 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Foundation Model for Chest X-ray Interpretation with Grounded Reasoning via Online Reinforcement Learning
Sep 04, 2025Medical foundation models (FMs) have shown tremendous promise amid the rapid advancements in artificial intelligence (AI) technologies. However, current medical FMs typically generate answers in a black-box manner, lacking transparent reasoning processes and locally grounded interpretability, which hinders their practical clinical deployments. To this end, we introduce DeepMedix-R1, a holistic medical FM for chest X-ray (CXR) interpretation. It leverages a sequential training pipeline: initially fine-tuned on curated CXR instruction data to equip with fundamental CXR interpretation capabilities, then exposed to high-quality synthetic reasoning samples to enable cold-start reasoning, and finally refined via online reinforcement learning to enhance both grounded reasoning quality and generation performance. Thus, the model produces both an answer and reasoning steps tied to the image's local regions for each query. Quantitative evaluation demonstrates substantial improvements in report generation (e.g., 14.54% and 31.32% over LLaVA-Rad and MedGemma) and visual question answering (e.g., 57.75% and 23.06% over MedGemma and CheXagent) tasks. To facilitate robust assessment, we propose Report Arena, a benchmarking framework using advanced language models to evaluate answer quality, further highlighting the superiority of DeepMedix-R1. Expert review of generated reasoning steps reveals greater interpretability and clinical plausibility compared to the established Qwen2.5-VL-7B model (0.7416 vs. 0.2584 overall preference). Collectively, our work advances medical FM development toward holistic, transparent, and clinically actionable modeling for CXR interpretation.
Self-supervised Quantized Representation for Seamlessly Integrating Knowledge Graphs with Large Language Models
Jan 30, 2025



Due to the presence of the natural gap between Knowledge Graph (KG) structures and the natural language, the effective integration of holistic structural information of KGs with Large Language Models (LLMs) has emerged as a significant question. To this end, we propose a two-stage framework to learn and apply quantized codes for each entity, aiming for the seamless integration of KGs with LLMs. Firstly, a self-supervised quantized representation (SSQR) method is proposed to compress both KG structural and semantic knowledge into discrete codes (\ie, tokens) that align the format of language sentences. We further design KG instruction-following data by viewing these learned codes as features to directly input to LLMs, thereby achieving seamless integration. The experiment results demonstrate that SSQR outperforms existing unsupervised quantized methods, producing more distinguishable codes. Further, the fine-tuned LLaMA2 and LLaMA3.1 also have superior performance on KG link prediction and triple classification tasks, utilizing only 16 tokens per entity instead of thousands in conventional prompting methods.
PathReasoner: Modeling Reasoning Path with Equivalent Extension for Logical Question Answering
May 29, 2024Logical reasoning task has attracted great interest since it was proposed. Faced with such a task, current competitive models, even large language models (e.g., ChatGPT and PaLM 2), still perform badly. Previous promising LMs struggle in logical consistency modeling and logical structure perception. To this end, we model the logical reasoning task by transforming each logical sample into reasoning paths and propose an architecture \textbf{PathReasoner}. It addresses the task from the views of both data and model. To expand the diversity of the logical samples, we propose an atom extension strategy supported by equivalent logical formulas, to form new reasoning paths. From the model perspective, we design a stack of transformer-style blocks. In particular, we propose a path-attention module to joint model in-atom and cross-atom relations with the high-order diffusion strategy. Experiments show that PathReasoner achieves competitive performances on two logical reasoning benchmarks and great generalization abilities.
Are Large Language Models Really Good Logical Reasoners? A Comprehensive Evaluation From Deductive, Inductive and Abductive Views
Jun 16, 2023Large Language Models (LLMs) have achieved great success in various natural language tasks. It has aroused much interest in evaluating the specific reasoning capability of LLMs, such as multilingual reasoning and mathematical reasoning. However, as one of the key reasoning perspectives, logical reasoning capability has not yet been thoroughly evaluated. In this work, we aim to bridge those gaps and provide comprehensive evaluations. Firstly, to offer systematic evaluations, this paper selects fifteen typical logical reasoning datasets and organizes them into deductive, inductive, abductive and mixed-form reasoning settings. Considering the comprehensiveness of evaluations, we include three representative LLMs (i.e., text-davinci-003, ChatGPT and BARD) and evaluate them on all selected datasets under zero-shot, one-shot and three-shot settings. Secondly, different from previous evaluations relying only on simple metrics (e.g., accuracy), we propose fine-level evaluations from objective and subjective manners, covering both answers and explanations. Also, to uncover the logical flaws of LLMs, bad cases will be attributed to five error types from two dimensions. Thirdly, to avoid the influences of knowledge bias and purely focus on benchmarking the logical reasoning capability of LLMs, we propose a new dataset with neutral content. It contains 3K samples and covers deductive, inductive and abductive reasoning settings. Based on the in-depth evaluations, this paper finally concludes the ability maps of logical reasoning capability from six dimensions (i.e., correct, rigorous, self-aware, active, oriented and no hallucination). It reflects the pros and cons of LLMs and gives guiding directions for future works.
