability of the aforementioned models. Recently, uncertainty quantification methods have been proposed as a potential solution to quantify the reliability of machine learning models and thus increase the interpretability and acceptability of the result. In this review, we offer a comprehensive overview of prevailing methods proposed to quantify uncertainty inherent in machine learning models developed for various medical image tasks. Contrary to earlier reviews that exclusively focused on probabilistic methods, this review also explores non-probabilistic approaches, thereby furnishing a more holistic survey of research pertaining to uncertainty quantification for machine learning models. Analysis of medical images with the summary and discussion on medical applications and the corresponding uncertainty evaluation protocols are presented, which focus on the specific challenges of uncertainty in medical image analysis. We also highlight some potential future research work at the end. Generally, this review aims to allow researchers from both clinical and technical backgrounds to gain a quick and yet in-depth understanding of the research in uncertainty quantification for medical image analysis machine learning models.