Mind Reasoning Manners: Enhancing Type Perception for Generalized Zero-shot Logical Reasoning over Text
Jan 08, 2023



Logical reasoning task involves diverse types of complex reasoning over text, based on the form of multiple-choice question answering. Given the context, question and a set of options as the input, previous methods achieve superior performances on the full-data setting. However, the current benchmark dataset has the ideal assumption that the reasoning type distribution on the train split is close to the test split, which is inconsistent with many real application scenarios. To address it, there remain two problems to be studied: (1) How is the zero-shot capability of the models (train on seen types and test on unseen types)? (2) How to enhance the perception of reasoning types for the models? For problem 1, we propose a new benchmark for generalized zero-shot logical reasoning, named ZsLR. It includes six splits based on the three type sampling strategies. For problem 2, a type-aware model TaCo is proposed. It utilizes both the heuristic input reconstruction and the contrastive learning to improve the type perception in the global representation. Extensive experiments on both the zero-shot and full-data settings prove the superiority of TaCo over the state-of-the-art methods. Also, we experiment and verify the generalization capability of TaCo on other logical reasoning dataset.
MoCA: Incorporating Multi-stage Domain Pretraining and Cross-guided Multimodal Attention for Textbook Question Answering
Dec 06, 2021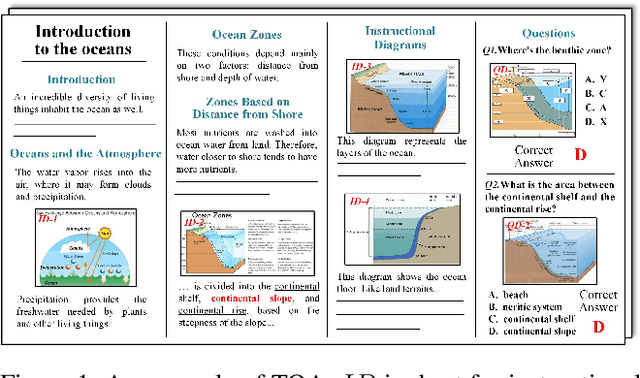

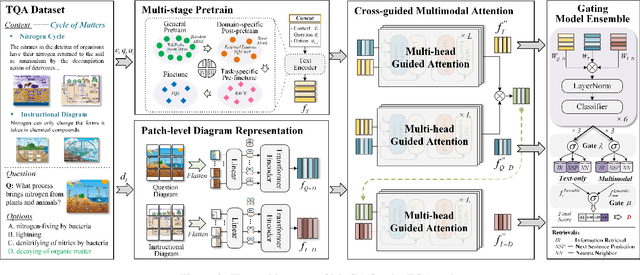
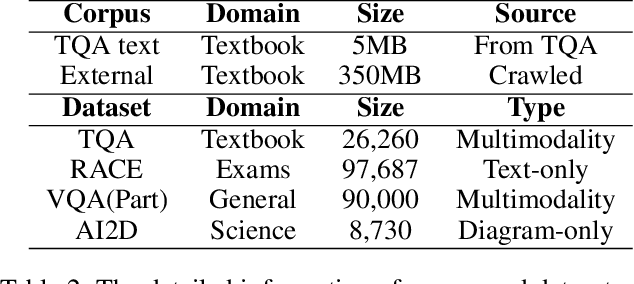
Textbook Question Answering (TQA) is a complex multimodal task to infer answers given large context descriptions and abundant diagrams. Compared with Visual Question Answering (VQA), TQA contains a large number of uncommon terminologies and various diagram inputs. It brings new challenges to the representation capability of language model for domain-specific spans. And it also pushes the multimodal fusion to a more complex level. To tackle the above issues, we propose a novel model named MoCA, which incorporates multi-stage domain pretraining and multimodal cross attention for the TQA task. Firstly, we introduce a multi-stage domain pretraining module to conduct unsupervised post-pretraining with the span mask strategy and supervised pre-finetune. Especially for domain post-pretraining, we propose a heuristic generation algorithm to employ the terminology corpus. Secondly, to fully consider the rich inputs of context and diagrams, we propose cross-guided multimodal attention to update the features of text, question diagram and instructional diagram based on a progressive strategy. Further, a dual gating mechanism is adopted to improve the model ensemble. The experimental results show the superiority of our model, which outperforms the state-of-the-art methods by 2.21% and 2.43% for validation and test split respectively.
Learning First-Order Rules with Relational Path Contrast for Inductive Relation Reasoning
Oct 17, 2021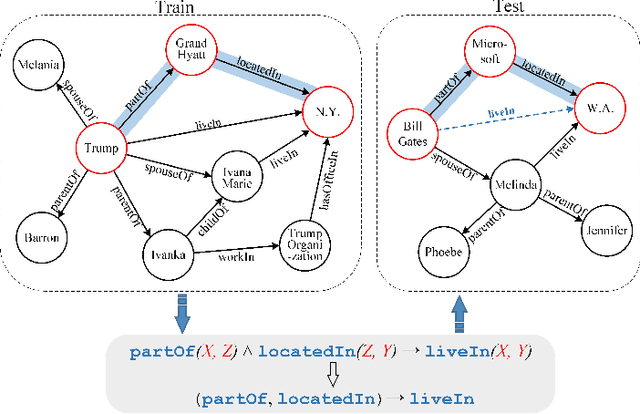
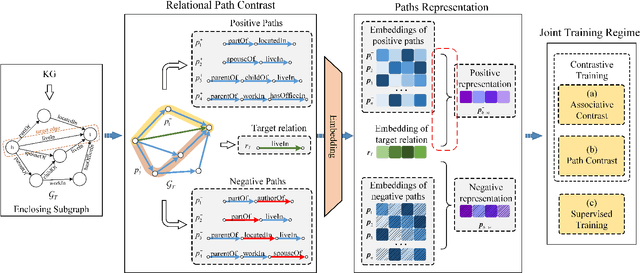
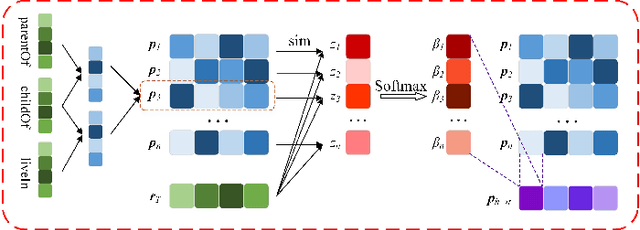
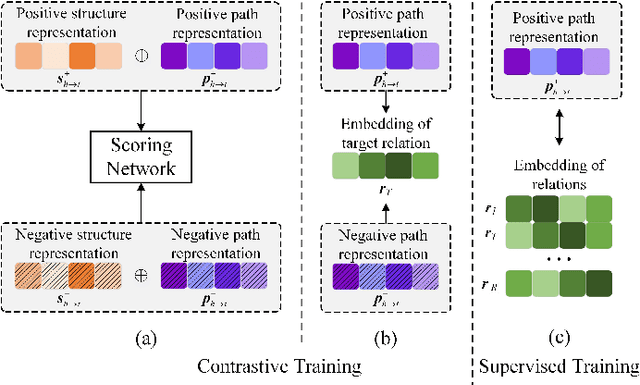
Relation reasoning in knowledge graphs (KGs) aims at predicting missing relations in incomplete triples, whereas the dominant paradigm is learning the embeddings of relations and entities, which is limited to a transductive setting and has restriction on processing unseen entities in an inductive situation. Previous inductive methods are scalable and consume less resource. They utilize the structure of entities and triples in subgraphs to own inductive ability. However, in order to obtain better reasoning results, the model should acquire entity-independent relational semantics in latent rules and solve the deficient supervision caused by scarcity of rules in subgraphs. To address these issues, we propose a novel graph convolutional network (GCN)-based approach for interpretable inductive reasoning with relational path contrast, named RPC-IR. RPC-IR firstly extracts relational paths between two entities and learns representations of them, and then innovatively introduces a contrastive strategy by constructing positive and negative relational paths. A joint training strategy considering both supervised and contrastive information is also proposed. Comprehensive experiments on three inductive datasets show that RPC-IR achieves outstanding performance comparing with the latest inductive reasoning methods and could explicitly represent logical rules for interpretability.